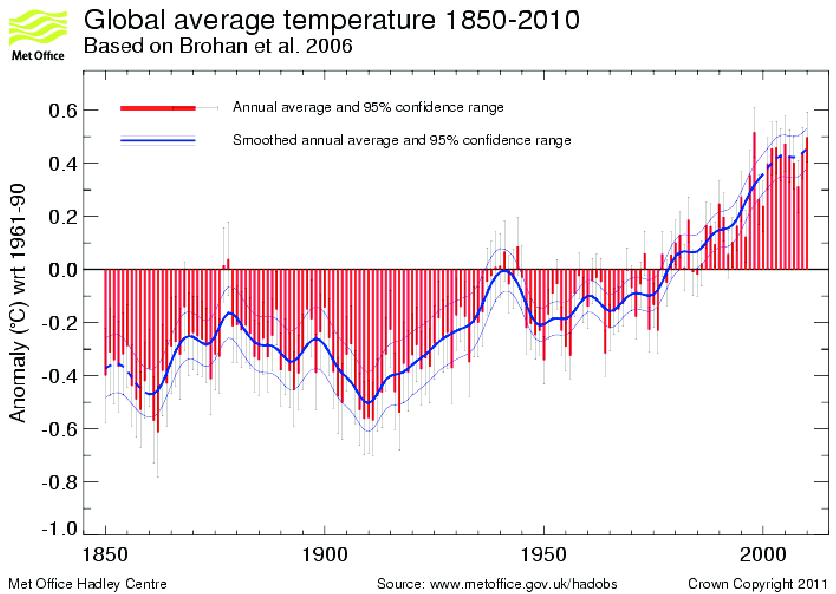
aktualisiert am 23.10.18
Die Quelle der ursprünglichen Grafik (hier wird die aktualisierte Version von Juli 2010 gezeigt) ist ein Aufsatz der IPCC Leitautoren Brohan und Jones[1] (hier mit Brohan et al 2006 genannt) indem detailliert beschrieben wird, wie man die unterschiedlichsten Temperaturdaten weltweit zusammenfasst und wie man dabei versucht allfällige Fehler, die diese Daten haben, zu kompensieren. Besonders schwierig ist das mit sog. systematischen Fehlern. Geht eine Uhr z.B. ständig 5 Minuten nach, dann nützt auch ein häufigeres Ablesen der Uhrzeit nicht weiter, die abgelesene Zeit ist immer um 5 Minuten falsch. Erst ein Vergleich mit einer genauen Referenzuhr erlaubt den Fehler zu erkennen und dann – als Korrrektur- von der abgelesenen Zeit einfach 5 Minuten hinzuzählen. Damit wäre der Fehler korrigiert. Diese einfache Methode ist natürlich bei den Temperaturdaten der Vergangenheit so gut wie nie anwendbar. Deswegen versucht man es dort u.a. mit der Bildung von Differenztemperaturen, in der Hoffnung dass sich dadurch die systematischen Fehler gegenseitig zum Verschwinden bringen.
Viele Klimatologen weltweit glauben nämlich fest daran [2], dass, wenn sie für die Trendbestimmung von Temperaturen, Differenzen aus bestimmten Temperatur-Variablen bilden würden, diese Differenzen (Anomalien) von allen systematische Fehlern befreit seien. Ein bekannter IPCC Leitautor gab mir auf Anfrage (wie man denn Seewassertemperaturen mit Lufttemperaturen mischen könne, wo doch beide Medien völlig unterschiedlich auf Wärme reagieren) vor einiger Zeit dazu diesen guten Rat:: „…… Think in ANOMALIES and not absolute temperatures.“ Diesen Rat befolgend, denke ich nun in Anomalien und schaue mir deren Verhalten in den offiziellen Temperaturganglinien an.
Anomalienbildung und Fehlerkorrektur
Das Verfahren der Differenzen- oder Anomalienbildung wird von allen Klimatologen umfassend eingesetzt, um die Trendverläufe stark unterschiedlicher Temperaturgänge vom Äquator bis zu den Polen vergleichbar machen zu können. Nun sind die gemessenen absoluten Temperaturen immer mit zahllosen Fehlern behaftet. Auch die daraus gebildeten Tages- Monats- oder Jahresmittelwerte enthalten diese Fehler. Und es kommen neue Fehler hinzu, die durch den verwendeten Algorithmus der zur Durchschnittsbildung verwendet wird, entstehen. Näheres dazu hier. Nach der Fehlertheorie unterscheidet man dabei zwischen zufälligen, groben, und systematischen Fehlern. Für diese Betrachtung sollen uns nur die systematischen Fehler interessieren.
In der Klimatologie werden zur Bestimmung des Referenzwertes, die errechneten Monatsmittel oder Jahrsmittel der gemessenen Temperatur einer Station, über den Zeitraum von 1961 bis 1990 aufaddiert und durch die Anzahl aller Monats- oder Jahresmittel dieses Zeitraumes geteilt. Der so enthaltene Wert entspricht einer Geraden gleicher „Temperatur“ über den Referenz-Zeitraum von 1961 bis 1990. (Es kann im Prinzip aber auch jeder andere Zeitraum sein.) Der zugehörige Referenz-Wert wird oft das Stationsnormal genannt. Folgerichtig heißen die Abweichungen vom (Stations)-Normal Anomalien.
Nun bildet man die Differenz aus allen absoluten Jahresmitteln Tx der Zeitreihe und dem Stationsnormal Tref und ermittelt auf diese Weise eine neue Zeitreihe der Anomalien eben dieser Station. Dabei geht man von der Annahme aus, dass diese, wenn sie einen Fehler C enthalten, dieser auch im Stationsnormal vorhanden ist. Ferner unterstellt man, dass C eine konstante Größe hat. Bspw. Brohan und Jones[3] formulieren diese Annahme (in Bezug auf die Fehler durch unterschiedliche Mittelwertbildung) so:
„..There will be a difference between the true mean monthly temperature (i.e. from 1 minute averages) and the average calculated by each station from measurements made less often; but this difference will also be present in the station normal and will cancel in the anomaly.
Berechnet man jetzt die Anomalie Ax = (Tx+C) –(Tref+ C), dann hebt sich C auf. Das ist schlichte Algebra. So weit so gut! Die große Frage ist nun, funktioniert das bei Zeitreihen auch so? Warum denn nicht, wird mancher vorschnell antworten. Die Algebra ist schließlich immer gleich! Oder?
Es zeigt sich sehr schnell, dass die Idee der Fehlerkompensation, die hinter dieser einfachen Methode steckt, ebenso plausibel wie falsch ist, bzw. sie stimmt nur innerhalb ganz enger Randbedingungen, die in der hier interessierenden Praxis nicht eintreten.
Anomalien und sprunghafter Fehler
Machen wir dazu die Probe aufs Exempel, indem wir einen Anomalienverlauf aus einem (künstlichen) sinusförmigen Temperaturverlauf von 1850 bis 2009 erzeugen. Blau sei der Anomalienverlauf ohne Fehler. Die Anomalie verläuft fast gradlinig, wie die blaue Trendlinie anzeigt. Ab 1940 wird nun ein Fehler von + 1 K eingefügt. Gemäß Rechenanweisung w.o. wird dann aus beiden Werten für alle Jahre (x) die Differenz gebildet. Ab 1940 hebt sich der Fehler auf. Beide Verläufe gehen ineinander über. Vor 1940 jedoch wird allein durch den Rechenprozess die Temperaturanomalie um 1 k abgesenkt. Wir sehen, die Annahme von vorhin gilt nur für die Zeit nach 1940. Vorher nicht. Lässt man Excel eine Trendgerade durch diese Werte legen, dann sehen wir, dass sich beide erheblich unterscheiden.

