Andy May
In meinem letzten Beitrag [in deutscher Übersetzung hier] habe ich die NASA-CO2-Daten und die HadCRUT5-Daten von 1850 bis 2020 aufgezeichnet und verglichen. Damit reagierte ich auf eine von Robert Rohde auf Twitter gepostete Grafik, in der er behauptete, dass die beiden Daten gut korrelieren. Das scheint tatsächlich der Fall zu sein, denn das resultierende R² beträgt 0,87. Die verwendete Funktion der kleinsten Quadrate machte die globale Temperaturanomalie zu einer Funktion des Logarithmus zur Basis 2 der CO2-Konzentration (oder „log2CO2„). Das bedeutet, dass die Temperaturveränderung linear mit der Verdoppelung der CO2-Konzentration verläuft, eine gängige Annahme. Bei der Methode der kleinsten Quadrate (LS) wird davon ausgegangen, dass die Messungen der CO2-Konzentration fehlerfrei sind und alle aus der Korrelation resultierenden Fehler (die Residuen) in den HadCRUT5-Schätzungen der globalen durchschnittlichen Oberflächentemperatur enthalten sind.
In den Kommentaren zum vorherigen Beitrag wurde deutlich, dass einige Leser verstanden hatten, dass das berechnete R² (oft als Bestimmtheitsmaß bezeichnet) von LS künstlich aufgebläht wurde, weil sowohl X (log2CO2) als auch Y (HadCRUT5) autokorreliert sind und mit der Zeit zunehmen. Aber einige wenige haben diesen wichtigen Punkt nicht verstanden. Wie die meisten Investoren, Ingenieure und Geowissenschaftler wissen, haben zwei Zeitreihen, die beide autokorreliert sind und mit der Zeit zunehmen, fast immer ein überhöhtes R². Dies ist eine Form der „Scheinkorrelation“. Mit anderen Worten: Ein hohes R² bedeutet nicht unbedingt, dass die Variablen miteinander in Beziehung stehen. Die Autokorrelation ist in der Zeitreihenanalyse und in der Klimawissenschaft von großer Bedeutung, wird aber zu häufig ignoriert. Um eine Korrelation zwischen CO2 und HadCRUT5 zu beurteilen, müssen wir nach Autokorrelationseffekten suchen. Das am häufigsten verwendete Instrument ist die Durbin-Watson-Statistik.
Die Durbin-Watson-Statistik testet die Nullhypothese, dass die Residuen aus einer LS-Regression nicht autokorreliert sind, gegen die Alternative, dass sie es sind. Die Statistik ist eine Zahl zwischen 0 und 4. Ein Wert von 2 bedeutet, dass keine Autokorrelation vorliegt, ein Wert < 2 deutet auf eine positive Autokorrelation und ein Wert > 2 auf eine negative Autokorrelation hin. Da bei der Berechnung von R2 davon ausgegangen wird, dass jede Beobachtung unabhängig von den anderen ist, hoffen wir, dass wir einen Wert von 2 erhalten, so dass das R² gültig ist. Wenn die Regressionsresiduen autokorreliert und nicht zufällig, d. h. normal um den Mittelwert verteilt sind, ist R² ungültig und zu hoch. In dem Statistikprogramm R wird dies – unter Verwendung einer linearen Anpassung – mit nur einer Anweisung durchgeführt, wie unten gezeigt:
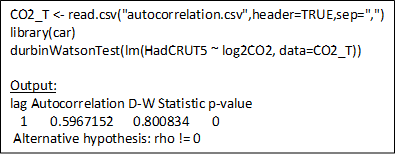
R-Code für einen grundlegenden R-DW-Test
Dieses R-Programm liest die HadCRUT5-Anomalien und die in Abbildung 1 dargestellten log2CO2-Werte von 1850-2020 ein, lädt dann die R-Bibliothek, die die Funktion Durbin-Watson-Test enthält, und führt die Funktion aus. Ich übergebe der Funktion nur ein Argument, nämlich die Ausgabe der R-Funktion für lineare Regression lm. In diesem Fall bitten wir lm, eine lineare Anpassung von HadCRUT5 als eine Funktion von log2CO2 zu berechnen. Die Funktion Durbin-Watson (DW) liest die Ausgabe von lm und berechnet die DW-Statistik von 0,8 aus den Residuen der linearen Anpassung, indem sie diese mit sich selbst mit einer Verzögerung von einem Jahr vergleicht.