Daran ändert sich auch nichts, wenn wir den Eintritt des Fehler auf später verlegen. Wie das nächste Bild zeigt. Dort werden die Kurven Anomalie 1 und 3 genannt.

Auch hier hebt sich der Fehler nicht auf, sondern ist weiter voll vorhanden und wirksam, natürlich erst, nachdem er auftritt. Der Unterschied zum ersten Beispiel ist, dass nun überhaupt keine „wahre“ Temperaturanomalie mehr gezeigt wird, sondern nur noch die fehlerbehaftete Summe.
Schleichender Fehler
Genauso entwickelt sich das Ergebnis, wenn man anstatt (oder zusätzlich) einen schleichenden Fehler in den zuvor fehlerfreien Verlauf einbringt. Ich habe das in der folgenden Abbildung getan. Dort wurde von Anfang an ein schleichender systematischer Fehler von +0,1 K/Dekade eingebracht, wie er z.B. vom städtischen Wärmeinseleffekt hervorgerufen werden kann.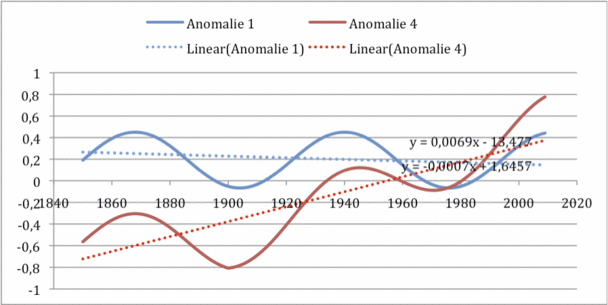
Wir sehen einen schön ansteigenden Verlauf (zuvor war er fast gerade) – verursacht allein durch den schleichenden systematischen Fehler- z.B den UHI. Nur kann jetzt überhaupt nicht unterschieden werden, ob ein systematischer Fehler vorliegt, oder ob sich die Umgebungstemperatur z.B. durch den Treibhauseffekt erhöht hat.
Man könnte nun beanstanden, dass die Fehlergröße in diesen Beispielen etwas hoch gewählt wurde. Dem ist aber nicht so, wie die zahlreichen Untersuchungen z.B. von Watts (http://www.surfacestations.org/) zeigen. Denn Fehler dieser Art gab und gibt es zahlreich. Sie werden durch Stationsverlegungen, Thermometertausch, Änderung der Farbbeschichtung der Station, Änderung des Algorithmus für die Berechnung des Mittelwertes u.v.a. mehr eingebracht. Es wäre nun vielleicht möglich den Anstieg im obigen Beispiel als Ausreißer zu erkennen, weil er einmalig und sprunghaft -wenn auch konstant- auftritt, und ihn durch entsprechende Rechnungen zu kompensieren. Das geschieht aber nur sehr, sehr selten, weil sich bei den abertausenden von Datensätzen der Vergangenheit kaum jemand diese Mühe macht, bzw. machen kann
Kein Fehlerausgleich möglich
Eine Korrektur unterbleibt hauptsächlich deswegen, weil man die Binsenweisheit (siehe Brohan et al 2006) von zuvor glaubt, dass sich der Fehler bei Anomalienbildung von selbst ausgleicht. Das ist aber, wie wir gesehen haben, grottenfalsch!
Eine Korrektur unterbleibt aber auch in den allermeisten Fällen deshalb, weil die dazu erforderlichen sog. „Metadaten“ fehlen und auch nicht mehr herbeigeschafft werden können. Diese beschreiben die Umgebungsbedingungen, Maßnahmen, Algorithmen und vieles anderes, was in und um die Station über den Zeitraum passiert ist. (Siehe dazu bspw. Harrys Read Me Files des Meteorologen und Programmierers bei der CRU Harry: „HARRY_READ_Me.txt.“ z.B. hier http://www.anenglishmanscastle.com/HARRY_READ_ME.txt. Diese ist 274 Seiten lang. Die dazugehörige Datenbasis enthält über 11.000 Dateien aus den Jahren 2006 bis 2009[4])
Allgemein gilt daher, die Annahme, dass sich bei Anomalienbildung die Fehler aufheben, ist nur dann richtig, wenn der gemeinsame, gleich große und richtungsgleiche Fehler vor dem Beginn der untersuchten Zeitspanne eintritt und dann so bleibt. In unserem Falle also vor 1850. Das liegt jedoch weder in unserem Ermessen, noch haben wir davon Kenntnis, sondern es wird allein durch die Realität bestimmt. Deshalb kann festgehalten werden, dass diese simple Fehlerkorrekturmethode in aller Regel nicht anwendbar ist. Angewendet wird sie aber von sehr vielen -auch IPCC- Klimatologen trotzdem.
Zusammenfassung
In der Statistik ist es eine gängige Methode Werte von div. Variablen mit Referenzwerten eben dieser Variablen zu vergleichen, um auf diese Weise bei eventuellen Abweichungen u.U. Ähnlichkeiten im Verlauf oder sogar Hinweise auf mögliche Ursache und Wirkungsbeziehungen zu bekommen. Allerdings muss man sich immer im Klaren darüber sein, wie sehr diese Methode von den Randbedingungen abhängt. Es wird gezeigt, dass eine schlichte Anomalienbildung keineswegs ausreichend ist, um schwer bestimmbare variable oder konstante systematische Fehler herauszurechnen. Im Gegenteil, man müsste in jedem Fall diese Fehler bestimmen, sie quantifizieren und einordnen, um sie dann evtl. mehr oder weniger gut rechnerisch ausgleichen zu können. In der Klimatologie ist diese Einschränkung in Bezug auf die Schwächen der Anomalienbildung offensichtlich nicht überall bekannt. Nur so lässt sich erklären, dass auch hochangesehene Forscher diese simplen Zusammenhänge oft nicht beachten. Ihre Ergebnisse sind dadurch entsprechend falsch und damit unbrauchbar, bzw. mit wesentlich größeren Fehlern (Unsicherheiten) behaftet als angegeben.
Michael Limburg EIKE
[1] Brohan, PK,J. J. Harris, I., Tett S. F. B.; & Jones, P. D. (2006) Uncertainty estimates in regional and global observed temperature changes: a new dataset from 1850. HadCRUT 3 HadCRUT 3:1 to 35.
[2] Brohan et. al 2006 geben auf Seite 6 den allgemeinen Glauben an die Fehlerfreiheit der Anomalien wider, in dem sie schreiben: „..There will be a di?erence between the true mean monthly temperature (i.e. from 1 minute averages) and the average calculated by each station from measurements made less often; but this di?erence will also be present in the station normal and will cancel in the anomaly. So this doesn’t contribute to the measurement error. Im Folgenden beschreiben die Autoren wie die Anforderungen an die Bildung der „station normals“ also der Referenzwerte (lt. WMO der Mittelwert jeder Station über die Jahre 1961-1990) aufgeweicht (relaxed) wurden. Die durchgeführte Reduktion der Anforderungen zur Bildung des Referenzwertes (Station Normal) auf nur noch 15 Jahre und daraus 3 x 4 Jahre in jeder Dekade, erhöht den Fehler, der schon in der Verwendung des Station Normals steckt, weiter
[3] Brohan, PK,J. J. Harris, I., Tett S. F. B.; & Jones, P. D. (2006) Uncertainty estimates in regional and global observed temperature changes: a new dataset from 1850. HadCRUT 3 HadCRUT 3:1 to 35.
[4] Details entnommen aus ‚Botch after botch after botch‘ Leaked ‚climategate‘ documents show huge flaws in the backbone of climate change science By LORRIE GOLDSTEIN














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Starke Turbulenzen der Luft hinter Flugzeugen und großflächige Verwirbelungen eben auch von heißen Abgasen der Strahltriebwerke, ermöglichen eine weite Verteilung von stark erwärmter Luft rings um einen Flugplatz.
Wirbelschleppen sind Turbulenzen hinter Flugzeugen, die andere Flugzeuge zum Absturz brachten.
>>> Textauszug:
„Die Wirbelschleppen bestehen aus entgegengesetzt rotierenden Luftmassen. Sie dehnen sich rückwärts und nach unten aus. Ihre Kraft ist sehr stark von den momentanen meteorologischen Bedingungen (Wind, Labilität) abhängig. Wirbelschleppen können für nachfolgende Luftfahrzeuge sehr gefährlich sein, da sie die sonst laminare Strömung extrem stören und es so zu einem Strömungsabriss kommen kann.“
Um die Kräfte in einer Wirbelschleppe zu veranschaulichen…
Hier der Bericht: http://tinyurl.com/45ev26q
Nach Lektüre des Berichts versteht man vielleicht, warum eine korrekte Temperaturmessung im Umfeld eines Flugplatzes nicht möglich ist…
Nach meiner Meinung dürften im Umkreis von mind. 3 km Abstand zu einem Flugplatz,
gar keine Temperaturmessungen, die für die Klimamitteltemperatur verwertet werden, zugelassen sein. Sollte sich herausstellen, daß die Turbulenzen weiter reichen, müsste der Radius noch erweitert werden.
Da dieser EIKE-Blog ein Gegen-den-Strom-Schwimmer-Pool zum Klimahype, kann ich mir mit Bezug auf den selten gehörten Begriff „Wirbelschleppe“ den blogfremden Kommentar nicht verkneifen, als Gegen-den-Strom-Schwimmer des 9/11-Anschlags auf eben das Fehlen dieser Wirbelschleppen in den Explosionsfeuerwolken, die aus den Wolkenkratzern bersten, hinzuweisen. Als (ein von mehreren) Indiz für ganz besonders wagemutige Detektive, an der Existenz der Flugzeuge zu zweifeln! Auch wenn dies meinem Nachnamen alle Ehre macht, sind die Studien nicht von der Hand zu weisen…
https://www.youtube.com/watch?v=sV6ffjCGUbE&index=6&list=PLXIEFAucX3fg2J8EWNDw2l94-cPAqWruh ab 4:35min und
https://www.youtube.com/watch?v=qW8G2EOYr6Q&index=7&list=PLXIEFAucX3fg2J8EWNDw2l94-cPAqWruh
sehr empfehlenswert
43 Herr Ebel versteht wirklich nicht was „systematisch“ bedeutet.
Zitat „@ #41: Dr.Paul,Freitag, 11.02.2011, 16:13
„Prinzipiell könnte solch ein Fehler der Wärmeinseleffekt sein. Aber der wird korrigiert.“
Die eigentliche Aussage bezüglich der Korrekturvorschrift wird überlesen. Das war eindeutig formuliert – also muß ich eine unfreundliche Absicht unterstellen.“
Na klar hat die IPCC unfreundliche Absichten,
davon handelt doch der Beitrag!
Uns interessiert nicht der Temperaturanstieg der Flugplätze,
jetzt werden Sie bitte nicht komisch, irgend etwas anderes als diese Kernaussage draus zu machen.
@ #41: Dr.Paul,Freitag, 11.02.2011, 16:13
„wann möchten Sie freundlicherweise zur Kenntnis nehmen, dass systematisch und zufällig nicht gleichbedeutend ist???“
@ #42: Bernd Hartmann, Sonntag, 13.02.2011, 16:13
„dass in den einzelnen Messstationen die Temperatur immer mit mehreren Messmethoden gemessen wird.“
Drücke ich mich nur so mißverständlich aus?
Numerieren wir die Tausende Meßstationen mit A, B, C usw.
Zufällig hat irgendwann die Station A einen systematischen Fehler mit zufälliger Größe, ein andermal hat zufällig irgendwann die Station B einen systematischen Fehler mit anderer zufälliger Größe, andermal hat zufällig irgendwann die Station C einen systematischen Fehler mit anderer zufälliger Größe usw.
Der Mittelwert über alle Stationen hat dann nur noch einen kleinen (oder gar keinen) systematischen Fehler. Wie gesagt es ging nur um die systematischen Fehler nach Anomalienbildung auf jeder Station.
@ #41: Dr.Paul,Freitag, 11.02.2011, 16:13
„Prinzipiell könnte solch ein Fehler der Wärmeinseleffekt sein. Aber der wird korrigiert.“
Die eigentliche Aussage bezüglich der Korrekturvorschrift wird überlesen. Das war eindeutig formuliert – also muß ich eine unfreundliche Absicht unterstellen.
MfG
#39
Lieber Herr Ebel,
Sie haben mit Ihrer Antwort zur Rettung Ihrer Ehre einen Teil Ihrer Aussage von #27 erklärt. O.K. Verstanden!
Aber es kann auch wohl wirklich nicht wahr sein und auch nicht der gängigen Praxis entsprechen, dass in den einzelnen Messstationen die Temperatur immer mit mehreren Messmethoden gemessen wird. (Dann wäre die mögliche Existenz mehrerer systematischer Fehler vollkommen logisch.) Es besteht andererseits tatsächlich nicht der geringste Bedarf, sich grundsätzlich über den Charakter von Fehlern und deren Ermittlung auseinanderzusetzen. Bekanntlich muss hier kein Fahrrad neu erfunden werden. Wie wir wissen, gehört das schon seit geraumer Zeit zum handwerklichen Repertoire der Naturwissenschaften.
Es ist demnach kein Problem, den zufälligen Fehler einer Messung (den jede Messung hat) festzustellen. Die meist etwas schwierigere und aufwändigere Aufgabe besteht darin zu ermittel, ob überhaupt ein systematischer Fehler vorliegt und wie groß er dann gegebenenfalls ist.
Mit freundlichen Grüßen
B. Hartmann
P.S.: Herr Ebel, ich wollte Ihnen wirklich mit #36 persönlich nicht zu nahe treten. Falls das Ihre Eindruck war, bitte ich um Verzeihung. Sie sollten jedoch darauf gefasst sein, wenn Sie Aussagen vom Typ #27 treffen, entsprechend gepfefferte Antworten erhalten.
MFG / B.H.
#39: Verehrter Herr Jochen EBEl,
wann möchten Sie freundlicherweise zur Kenntnis nehmen, dass systematisch und zufällig nicht gleichbedeutend ist???
„Prinzipiell könnte solch ein Fehler der Wärmeinseleffekt sein. Aber der wird korrigiert.“
Hier von Herrn Limburg,
Gott sei Dank gibt es diese „Klimarealisten“
Q Herr Ebel
#26: Jochen Ebel sagt:
am Mittwoch, 09.02.2011, 14:52
Die krtisierte Aussage bezog sich eindeutig auf:
@ #11: Hans Spaniol, Dienstag, 08.02.2011, 12:44
„Nach einer Weile hören sie dann die Stimmen von Verstorbenen :-)“
Hinweis angekommen.
Den Post von Hans Spaniol fand ich übrigen völlig daneben. Hätte er sich wirklich sparen können.
mfG
Herr Bernd Hartmann,
als man die Längenkalibrierung noch mit dem Urmeter gemacht hat, hat jeder davon abgeleitete Längenmesser einen sytematischen Fehler gehabt, der auf der Zufälligkeit der genauen Herstellung des Vergleiches beruhte. Wenn Sie also mit verschiedenen Längenmessern das gleiche Objekt gemessen haben, dann hat jede Messung mit einem bestimmten Längenmesser einen zufälligen Fehler plus einem systematischen Fehler. Wenn Sie jetzt die Messungen mit verschiedenen Längenmesser machen, dann sind in der Gesamtmessung die systematischen Fehler wieder zufällig, weil der systematische Fehler der Messung mit einem bestimmten Längenmesser eben zufällig beim Vergleich war.