Die DW-Statistik ist deutlich kleiner als 2, was auf eine positive Autokorrelation hindeutet. Der p-Wert ist Null, was bedeutet, dass die Nullhypothese, dass die HadCRUT5-log2CO2-Residuen der linearen Anpassung nicht autokorreliert sind, falsch ist. Das heißt, sie sind wahrscheinlich autokorreliert. Mit R lässt sich die Berechnung leicht durchführen, aber sie ist unbefriedigend, da wir weder aus der Ausführung noch aus der Ausgabe viel verstehen. Führen wir also die gleiche Berechnung mit Excel durch und gehen wir die komplizierten Details durch.
Die komplizierten Details
Die verwendeten Basisdaten sind in Abbildung 1 dargestellt, die mit Abbildung 2 im vorherigen Beitrag [in deutscher Übersetzung hier] identisch ist:
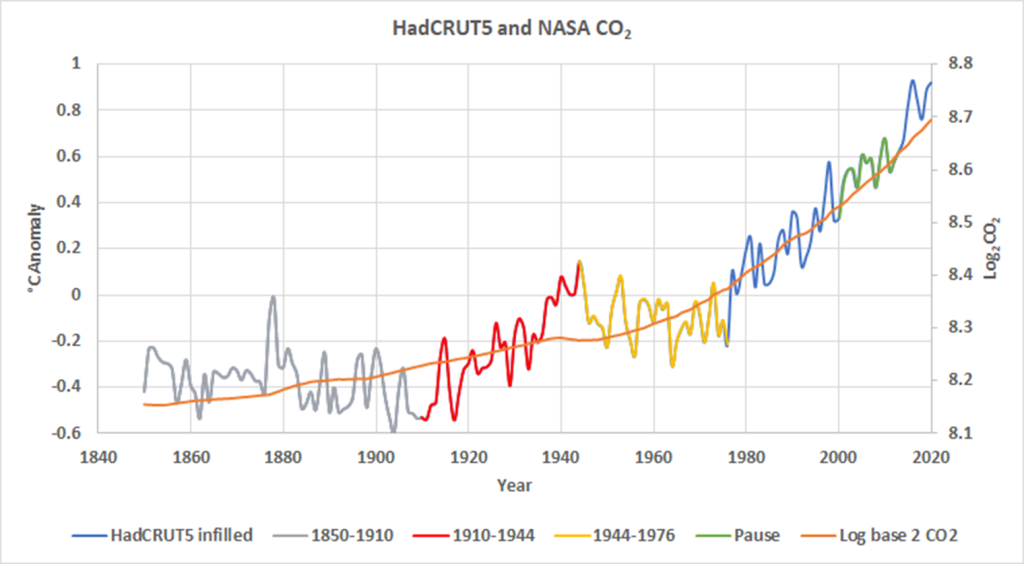
Abbildung 1. Die orangefarbene Linie ist der log↓2CO↓2-Wert, es wird die rechte Skala verwendet. Die mehrfarbige Linie ist die HadCRUT5-Aufzeichnung der globalen Oberflächentemperatur an Land und im Ozean, sie verwendet die linke Skala. Die verschiedenen Farben kennzeichnen die in der Legende angegebenen Zeiträume.
Streng genommen bezieht sich die Autokorrelation darauf, wie eine Zeitreihe mit einer zeitlichen Verzögerung mit sich selbst korreliert. Visuell können wir sehen, dass beide Kurven in Abbildung 1 autokorreliert sind, wie die meisten Zeitreihen. Das bedeutet, dass ein großer Teil jedes Wertes durch den vorangegangenen Wert bestimmt wird. So ist der log2CO2-Wert im Jahr 1980 stark vom Wert im Jahr 1979 abhängig, und dies gilt auch für die Werte von 1980 und 1979 in HadCRUT5. Dies ist ein kritischer Punkt, da alle LS-Anpassungen davon ausgehen, dass die verwendeten Beobachtungen unabhängig sind und dass die Residuen zwischen den Beobachtungen und den vorhergesagten Werten zufällig und normal verteilt sind. R² ist nicht gültig, wenn die Beobachtungen nicht unabhängig sind; eine fehlende Unabhängigkeit wird in den Regressions-Residuen sichtbar. Nachstehend finden Sie eine Tabelle der Autokorrelationskoeffizienten für die Kurven in Abbildung 1 für Zeitverzögerungen von einem bis acht Jahren:

Tabelle 1. Autokorrelationswerte für ein- bis achtjährige Verzögerungen für die HadCRUT5- und Log↓2CO↓2-Aufzeichnungen.