Und es ist eben sehr unwahrscheinlich, daß bei allen Meßstationen die gleichen systematischen Fehler in der Anomalienbildung existieren.
Prinzipiell könnte solch ein Fehler der Wärmeinseleffekt sein. Aber der wird korrigiert. Nun kann für die einzelne Station ein systematischer Restfehler bleiben – aber die Restfehler der einzelnen Stationen werden stark zufällig sein, außer wenn die Vorschrift der Korrektur des Wärmeinseleffekts einen Fehler enthält.
MfG
#33: Martin Frank sagt:
am Donnerstag, 10.02.2011, 07:59
„#28 Dr. House
Ich glaube, da verwechseln Sie was. Ihr Zitat hab ich nie gesagt, geschrieben bzw stehe dazu. Ich gehe doch 100% mit Ihrer Erklärung überein. Sie meinten bestimmt jemand anderen.“
Ja, das stimmt, Entschuldigung. Ich habe aus dem Beitrag #23 von Wolfgang Berger zitiert.
Lieber Herr Hartmann,
„Schließlich haben Sie meine eigentliche Frage auch nicht beantwortet – Wo gibt es denn die Alternative zur Bestimmung des systematischen Fehlers des globalen Temperaturwertes, wenn man sich nicht wenigstens eine Auswahl von Landstationen dafür vornehmen würde?“
Man braucht keine Alternative, denn die Kontrolle der Messwerte ist am besten. Das passiert auch, aber es gibt eben auch die Fälle, wo Instrumentenwechsel nicht dokumentiert wurden, Fehler der Instrumente nicht bekannt/entdeckt sind oder Metadaten Lücken haben. Das erschwert die Analyse. Aber auch in der Meteorologie verfährt man nach dem Motto:
„So oder so – wo eine Wille ist, gibt es auch eine Lösung…(oder anders auf Ingenieurdeutsch: geht nicht gibt`s nicht.)“
Man wirft die Flinte nicht ins Korn, sondern berücksichtigt die „Unvollkommenheit“ durch Einrechnen entsprechender Fehler! Diese selber lassen sich häufig nur aus vergleichbaren Situationen großzügig schätzen. Da ist Sachverstand gefragt. Den hier regelmäßig anhand von trivialen Binsenweisheiten abzusprechen, halte ich für Augenwischerei.
Bei der meteorologischen Temperaturmessung muß man bei den systematischen Fehlern folgendes unterscheiden:
1) der übliche Instrumentenfehler: das Thermometer zeigt eine Abweichung von x Grad, wenn man die Messpitze ins thermischen Gleichgewicht mit einem Medium bekannter Temperatur bringt. Dazu nimmt man typischerweise die Fixpunkte (Siede- und Schmelzpunkt) von Wasser sowie ggb auch andere, um auch nicht über den Messbereich konstante systematische Fehler zu erkennen. Dieser systematische Fehler ist das geringere Übel, denn der wird vor Inbetriebnahme im Labor ermittelt und ggf. regelmäßig nachgemessen.
2) der systematische Fehler durch die Umgebung des Thermometers. Üblicherweise benutzt man ja die Doppellamellen-Hütte, die gut durchlüftet und frei von der Sonne bestrahlbar 2 Meter über bewachsenem Boden steht. Wenn man diese Regeln einhält, so findet man trotzdem systematische Unterschiede zwischen verschiedenen Hüttenausführungen und Größen, oder auch zu ventilierten Sensoren in kleineren Strahlungschutzhüllen. Das liegt an der unterschiedlichen WW der Thermometerumgebung im Strahlungsschutzraum mit dem Thermometer. Diese Abweichungen liegen im unter 1 Grad-Bereich, hängen im Detail systematisch vom Wetter ab, und müssen natürlich bei der Datenanalyse berücksichtigt werden. Dazu muss man eben über Korrekturdaten verfügen, dies geschieht durch repräsentative Versuche, ist aber auch nicht fehlerfrei, sondern nur fehlerreduzierend!
#33
Lieber Herr Bäcker,
in der Tat – das ist alles nichts Neues und Kunst hin und her…
„…das globale Mittel kann man nicht direkt messen. Wie wollen Sie dem einen systematischen Fehler zuordnen? Es ist doch viel mehr so, dass der Fehler im globalen Mittel aus den Fehlern der verwendeten Messdaten (systematische, zufällige, …)“- Herr Bäcker, ich bitte Sie! Na, logo! (So sagte ich es ja auch mit anderen Worten. Und nebenbei gesagt, bemerken Sie also auch die „Genialität“ des Inhalts von #27…)
Was die kartographische Darstellung der Messdaten betrifft, so ist das eine vollkommen sekundäre Sache! Um die Zahlen geht es doch letztendlich!
Schließlich haben Sie meine eigentliche Frage auch nicht beantwortet – Wo gibt es denn die Alternative zur Bestimmung des systematischen Fehlers des globalen Temperaturwertes, wenn man sich nicht wenigstens eine Auswahl von Landstationen dafür vornehmen würde? So oder so – wo eine Wille ist, gibt es auch eine Lösung…(oder anders auf Ingenieurdeutsch: geht nicht gibt`s nicht.)
Mit freundlichen Grüßen
B. Hartmann
Lieber Herr Hartmann,
tja wasserdichte Grundlagen, das ist keine Kunst. Aber trotzdem fehlt die Fehlerrechnung fürs globale Mittel! Und damit wird wieder mal viel um den heissen Brei geredet aber nichts konkretes zum Thema geäußert!
„Trotzdem muss zur Bestimmung wenigstens des „allgemeinen“ bzw. globalen systematischen Fehlers der Temperaturmessung der Luft eine Messmethode herangezogen werden, die nachweislich und deutlich präzisisere Werte hervorbringt als traditionelle Messungen auf Landstationen. Vielleicht kann sich hier jemand dazu einmal kompetent äußern!?“
Herr Hartmann, das globale Mittel kann man nicht direkt messen. Wie wollen Sie dem einen systematischen Fehler zuordnen? Es ist doch viel mehr so, das der Fehler im globalen Mittel aus den Fehlern der verwendeten Messdaten (systematische, zufällige, …) und der Methodik der Berechnung des globalen Mittels (Repräsentationsfehler, Analysefehler, Kartierungsmethode) folgt!
Ich werde Ihnen da nichts Neues erzählen, aber einmal haben Sie die Fehler in dem empirischen Messungen, aber ebenso nicht zu verachten sind die Unsicherheiten, die bei der Umsetzung von nur punktweise vorliegenden Zeitreihen in eine flächendeckende Karte implementiert sind.
„Jedenfalls kann ich mir beim besten Willen nicht vorstellen, dass im speziellen Fall der Klimatologie andere Prinzipien der Ermittlung und Betrachtung von Fehler gelten sollen als im Rest der Wissenschaften und der Industrie!“
Eben, ich mir auch nicht. Wenn man mal in den Leitlinien der WMO zur Messtechnik meteorologischer Größen nachguckt, so gewinne ich jedenfalls nicht den Eindruck, dass dort keine der üblichen Qualitäts- und Messvorschriften fehlen. Wie die in der Praxis nun umgesetzt werden, ist wieder eine andere Frage, aber ich denke nicht, dass die Messtechniker meteorologischer Messungen unfähiger sind als Messtechniker im allgemeinen.
#32:
guter Beitrag,
ohne Niederschlag (Schneefall)ist eine Bilanz nicht möglich!!!
Aus dem gleichen Grund glauben einige Experten,
dass das Eis in Grönland NICHT abnimmt, sondern zunimmt. Dazu passt, dass der minimale Anstieg des Meeresspiegels offenbar zum Stillstand gekommen ist.
#28 Dr. House
Ich glaube, da verwechseln Sie was. Ihr Zitat hab ich nie gesagt, geschrieben bzw stehe dazu. Ich gehe doch 100% mit Ihrer Erklärung überein. Sie meinten bestimmt jemand anderen.
#24 Kommentar M.L.
Hin und wieder lockert ein wenig Humor eine verbissene Diskussion ein wenig auf. Ich wollte Wolfgang Berger doch nur zeigen, wieso sein Termometer hin und wieder andere Werte zeigt. Vielleicht haben Sie es nur ein wenig falsch verstanden, sorry.
#18: michael m
Sehr geehrter Herr michael m
In Ihrem Beitrag heisst es an einer Stelle: „Anhand des rückganges eines gletschers kann ich zwar nachweisen das es lokal wärmer geworden ist, jedoch nichts über die güte der temperaturmessung bzw des temperaturmittels aussagen“.
Ich möchte in diesem Zusammenhang einmal mit Nachdruck darauf hinweisen, dass fast die gesamte Menschheit nicht zu wissen scheint, was eigentlich banales Wissen ist: nämlich, dass die Grössenentwicklung der Gletscher zwar auch von der Wärme- / Sonneneinwirkung abhängt (durch Schmelzen des Eises im Sommers), wodurch die Eismenge eines Gletschers geringer wird, aber im Gegensatz dazu während kälteren Phasen im Winter (Temperaturen von unter 0 Grad Celsius), die Gletscher nicht kleiner werden. Ein wesentlicher Faktor bei der Entwicklung der Gletschergrösse, der vollkommen übersehen wird bzw. unterschätzt wird, ist aber das Verständnis bzw. das In-Rechnung-Stellen des Mechanismus wie Gletscher wachsen: das Ausmass des Wachsens der Gletscher im Winter (was selbstverständlich in jedem Winter auf der Nordhalbkugel z.B. in der Alpen passiert) hängt praktisch ausschliesslich mit der Niederschlagsmenge (vor allem in Form von Schnee) in der kalten Jahreszeit zusammen. Eine saubere Betrachtung bzw. wissenschaftliche Untersuchung des Phänomens des Gletscherrückgangs vieler Gletscher in den Alpen, sollte nicht nur die simplen Temperaturverhältnisse während des gesamtem Jahres in den Gletscherregionen analysieren, aber ebenso die Niederschlagsmengen im Winter zur Abklärung des Gletscherwachstums abklären. Ich habe aber in den IPCC Berichten noch niemals auch nur eine Erwähnung dieses Zusammenhangs gesehen: warum wohl ?
Es könnte sehr gut sein, dass es gar keine globale Erwärmung gibt, die die Gletscher in ihrer Grösse schrumpfen lassen (dort wo sie tatsächlich schrumpfen), sondern es fällt vielleicht nur seit Jahrzehnten in den Gegenden, wo es Gletscher gibt (Hochgebirge, Grönland, Antarktis, etc.) immer weniger Niederschlag und die jährliche Gesamtbilanz (Schrumpfen in Warmzeiten versus Wachstum in Kaltzeiten) ist auf der negativen Seite der Grössenentwicklung. Hat man schon jemals daran gedacht, ob vielleicht grössere Niederschlagsmengen sich in den letzten Jahrzehnten von Bergregionen / Grönland / Antarktis in andere Erdregionen bewegt haben (z.B. mehr Niederschläge in Indien, Australien, Tropenregionen)? Man sollte die Entwicklung der Niederschlagsverteilung über der Erdoberfläche systematisch untersuchen und nicht den zu kurzen, simplen Schluss ziehen: Warm heisst Gletscherrückgang. Man nennt das Phänomen, dass man sich im Zusammenhang mit der Entwicklung der Gletschergrössen vor Augen halten sollte, „Fliessgleichgewicht“ und es gibt diese Phänomene in der Naturwissenschaft an vielen Stellen.
Auf den Punkt gebracht, will ich mit dem Beitrag sagen, sagen die Klimaalarmisten den Faktor Gletscherwachstum durch Niederschlagsmengen im Winter im Fliessgleichgewicht „Gletschervolumen“ weitestgehend unterschlagen und damit der Öffentlichkeit (Politiker, Journalisten, Bürger) vorgaukeln, dass eine angebliche grössere Wärme auf dem Planeten als Grund für den Gletscherrückgang verantwortlich ist, wenn gleichzeitig der zweite wichtige Faktor bezüglich der Entwicklung des Gletschervolumens (d.h die Mechanismen des Wachstums) vollkommen unerwähnt bzw. unberücksichtigt bleibt. Das riecht doch nach selektivem Weglassen von wesentlichen Elemtem der natürlichen Vorgänge.
Lieber Herr Limburg,
wirklich ein „wasserdichter“ Beitrag. Meinen Glückwunsch dafür!
#27
Lieber Herr Ebel,
„Wenn an einem Ort systematische Fehler sind, aber die Verteilung dieser einzelner systematischer Fehler für einen Meßort auf die einzelnen Meßorte zufällig ist, dann ist der Durchschnitt über die zufälligen systematischen Fehler genauer als der systematische Fehler jedes Meßortes.“ – Das ist doch nicht Ihr Ernst? Oder!? Sie meinen doch nicht, dass bspw. „einzelne(r) systematische(r) Fehler für einen Meßort“, d.h also mehrere systematische Fehler für einen Messort bzw. eine Messapparatur existieren und auch noch dazu dementsprechend verteilt mit hinreichend großer Stichprobe sind, wie aus Ihrer Äußerung hervorgeht. Wenn man weiter schlussfolgert, könnte man meinen, dass Sie sich lieber nicht weiter zur Theorie der Fehlerermittlung und Fehlerrechnung öffentlich mitteilen sollten. Oder aber Sie haben sich vollkommen missverständlich ausgedrückt, was hier ganz eindeutig der Fall wäre.
(Wer Sie glaubt, nur ein wenig zu verstehen und auch wirklich nur ein wenig oder vielleicht auch fast gar nichts von der Fehlerbetrachtung versteht, könnte im ersten Moment meinen, dass hier ein Grenzfall zwischen Genialität und absoluten Unsinn vorliegt.)
Der zufällige Fehler einer Messeinrichtung lässt sich einerseits nur aus Messreihen aus eben dieser Messeinrichtung bestimmen. Andererseits bestünde jedoch der rein theoretisch beste Weg zur Ermittlung von systematischen Fehlern bzw. ob dieser überhaupt vorliegt für EINE konkrete Messapparatur darin, dass man ihre Messreihen solchen gegenüberstellt, die mit einer nachweislich weitaus präziseren Messeinrichtung am selben Messort zur selben Zeit ermittelt wurden. (Es lägen dann also Messwerte höherer Autorität vor.)Diese Aufgabe entsprechend der geschilderten Herangehensweise kann man natürlich schon aus Gründen der physischen Machbarkeit nicht angehen wollen. Trotzdem muss zur Bestimmung wenigstens des „allgemeinen“ bzw. globalen systematischen Fehlers der Temperaturmessung der Luft eine Messmethode herangezogen werden, die nachweislich und deutlich präzisisere Werte hervorbringt als traditionelle Messungen auf Landstationen. Vielleicht kann sich hier jemand dazu einmal kompetent äußern!?
Jedenfalls kann ich mir beim besten Willen nicht vorstellen, dass im speziellen Fall der Klimatologie andere Prinzipien der Ermittlung und Betrachtung von Fehler gelten sollen als im Rest der Wissenschaften und der Industrie!
Mit freundlichen Grüßen
B. Hartmann
#27: Jochen Ebel
„die zufälligen systematischen Fehler“
Herr Ebel hat wieder ein neues Ebel´sches Paradoxon erfunden
#25: NicoBaecker
„Ja und?“
Flugplatztemperaturen als Wettertemperaturen zu verkaufen ist FÄLSCHUNG
„#24: Martin Frank sagt:
Klima ist ein Mittelwert der Wetterdaten über einen längeren Zeitraum. Die Wissenschaft hat sich dabei auf 30 Jahre geeinigt.“
Klima ist kein Mittelwert, sondern einige Menschen glauben, dass verschiedene Mittelwerte etwas über Klima aussagen. Klima ist einfach die Gesamtheit aller Wetterereignisse.