Die Autokorrelationswerte in Tabelle 1 wurden mit der hier zu findenden Excel-Formel errechnet. Die angezeigten Autokorrelationskoeffizienten variieren wie herkömmliche Korrelations-Koeffizienten von -1 (negative Korrelation) bis +1 (positive Korrelation). Wie Sie in der Tabelle sehen können, sind sowohl HadCRUT5 als auch log2CO2 stark positiv autokorreliert, d. h. sie steigen monoton an, wie wir mit einem Blick auf Abbildung 1 bestätigen können. Die Autokorrelation nimmt mit zunehmender Verzögerung ab, was normalerweise der Fall ist. Das bedeutet lediglich, dass die diesjährige Durchschnittstemperatur enger mit der Temperatur des letzten Jahres zusammenhängt als mit der des Vorjahres usw.
Aus Zeile 1 der Tabelle 1 geht hervor, dass etwa 76 % jeder HadCRUT5-Temperatur und über 90 % jeder NASA-CO2-Konzentration vom Vorjahreswert abhängig sind. In beiden Fällen ist also jeder Jahreswert nicht unabhängig.
Während die oben genannten Zahlen für die einzelnen Kurven in Abbildung 1 gelten, kann die Autokorrelation die Regressions-Statistik eindeutig beeinflussen, wenn die Temperatur- und CO2-Kurven gegeneinander regressiert werden. Diese bivariate Autokorrelation wird in der Regel mit der oben erwähnten Durbin-Watson-Statistik untersucht, die nach James Durbin und Geoffrey Watson benannt ist.
Lineare Anpassung
Wie in dem obigen R-Programm wird die Durbin-Watson-Berechnung traditionell anhand einer linearen Regression der beiden interessierenden Variablen durchgeführt. Abbildung 2 ist wie Abbildung 1, aber wir haben LS-Linien sowohl an HadCRUT5 als auch an Log2CO2 angepasst:
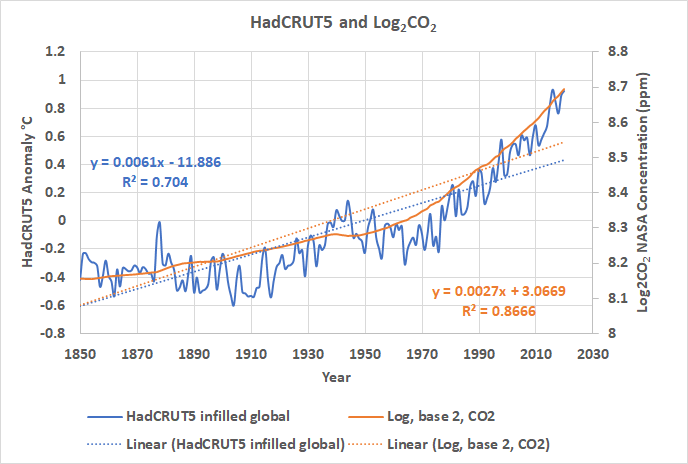
Abbildung 2. Die Linien der kleinsten Quadrate für CO↓2 in orange und HadCRUT5 in blau.
In Abbildung 2 steht Orange für log2CO2 und Blau für HadCRUT5. Die Residuen sind in Abbildung 3 dargestellt. Sie sind nicht zufällig und scheinen autokorreliert zu sein, wie wir es aufgrund der Statistiken in Tabelle 1 erwarten würden. Sie sind autokorreliert und haben die gleiche Form, was besorgniserregend ist.

Abbildung 3. Die Residuen der linearen Anpassung für CO↓2 und HadCRUT5.