Genauso, wie Mensch kein Durchschnittsblutdruck, kein Durchschnittsgewicht, keine Durchschnittsintelligenz etc ist.
@ #18: michael m., Dienstag, 08.02.2011, 20:25
„öhm, sie sollten sich mit der messunsicherheitsberechnung befassen 😉 auch in der betrachtung historischer aufnahmen sind systematische fehlerkomponenten enthalten.“
Diese systematischen Fehler sind wieder von anderer Art. Wenn an einem Ort systematische Fehler sind, aber die Verteilung dieser einzelner systematischer Fehler für einen Meßort auf die einzelnen Meßorte zufällig ist, dann ist der Durchschnitt über die zufälligen systematischen Fehler genauer als der systematische Fehler jedes Meßortes.
@ #18: michael m., Dienstag, 08.02.2011, 20:25
„öhm, sie sollten sich mit der messunsicherheitsberechnung befassen“
Kann ich Ihnen wärmstens empfehlen.
MfG
@ #17: Sabrina Schwanczar, Dienstag, 08.02.2011, 19:46
„In der Nachrichtentechnik wird der Aufbau des Signal vom Ingenieur definiert. Deshalb kann man gezielt im Rauschen danach suchen. Signal empfangen müssen Sie trotzdem, sonst wird nichts.“
Das weiß ich. Die krtisierte Aussage bezog sich eindeutig auf:
@ #11: Hans Spaniol, Dienstag, 08.02.2011, 12:44
„Nach einer Weile hören sie dann die Stimmen von Verstorbenen :-)“
Oder wollen Sie sagen die Stimmen der Verstorbenen sind im Rauschen?
MfG
Lieber Herr Berger,
in der modernen Klimatologie wird unter Klima der statistische beschriebene Zustand des Wetters verstanden. Das inkludiert den Mittelwert, aber eben diesen nicht allein. Was die Medien darunter verstehen und was die Leute für irre Vorstellungen mit Klima verbinden, interessiert die Wissenschaft nicht!
„Zufällig herausgegriffen sage ich, weil ich im Vergleich zwischen meiner Wetterstation und der offiziellen Wetterstation Magdeburg Flugplatz schon Temperaturdifferenzen von bis zu knapp 5 K festgestellt habe. Insbesonder bei nächtlichen Tiefstwerten.“
Ja und? Solche Erfahrungen habe ich mit meiner Wetterstation auch gemacht. Wundert Sie das, können Sie sich das meteorologisch nicht erklären? Nur damit mich mir hinterher nicht wieder angeschmiert vorkomme: wir reden hier von Aktualwerte bzw. täglichen Extremwerten und NICHT Tages- oder Monatsmittel, richtig? Was für Abweichungen (typisch + extrem) messen Sie für Tages- und Monatsmittel?
@#23: Wolfgang Berger
“ besonders wenn man bedenkt, dass meine Station den urbanen Einflüssen (städtische Wärmeinsel) viel stärker ausgesetzt ist.“
vielleicht solltest Du Dir eine paar startende/landende Flugzeige in den Garten stellen, bzw den Garten betonieren und Triebwerke laufen lassen.
Wir bekommen es schon hin, also ich, Du und Eike, dass dein Thermometer endlich für die ‚Klimawissenschaft‘ richtige Werte anzeigt
Versuch 2
Nun Herr Baecker,
Klima ist ein Mittelwert der Wetterdaten über einen längeren Zeitraum. Die Wissenschaft hat sich dabei auf 30 Jahre geeinigt. In den Medien wird heutzutage Klima mehr oder weniger mit einer Mitteltemperatur gleichgesetzt und oft auch noch fälschlicherweise als „Normalwert“ tituliert. Um zum Mittelwert des Klimas zu gelangen werden Methoden der Statistik angewendet.
Was ich mit diesem zufällig herausgegriffenen Beispiel (außer meinem durch Sie vermuteten Unwissen) aber belegen wollte ist, dass massenhaft falsche Wertte in die Statistik eingehen und damit den Mittelwert verfälschen. Zufällig herausgegriffen sage ich, weil ich im Vergleich zwischen meiner Wetterstation und der offiziellen Wetterstation Magdeburg Flugplatz schon Temperaturdifferenzen von bis zu knapp 5 K festgestellt habe. Insbesonder bei nächtlichen Tiefstwerten. Auch wenn meine Wetterstation ungeeicht ist und sicher nicht den höchsten wissenschaftlichen Ansprüchen genügt, sind die Differenzen doch enorm, besonders wenn man bedenkt, dass meine Station den urbanen Einflüssen (städtische Wärmeinsel) viel stärker ausgesetzt ist.
#21 beker
Hören Sie auf zu stänkern wenn Ihnen die Argumente fehlen!!!
Nun Herr Berger,
damit belegen Sie eigentlich nur, dass Sie nicht wissen, was Statistik und Klima ist.
Schon die zufälligen Fehler bei den erfaßten Temperaturdaten sind erschreckend. Der heutige Morgen beweist dies. Um 07:00 Uhr morgens meldet die offizielle Wetterstation Flugplatz Magdeburg +0,6°C. Meine private Wetterstation innerhalb der Stadt zeigt – 2,3°C (was in Anbetracht der knochenhart gefrorenen Umgebung ganz offensichtlich zutreffender ist). Um 08:00 Uhr hat der Flugplatz Magdeburg ganz plötzlich auch -2,2°C. Wenn man sich dann darum streitet, um wieviel zehntel oder gar hundertstel Grad die Welt wärmer geworden ist, erscheint dies jedem halbwegs gebildeten Menschen als lächerlich.
Die Flucht aus der Fläche
Vielleicht ist es ja nur die Angst vor der Abkühlung, die die Wissenschaftler dzu treibt, die noch verbliebenen „Flächenmessstellen“ aufzugeben.
Es gibt ja bereits eine Diskussion über die beängstigende Zunahme des Waldes. Die menschen strömen in die Städte und das zurückgelassene Land wird vom Wald langsam erobert, der ist natürlich kälter als die Stadt. In der Schweiz spricht man von 30-50% Zunahme, wo soll das hinführen?
Hier ein optischer Vergleich 1929 und 2001
beängstigend: http://tinyurl.com/6c5grmg
und die „wissenschaftliche“ Problematisierung der ständigen Waldzunahme findet man z.B. hier: http://tinyurl.com/4uoxw2c
vorsicht über 200 Seiten, natürlich in der Problematisierungssprache Deutsch
[quote]Lieber Herr Limburg,
das ist doch gerade der Punkt: Sie behaupten also, dass die bestehenden „verzweifelten“ Versuche Datenreihen zu homogenisieren, die wenigen homogenisierten Zeitreihen, die vielen nicht homogenisierten Reihen und die zweifelhaften „quality adjusted“ Reihen zu einem größeren Fehler im globalen Mittel führen müssten als die ausgewiesenen Fehler von etwa 0,05 K im Jahresmittel?
[/quote]
genau so ist es. diese fehlereinflüsse lassen sich eben nicht einfach per statistik wegrechnen.
Sie verwechseln statistik mit dem begriff Messunsicherheit!
**
[quote]#7: Jochen Ebel sagt:
am Dienstag, 08.02.2011, 07:56
…
Dann gibt es noch Kontrollen ohne systematische Fehler. Z.B. gibt es historische Aufnahmen von Gletscherzungen und die heutige Zungengröße. Würde die gemittelte Temperatur systematische Fehler in Größenordnungen enthalten, würden sich Widersprüche zwischen Temperaturentwicklung und Zungengröße ergeben. Mir ist Nichts derartiges bekannt.
[/quote]
öhm, sie sollten sich mit der messunsicherheitsberechnung befassen 😉 auch in der betrachtung historischer aufnahmen sind systematische fehlerkomponenten enthalten.
Auch ihr zweiter satz ist leider falsch. Anhand des rückganges eines gletschers kann ich zwar nachweisen das es lokal wärme geworden ist, jedoch nichts über die güte der temperaturmessung bzw des temperaturmittels aussaben. Es ist halt nicht möglich den wahren wert der über den zeitverlauf auftretenden mitteltemperatur zu bestimmen welcher nötig wäre den gletscher abzuschmelzen.
@Admin
versuch 3
@ #12: Jochen Ebel
In der Nachrichtentechnik wird der Aufbau des Signal vom Ingenieur definiert. Deshalb kann man gezielt im Rauschen danach suchen. Signal empfangen müssen Sie trotzdem, sonst wird nichts.
Bei den Temperaturen hat man es eben nicht mit einem Signal zu tun, dessen Verlauf vordefiniert und bekannt ist. Deshalb funktioniert das so nicht.
Und stark fehlerhafte Daten sind kein Rauschen. Wenn fehlerhafte Daten empfangen werden, dann bleiben sie fehlerhaft, egal ob verrauscht oder nicht.
Baecker,
Offensichtlich ist ihnen bei der wissenschaftlichen Ausbildung der Humor abhanden gekommen :-))
#7
der Heizungsingenör beehrt uns wieder:
„Wenn nämlich ein deutlicher Zusammenhang des Eintretens systematischer Fehler bekannt wäre, dann kann mit diesem bekannten Zusammenhang dieser Anteil des systematischen Fehlers beseitigt werden.“
Gerade das ist ja die verdienstvoll Arbeit von Eike, Herr Jochen Ebel.
Die Temperatur auf den Flugplätzen steigt systematisch an.
Leider nicht in meinem Garten.
Schafft die Thermometer ab !
Und die Temperaturmess-Satelliten gleich mit !
Schluss mit der wetterbedingten Temperatur !
Die „wahre“ Temperatur eines Ortes sollte anhand der globalen CO2-Konzentration bestimmt werden – also abhängig von geografischer Breite, Jahreszeit und Abstand zum Meer.
Vorschlag: nach Ermittlung der CO2-Konzentration durch das IPCC auf dem Mauna Loa wird nach einem Computermodell die Temperatur für jeden Punkt der Erde berechnet. Damit ist diese Temperatur endlich frei von wetterbezogenen Schwankungen. Sie könnte auch Klimatemperatur genannt werden.
Zugleich kann man damit beweisen, dass es immer wärmer wird, weil die CO2-Konz. ständig steigt. Und so folgt aus dem Strahlungsantrieb der Treibhausgase die wahre Temperatur für jeden Ort der Erde – schöne neue Welt !
Endlich kann man sich das Messen ersparen.
Spaniol,
wenn Sie keine wissenschaftliche Ausbildung erfahren haben, so können Sie natürlich nicht wissen, wovon ich schrieb.
Sehr gehrter Herr @ #11: Hans Spaniol, Dienstag, 08.02.2011, 12:44
Sie haben sicher ein Navi. Ohne den von Herrn @ #10: NicoBaecker, Dienstag, 08.02.2011, 11:03 beschriebene Effekt „nur um aus dem Rauschen einen peak herauswachsen zu sehen“ würde Ihr Navi nicht funktionieren. Für die erforderliche zeitliche Auflösung braucht der Empfänger eine hohe Bandbreit (> 1 MHz) und da verschwinden die Satellitensignale im Rauschen. Erst durch Korrelátion mit der bekannten Formen der Satellitensignale ist der Peak zu finden. Deswegen auch immer die relativ lange Zeit, bis genügend Satelliten (mindestens 4) empfangen werden.
MfG
Ja, das gibt es was der Herr Baecker beschrieben hat.Neulich im TV war eine Sendung über Leute, die sich das Rauschen an einem Rundfunkempfänger intensiv anhören. Nach einer Weile hören sie dann die Stimmen von Verstorbenen 🙂
So ähnlich ist kommt der Herr Baecker auch zu seinen Erkenntnissen.
Lieber Herr Weiss ,
ich weiß ja nicht, über welche wissenschaftliche Erfahrungen Sie verfügen. Aber „averaging“ ist ein wohldefiniertes und kontrolliertes Verfahren, und es gibt unzählige experimentelle Untersuchungen, bei denen die Suche eines Signals in stark verrauschten Daten durch Mitteln wichtig ist.
Ich kann mich noch an meine Arbeit als Student an einem Hochenergielabor erinneren, wo man sich Nächte um die Ohren geschlagen hat, nur um aus dem Rauschen einen peak herauswachsen zu sehen und gejubelt hat, als der peak an der Stelle aus dem Rauschen auftauchte, wo er nach der Theorie erwartet wurde.
Sehr geehrter Herr Baecker
Mit Verlaub, aber Ihre Argumentation ist barer wissenschaftlicher Blödsinn. Sie und alle, die ähnlicher Ansicht sind, sind schon dermassen weit von eigentlicher Wissenschaftlichkeit entfernt, dass Ihnen offenbar ein gesundes Gefühl für methodologische Sauberkeit einer experimentellen Anordnung vollständig abgeht: sie können doch nicht im Ernst behaupten, dass x-mal herumgerechnete originale Messwerte (in diesem Fall Temperaturablesungen), was dann „smoothing“, „averaging“ etc. genannt wird, einen „wahreren“ Wert haben sollten als die originalen Messwerte. Gerade darin besteht ja die unsägliche wissenschaftliche „Verluderung“ ihres Lagers. Etwas was in der gesamten Wissenschaft sonst selbstverständlich ist, wird bei Ihnen wegen der Unmöglichkeit, die von Ihnen herbeigesehnten Resultate zu zeigen, einfach irgendwie herbeigerechnet. Wenn Exponenten Ihres Lagers sagen, dass die einzelnen Messwerte eines Thermometerstandortes zu stark schwanken, und deshalb permanent „geaveragt“ werden müssen, damit für Sie etwas Vernünftiges entsteht (nämlich, dass es wärmer wird), dann rechnen Sie um, was das Zeug hält. Ich bin absolut sicher, dass Ihre irrsininige Herumrechnerei nicht durchgeführt würde, wenn es kälter werden würde.
Herrn Limburg aufzufordern, er solle die wissenschaftlich unsinnigen Rechenmethoden Ihres Lagers nachvollziehen und Ihnen vorzeigen, ist eine wissenschaftliche Unanständigkeit, denn Sie sind es, der beweisen muss, was Sie behaupten: dass es wärmer wird. Und, beweisen Sie es nicht durch zweifelhafte Computertricks, sondern durch wissenschaftliche Ernsthaftigkeit: Temperaturen werden von Thermometern abgelesen und nicht durch Computer errechnet.
Wenn Sie auch Beiträge von mir zensiert haben (d.h. meine Antwort auf Beleidigungen nicht veröffentlicht haben) versuche ich doch auch auf EIKE die Wahrheit hochzuhalten.
Der Mittelwert der Temperaturen ist nicht so fehlerbehaftet, wie der Einführungstext suggerieren will.
Bei jeder Station kann durch Thermometerwechsel usw. ein gewisser systematischer Fehler auftreten. Aber wann dieser Fehler und in welcher Richtung bei einer bestimmten Station auftritt, ist weitgehend zufällig verteilt über alle Meßstationen. Damit reduziert sich der systematische Fehler bei den Einzelstation bei der Bildung des Mittels über alle Stationen. Wenn n Stationen zufällige sytematische Fehler haben, so ist der Fehler der Mittelung um den Faktor Wurzel(n) kleiner. Damit im globalen Mittel ein systematischer Fehler verbleibt, müßten Sie nachweisen, daß die systematischen Fehler der Einzelstationen korreliert sind – und davon steht nichts in Ihrem Einführungstext. Wenn nämlich ein deutlicher Zusammenhang des Eintretens systematischer Fehler bekannt wäre, dann kann mit diesem bekannten Zusammenhang dieser Anteil des systematischen Fehlers beseitigt werden.