Der nächste Schritt im DW-Prozess besteht darin, eine LS-Anpassung an die in Abbildung 3 gezeigten Residuen vorzunehmen, was in Abbildung 4 dargestellt ist:
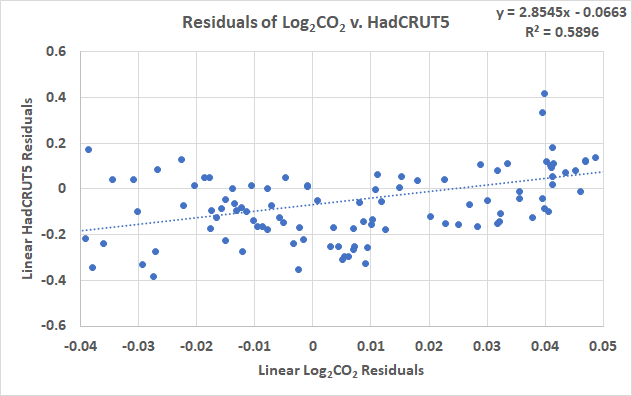
Abbildung 4. Anpassung der Residuen an die kleinsten Quadrate.
Wie befürchtet, korrelieren die Residuen miteinander und haben eine positive Steigung. Wenn man die DW-Berechnungen auf diese Weise durchführt, erhält man eine DW-Statistik von 0,84, die dem in R berechneten Wert nahe kommt, aber nicht genau gleich ist. Ich vermute, dass dies darauf zurückzuführen ist, dass die mehrfachen Summenquadrat-Berechnungen über 170 Jahre Daten zu dem feinen Unterschied von 0,04 führen. Wir können dies bestätigen, indem wir die R-Berechnung mit den Excel-Residuen durchführen:

R-Code zur Berechnung von DW mit Excel-Residuen
Dies bestätigt, dass beide Berechnungen übereinstimmen, aber es gab Unterschiede in den Quadratsummen-Berechnungen aufgrund der unterschiedlichen Gleitkommagenauigkeit in Excel und R. Bei einer linearen Anpassung an HadCRUT5 und log2CO2 gibt es also ernsthafte Autokorrelationsprobleme. Aber beide sind konkav nach oben gerichtet. Was wäre, wenn wir eine LS-Anpassung verwenden würden, die besser geeignet ist als eine Linie? Die Diagramme sehen aus wie ein Polynom zweiter Ordnung, versuchen wir das.
Polynomielle Anpassung
Abbildung 5 zeigt die gleichen Daten wie in Abbildung 1, aber wir haben Polynome zweiter Ordnung an jede der Kurven angepasst. Die CO2– und HadCRUT5-Daten weisen eine steigende Kurve auf, so dass dies eine große Verbesserung gegenüber den obigen linearen Anpassungen darstellt:

Abbildung 5: Polynom-Anpassungen 2. Ordnung.
Ich sollte erwähnen, dass ich die Gleichungen auf dem Diagramm nicht für die Berechnungen verwendet habe, sondern eine separate Anpassung an die Dekaden vorgenommen habe. Die Dekaden wurden unter Verwendung von 1850 als Null und 1850 bis 1860 als Dezimaldekaden und so weiter bis 2020 berechnet, so dass die X-Variable in der Berechnung kleinere Werte in den Berechnungen der Summe der Quadrate hatte. Damit wird das bereits erwähnte Problem der Fließkomma-Genauigkeit von Excel-Computern umgangen.
Im nächsten Schritt wird der vorhergesagte oder Trendwert für jedes Jahr vom tatsächlichen Wert subtrahiert, um die Residuen zu erhalten. Dies wird für beide Kurven durchgeführt, die Residuen sind in Abbildung 6 dargestellt:
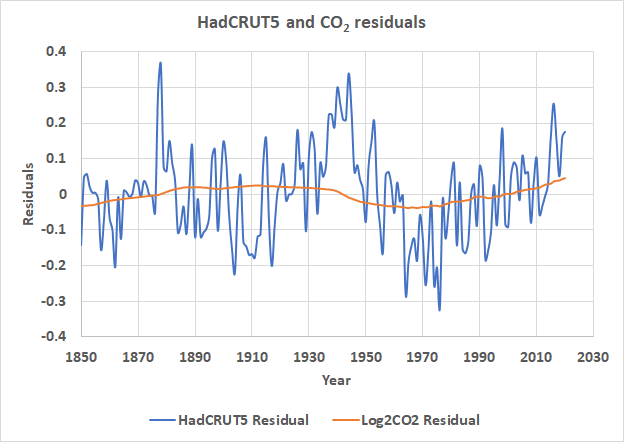
Abbildung 6. Die Residuen der polynomiellen Anpassung.
Abbildung 6 zeigt uns, dass die Residuen der polynomialen Anpassungen an HadCRUT5 und log2CO2 immer noch eine Struktur aufweisen und die Struktur visuell korreliert, was kein gutes Zeichen ist. Dies ist der Teil der Korrelation, der übrig bleibt, nachdem die Anpassung zweiter Ordnung entfernt wurde. In Abbildung 7 habe ich einen linearen Trend an die Residuen angepasst. Das R² ist geringer als in Abbildung 4:
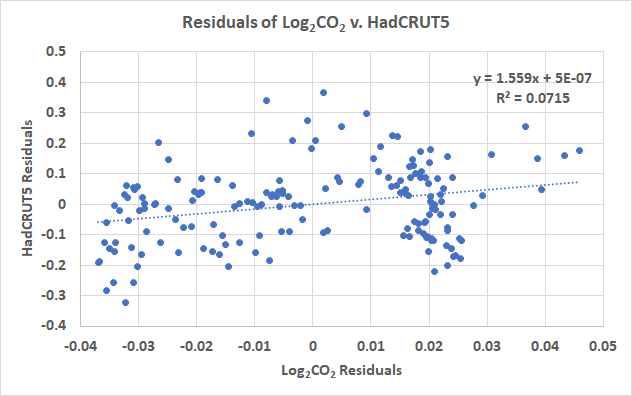
Abbildung 7. Eine Anpassung an die polynomialen Residuen.
Es gibt immer noch ein Signal in den Daten. Es ist positiv, was darauf hindeutet, dass, wenn die Autokorrelation wirklich mit der Anpassung 2. Ordnung entfernt wurde (wir können das statistisch nicht sagen, aber „was wäre wenn“), es immer noch eine kleine positive Veränderung der Temperatur gibt, wenn das CO2 steigt. Denken Sie daran, dass Autokorrelation nicht bedeutet, dass es keine Korrelation gibt, sondern nur, dass sie die Korrelationsstatistiken entkräftet. Wenn die Temperatur größtenteils von der Temperatur des Vorjahres abhängt und wir diesen Einfluss erfolgreich eliminieren können, bleibt die tatsächliche Abhängigkeit der Temperatur vom CO2. Leider können wir nie sicher sein, dass wir die Autokorrelation entfernt haben, und können nur spekulieren, dass Abbildung 7 die wahre Abhängigkeit zwischen Temperatur und CO2 darstellt.
Die Durbin-Watson-Statistik
Nun werden die Berechnungen zur Ermittlung der gemeinsamen Durbin-Watson-Autokorrelation durchgeführt, aber dieses Mal haben wir eine polynomiale Regression 2. Ordnung. Die nachstehende Tabelle zeigt die Durbin-Watson-Statistik zwischen HadCRUT5 und log2CO2 für eine Verzögerung von einem Jahr. Die Berechnungen wurden nach dem hier beschriebenen Verfahren durchgeführt:

Tabelle 2
Der Durbin-Watson-Wert von 0,9 für eine einjährige Verzögerung bestätigt, was wir in den Abbildungen 5 und 6 visuell gesehen haben. Die Residuen sind immer noch autokorreliert, selbst nach Entfernung des Trends zweiter Ordnung. Die verbleibende Korrelation ist, wie zu erwarten, positiv, was vermutlich bedeutet, dass CO2 einen geringen Einfluss auf die Temperatur hat. Wir können diese Berechnung in R bestätigen:

Der R-Code für den DW-Test der Polynom-Anpassung
Diskussion
Das R², das sich aus einer LS-Anpassung der CO2-Konzentration und der globalen Durchschnittstemperaturen ergibt, ist künstlich aufgebläht, weil sowohl CO2 als auch die Temperatur autokorrelierte Zeitreihen sind, die mit der Zeit zunehmen. Daher ist R² in diesem Fall eine ungeeignete Statistik. R² geht davon aus, dass jede Beobachtung unabhängig ist, und wir stellen fest, dass 76 % der globalen Durchschnittstemperatur eines jeden Jahres durch die Temperatur des Vorjahres bestimmt wird, so dass nur ein geringer Anteil durch CO2 beeinflusst wird. Außerdem wird die CO2-Messung jedes Jahres zu 90 % durch den Wert des Vorjahres bestimmt.