Dann gibt es noch Kontrollen ohne systematische Fehler. Z.B. gibt es historische Aufnahmen von Gletscherzungen und die heutige Zungengröße. Würde die gemittelte Temperatur systematische Fehler in Größenordnungen enthalten, würden sich Widersprüche zwischen Temperaturentwicklung und Zungengröße ergeben. Mir ist Nichts derartiges bekannt.
MfG
Ich bin über die Arbeitsweise der klimawissenschaft ohnehin sehr verwundert.
Seriöse wissenschaftliche Arbeit fängt mit einer seriösen Datenbasis an und setzt sich fort mit dem Vergleich von Daten, die mit den gleichen Methoden erhoben wurden.
Weder hat man ein klar und eng definierten Bedingungen entsprechendes Netz an Temperaturerfassungsstellen geschaffen, noch vergleicht man dieselben Standorte miteinander.
Genau damit fängt man aber an, bevor man weitergehende Betrachtungen über nachträglich rückwirkend rekonstruierte Temperaturannahmen mit erheblichen Fehlern ins Spiel bringt.
Im Widerspruch dazu wendet man erhebliche Summen für Rechentechnik zur Simulation von Klimamodellen auf.
Das passt alles überhaupt nicht zusammen und erweckt bei mir den Eindruck, dass man an wissenschaftlich belastbaren Ergebnissen nicht wirklich Interesse hat, es also in Wahrheit um Politik geht.
„So ist es lieber Herr House. Wir sind weit entfernt von jeder representativen Stichprobe.Und haben auch keinerlei Chance mehr diese für die Vergangenheit zu bekommen.
Abe selbst wenn wir die ideale Verteilung hätten und daraus eine „stimmige“ Mitteltemperatur bestimmen könnten, was wäre das denn? Eine Temperatur bestimmt nicht, denn die ist eine lokale intensive Größe ohne Fernwirkung. Ein Index? Mit ständig wechselnder Datenbasis? Das klappt nur beim DAX. Was dann?
mfG
M.L:“
Das wäre ein Index, aber so weit wollte ich nicht gehen. Der entscheidende Punkt ist, dass das, was AGW-Anhänger haben, nichts taugt.
Die AGW-These basiert auf 2 Behauptungen:
a) CO2 erwärmt die Luft, und zwar dermaßen stark, dass etwas mehr CO2 zu wesentlich wärmerer Luft führt, und
b) die Luft wird in der Tat immer wärmer.
Ich habe es bewusst vereinfacht dargestellt, weil so verstehen es Politiker und Journalisten. Dabei sollte man bedenken, dass man bei Politikern und Journalisten mit BWL/Jura/Germanistik-Hintergrund keinen Erfolg haben wird mit Sätzen, wie „Temperatur ist eine lokale intensive Größe ohne Fernwirkung“, so Leid es mir tut.
Wenn wir also diese These kippen wollen, dann ist es genug und notwendig, diese 2 Punkte zu kippen, und das möglichst in „plain German“. Nur Punkt (a) zu kippen, reicht nicht, weil aus der Erwärmung wird man trotzdem Katastrophenszenarien ableiten können.
Lieber Herr Limburg,
das ist doch gerade der Punkt: Sie behaupten also, dass die bestehenden „verzweifelten“ Versuche Datenreihen zu homogenisieren, die wenigen homogenisierten Zeitreihen, die vielen nicht homogenisierten Reihen und die zweifelhaften „quality adjusted“ Reihen zu einem größeren Fehler im globalen Mittel führen müssten als die ausgewiesenen Fehler von etwa 0,05 K im Jahresmittel?
Ich gehe davon aus, dass dies zusammenpasst.
Wenn Sie das bezweifeln, so rechnen Sie das vor! GENAU diese Rechnung ist hier gefragt. Alles andere ist Reden um den heissen Brei und sind „Beweise durch Suggestion“. Mehr haben Sie im Moment nicht!
Sehr geehrter Herr Limburg,
ich fürchte, es ist noch schlimmer mit der s.g. „Welttemperatur“. Bei der Messungen handelt es sich schlicht und einfach um nichts anderes, als Stichproben. Hätten wir eine ideale Positionierung der Thermometer, sagen wir, in 1m Abstand von einander, dann hätten wir ideale Ergebnisse. Bei Stichproben mit nur ein paar tausend Thermometer wird sich das Ergebnis von diesem idealen ziemlich unterscheiden. Wenn es sich dabei z.B. um +/- 2 Grad handelt, dann sind alle Anomalien innerhalb diesen Bereiches statistisch vollkommen irrelevant.
Also, solange es nicht geklärt ist, wie sich Ergebnisse der Stichproben von einem idealen Ergebnis unterscheiden, und dazu noch, wie repräsentativ diese Stichproben sind, kann man überhaupt keine statistische Erwärmung oder was auch immer feststellen.
Lieber Herr Limburg,
Ihre Darstellung ist klar und verständlich, das ist nicht selbstverständlich. Dafür erstmal ein Lob. Was Sie schreiben, ist prinzipiell natürlich richtig, aber überraschend nun auch nicht.
Aber wie kommen Sie darauf, dass sich Brohan 2006 auf Rohdaten und nicht auf die homogenisierten Daten, in denen systematische Fehler korrigiert wurden, bezieht? Sollte man doch logischerweise annehmen, oder?
Denn Ihre Liste von systematischen Fehlerquellen ist ja klimatologische Binsenweisheit, und wenn Sie die wissenschaftliche Literatur durchforsten würden, so würden Sie unzählige paper finden, die sich mit Inhomogenitäten (durch Instrumentenwechsel, Ablesevorschrieften, Stationsänderungen, etc.) befassen. Und darunter sind Autoren (wie z.B. Jones, Wigley und Karl), die auch bei der Ermittlung globaler Anomalien beteiligt sind.
Nach der schönen Erläuterung des Trivialen fehlt nun also der Beweis Ihrer zentralen Behauptung, nämlich ob es denn WIRKLICH auch der Fall ist, dass man systematische Fehler nicht korrigierte?
Es ist klar, dass es Lücken in den Metadaten gibt, und manche Korrekturen so unsicher sind, wie die Korrektur selber, so dass einfach nur der Verwurf diese Messdaten übrigbleibt. Aber tun Sie nicht so, dass man Korrekturen systematischer Fehler nicht durchführen würde und inzwischen eine Menge von „tricks“ entwickelt hat, wie man Korrekturen anbringen muss (durch Nachbau historischer Instrumente, Laborversuche, Vergleich mit proxys und anderen historischen Daten, Nachprüfung von Standorteinflüssen durch Nachbau oder Simulation, Einfluss von verschiedenen Ablesemethoden, Korrelationen mit anderen Stationen, …)!
Sehr geehrter Herr Limburg
haben Sie vielen Dank für diese exzellente und logisch völlig klare und korrekte Darlegung der methdologischen Schwächen der Temperaturberechnung durch AGW gläubige Klima-Alarmisten.
Es wäre verdankenswert, wenn es eine ähnlich gründliche Analyse der mindestens ebenso zeifelhaften methdologischen Bestimmung eines jährlichen Meeresspiegelanstiegs gäbe, der auf ebenso schwachen Beinen steht, wie die behaupteten Temperaturerhöhungen.
Nirgendwo sehe ich irgendwelche stichhaltigen Beweise der AGW-Apostel für ihre Theorien der menschengemachten globalen Klimaveränderungen.