Ich kam zu dem Schluss, dass die beste Funktion zur Beseitigung der Autokorrelation ein Polynom 2. Ordnung war, aber selbst wenn dieser Trend entfernt wird, sind die Residuen immer noch autokorreliert, und die Nullhypothese, dass sie nicht korreliert sind, musste verworfen werden. Es ist enttäuschend, dass Robert Rohde, ein promovierter Wissenschaftler, ein Diagramm der Korrelation von CO2 und der globalen Durchschnittstemperatur verschickt und damit andeutet, dass die Korrelation zwischen ihnen ohne weitere Erklärung sinnvoll ist (wie wir in Abbildung 1 des vorherigen Beitrags gezeigt haben), aber er hat es getan.
Jamal Munshi hat 2018 in einem Papier eine ähnliche Analyse wie wir vorgenommen (Munshi, 2018). Er stellt fest, dass die Konsensidee, dass steigende CO2-Emissionen eine Erwärmung verursachen und dass die Erwärmung linear mit der Verdoppelung des CO2 ist (Logarithmusbasis 2), eine überprüfbare Hypothese ist. Diese Hypothese hat sich nicht gut bewährt, weil die Unsicherheit bei der Schätzung der CO2-bedingten Erwärmung (Klimasensitivität) seit über vierzig Jahren hartnäckig groß ist, im Grunde ±50 %. Dies hat dazu geführt, dass der Konsens versucht, von der Klimasensitivität wegzukommen und die Erwärmung mit den gesamten Kohlendioxidemissionen zu vergleichen, weil man glaubt, eine engere und validere Korrelation mit der Erwärmung herstellen zu können. Munshi fährt fort:
„Dieser Zustand in der Klimasensitivitätsforschung ist wahrscheinlich das Ergebnis einer unzureichenden statistischen Strenge in den angewandten Forschungsverfahren. Diese Arbeit zeigt falsche Proportionalitäten in Zeitreihendaten auf, die zu Klimasensitivitäten führen können, die nicht interpretierbar sind. … [Munshis] Ergebnisse deuten darauf hin, dass die große Anzahl von Klimasensitivitäten, die in der Literatur berichtet werden, wahrscheinlich größtenteils falsch sind. … Ausreichende statistische Disziplin wird wahrscheinlich die … Frage der Klimasensitivität auf die eine oder andere Weise klären, entweder um ihren bisher schwer fassbaren Wert zu bestimmen oder um zu zeigen, dass die angenommenen Beziehungen in den Daten nicht existieren.“
(Munshi, 2018)
Während wir in diesem Beitrag die CO2-Konzentration verwendet haben, verwenden viele im „Konsens“ nun die Gesamtemissionen fossiler Brennstoffe in ihrer Arbeit, weil sie denken, dass dies eine statistisch validere Größe zum Vergleich mit der Temperatur ist. Das ist nicht der Fall, die Probleme bleiben bestehen und sind in mancher Hinsicht sogar noch schlimmer, wie Munshi in einem separaten Beitrag erläutert (Munshi, 2018b). Ich stimme mit Munshi darin überein, dass es der Klimagemeinschaft an statistischer Strenge mangelt. Die Gemeinschaft verwendet Statistiken allzu oft, um ihren Mangel an Daten und statistischer Signifikanz zu verschleiern, anstatt zu informieren.
Der R-Code und die Excel-Tabelle, die zur Durchführung aller Berechnungen in diesem Beitrag verwendet wurden, können hier heruntergeladen werden.
Referenzen:
Munshi, J. (2018). The Charney Sensitivity of Homicides to Atmospheric CO2: A Parody. SSRN. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3162520
Munshi, J. (2018b). From Equilibrium Climate Sensitivity to Carbon Climate Response. SSRN. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3142525
Link: https://andymaypetrophysicist.com/2021/11/13/autocorrelation-in-co2-and-temperature-time-series/
Übersetzt von Christian Freuer für das EIKE














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Von Statistik habe ich wenig Ahnung. Ich weiss z.B. nicht, warum mit Logarithmen gerechnet werden soll. Korrelation ist auch ohne Logarithmen als solche sichtbar. Aber wie gesagt, ich bin da ungebildet. Daher kann ich keine Bemerkung zum Thema machen.
Aber zwei Grundsätze.
1, Wissenschaftlich ist es falsch, die kondensierbaren Gase, sprich H2O auszuklammern. Die das tun, und akzeptieren (Andy May), tun so, als ob H2O keine IR-Strahlen absorbieren und reemittieren würde.
Klar, das IPCC und die Klimahysterie-Industrie habe ein elementares Interesse daran, weil ihnen nur so gelingt, die Gefährlichkeit vom CO2 darzustellen. Aber das heißt noch lange nicht, dass wir ihnen da folgen müssen.
Wir wollen mal für die Wasserkonzentration in der unteren Atmosphäre in Mitteleuropa 10 g/m3 = 13.125 ppm annahmen. Das ist ein Durchschnittswert, welcher sowohl innerhalb eines Tages, wie auch jahrzeitbedingt schwankt, und zwar in viel stärkerem Maße, als die mickrige 0,04 %. Ausserdem müssen wir diesen Wert wegen der viel breiteren H2O-Absorptionsbande mit 1,5 multiplizieren. So haben wir einen Wert von 19688 ppm. Ist die CO2-Konzentration von 280 auf 400 ppm gestiegen? Dann ist die Konzentration der IR-aktiven Gase in der Atmosphäre von 19968 auf 20088 ppm gestiegen. Ich betone nochmal, das sind reine Zahlenspiele. Der tatsächliche Wassergehalt schwankt tagsüber, sowie von Sommer auf Winter in viel breiteren Grenzen, als 280 oder 400 ppm.
Und so sieht der Wachstum der Konzentration der IR-aktiven Gase seit 1850 oder 1958 schon gaanz anders aus.
2, Ich habe auch meine Probleme mit der angeblichen Konzentration von 280 ppm in der vorindustriellen Zeit.
Nach diesem Bild schwankte die Konzentration 1878-1880 zwischen 294 und 505 ppm.

Für den Durchschnitt dieser Werte bekomme ich 370 ppm.
Aber mal eine interessante Aufgabe für Statistiker, und Klimatologen.
Tamanraset liegt in der Sahara, und die durchschnittliche Wasserkonzentartion der Luft beträgt 6 g/m3.
Bangkok liegt etwa im selben Breitengrad. Dort beträgt aber die durchschnittliche Wasserkonzentartion der Luft 24 g/m3, d.h. das vierfache des Saharawertes.
Welche Durchschnittstemperatur von Bangkok würden Sie erwarten, wenn die Annahme stimmen würde, dass die Konzentration der IR-aktiven Gase messbar die Durchschnittstemperatur beeinflusst? Bedenken Sie dabei, welche Rolle es spielt, wenn die CO2-Konzentration verdoppelt wird. Und nicht vergessen! Nicht mit CO2-Konzentartion, sondern mit der Summe [CO2+H2O] rechnen!
Sehr wahr ihr Einwurf Herr Bálint!!!
… alleine an Ihrem Beispiel zum Vergleich von Bankok und der Sahara zeigt, das an einer
Erwärmung durch mehr Wasserdampf oder eben mehr CO2 in der Luft nix dran sein kann!
Wasserdampf, er kühlt, ebenso, wie CO2: beide transportieren Wärme per konvektion in die Tropopause und darüber hinaus in die stratosphäre. Wasserdampf wesentlich mehr als CO2. ZUeiner Erwärmung der Erde kann es nicht beitragen.
„Wasserdampf, er kühlt, ebenso, wie CO2: beide transportieren Wärme per konvektion in die Tropopause und darüber hinaus in die stratosphäre. Wasserdampf wesentlich mehr als CO2. ZUeiner Erwärmung der Erde kann es nicht beitragen.“
Sehe ich auch so!
Zitat:“Die komplizierten Details„. Dinge die man nicht verstanden hat sind kompliziert. Dinge die man verstanden hat sind komplex.
Hallo Herr Beinwein,
vielen Dank für diesen Einwurf! Sie haben natürlich recht! In unserem Falle kann man aber vielleicht sagen, dass die Alarmisten einer Melange aus kompliziert und komplex zum Opfer gefallen sind!
MfG Christian Freuer
Uff, auf diesem Gebiet hängt mich der Autor ganz klar ab. Was mich aber wundert, dass er die HadCRUT5-Temperaturen offenbar als Gott-gegeben richtig ansieht. Wogegen schon die bekannten vielen Adjustierungen und die Ermittlung von Temperatur-Anomalien sprechen. Bei Anomalien (Differenzen) kann ich mir auch gut die Abhängigkeit von den jeweiligen Vorwerten vorstellen, weil man die neu gemessenen „Anomalien“ jeweils zu den alten hinzuaddiert.
Hinzu kommt, dass zumindest nach visueller Wahrnehmung das CO2 (Mauna Loa seit 1960) recht schwach mit HadCRUT4 (Monatswerte) korreliert – sehr schön bei Climate4you zu sehen (der screenshot misslingt leider regelmäßig – der Kommentar verschwindet auf unerklärliche Weise…). Und je länger man das Mittelungsintervall wählt, desto „besser“ sieht die Korrelation aus (??). Und warum Zweifel nur an den CO2-Messungen, die ich für vergleichsweise zuverlässig halte? Werden dort anstelle von Absolutwerten ebenfalls nur Veränderungen (Anomalien) gemessen??
„Die verbleibende Korrelation ist, wie zu erwarten, positiv, was vermutlich bedeutet, dass CO2 einen geringen Einfluss auf die Temperatur hat.“
Ich sehe die Dinge etwas differenzierter. Ich verwende die globalen 12-Monate-Mittelwerte von NCEP Reanalysis Air 2m von 1948 bis 202110. Dieser Datensatz beruht auf der Wettervorhersage und hat sich seit Jahren bestens bewährt. Die Beschränkung auf den Zeitraum 1948-2021 ist kein Mangel, da die atmosphärische CO2-Konzentration cCO2 erst seit 1958 konsistent in Mauna Loa gemessen wird und sie nur in diesem Zeitraum stark angestiegen ist. Auto-Korrelation reduziert die 73 NCEP-Messpunkte auf effektive 18 Messpunkte, cCO2 zeigt keine Auto-Korrelation. Unter Berücksichtigung der Autokorrelation ist der Trend der Global-Temperatur 0,115 +/- 0,035 °C/Dekade. Die Temperatur hat sich also von 1948 – 2021 um 0,84 +/-0,26 °C erhöht. Die Ursachen dieser Temperatur-Erhöhung gilt es zu quantifizieren. Es genügt nicht den Beitrag von cCO2 mit statistischen Argumenten kleinzurechnen.
„Die Ursachen dieser Temperatur-Erhöhung gilt es zu quantifizieren.“ Ich habe ein lineares Regressions-Modell ausgearbeitet, das hierzu Hilfe leisten kann. Ich betrachte die von der Oberfläche im globalen Mittel von 12 Monaten ausgesandte thermische IR-Strahlung LWSUpAS. Daten siehe CERES für 2000-2021. Eine lineare Anpassung von LWSUpAS(t)= c0+c1*ln[cCO2(t)-cCO2(0)/cCO2(0)] entsprechend May ist in Bild 1 gezeigt. Das Bestimmtheitsmaß R²= 0,52 ist relativ gering. Der alternative Ansatz LWSUpAS(t)= c0+c1*ASRAS verbessert R² zu 0,62 (siehe Bild 2). Hierbei ist ASRAS die von der Erde insgesamt absorbierte Solar-Strahlung. Ein Teil der absorbierten Solarstrahlung erwärmt den tiefen Ozean. Dies führt zu einem Strahlungs-Ungleichgewicht TOA (siehe CERES). Ein Ansatz LWSUpAS(t)= c0+c1*ASRAS+c2*ln[cCO2(t)-cCO2(0)/cCO2(0)]+c3*ImbalanceTOA (siehe Bild 3) führt zu R²= 0,86. (ohne den cCO2-Term R²= 0,85).