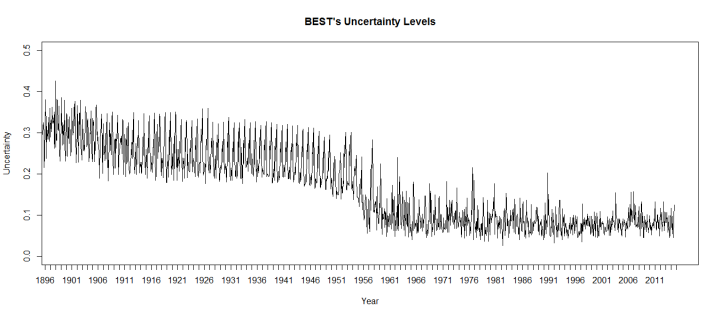
Bild rechts: Man beachte die Schritt-Änderung. Etwa im Jahre 1960 ist das Unsicherheitsniveau abgestürzt; oder anders ausgedrückt, BEST behauptet, dass man sich danach doppelt so sicher ist bzgl. ihrer Temperaturschätzungen, und zwar praktisch über Nacht.
Erstens, BEST lässt nur die Mittelwert-Berechnungen noch einmal durchlaufen, um deren Unsicherheit zu bestimmen. Sie berechnen aber nicht noch einmal den „Breakpoint“*. Man erinnere sich, BEST unterteilt die Daten von Temperaturstationen in Segmente, wann immer sie glauben, einen „Breakpoint“ gefunden zu haben. Hauptsächlich wird nach diesen Breakpoints gesucht, indem man die Stationswerte mit nicht weit entfernten benachbarten Stationen vergleicht. Falls an einer Station der Unterschied zu den Nachbarstationen zu groß ist, unterteilt man die Werte dieser Station in Segmente, die nachfolgend neu angepasst [realigned] werden können. Dies ist eine Form von Homogenisierung, ein Prozess, bei dem die Werte benachbarter Stationen so bearbeitet werden, dass sie sich ähnlicher sind.
[*Dieses Wort hat mehrere Bedeutungen, und weil ich nicht weiß, welche am besten passt, lasse ich den Begriff so stehen. Anm. d. Übers.]
Dieser Prozess wird bei den Unsicherheits-Berechnungen von BEST nicht wiederholt. Der ganze Datensatz ist homogenisiert, und Untergruppen dieser homogenisierten Datensätze werden verglichen, um zu bestimmen, wie viel Varianz darin steckt. Das ist unsachgemäß. Die Größe der Varianz, die BEST innerhalb eines homogenisierten Datensatzes findet, sagt nichts darüber, wie groß die Varianz in den BEST-Daten ist. Sie sagt uns nur, wie groß die Varianz ist, wenn BEST erst einmal die Homogenisierung der Daten abgeschlossen hat.
Zweitens, um zu berechnen, wie groß die Varianz in seinen (homogenisierten) Datensätzen ist, lässt BEST die Berechnungen noch einmal laufen, wobei zuvor ein Achtel der Daten entfernt worden ist; acht mal. Dies erzeugt acht verschiedene Reihen. Vergleicht man diese verschiedenen Reihen miteinander, passt BEST die Daten so an, dass sie alle der gleichen Grundlinie folgen. Der Grundlinien-Zeitraum, den BEST für diese Anpassung verwendet, ist 1960 bis 2010.
Das ist ein Problem. Wenn man die acht Reihen nach dem Zeitraum 1960 bis 2010 ausrichtet, wird die Varianz zwischen jenen Reihen im Zeitraum 1960 bis 2010 künstlich gedämpft (und die Varianz anderswo künstlich erhöht). Dies erweckt den Anschein, dass es im letzten Teil der BEST-Aufzeichnung mehr Sicherheit gibt als in Wirklichkeit vorhanden. Das Ergebnis: Es gibt einen künstlichen Stufenschritt im Unsicherheitsniveau bei BEST um das Jahr 1960. Dies ist das gleiche Problem, das schon bei Marcott et al. gezeigt worden ist (hier).
Alles in allem ist das Unsicherheitsniveau bei BEST ein einziges Durcheinander. Es ist unmöglich, diese in irgendeiner bedeutsamen Weise zu interpretieren, und sie können mit Sicherheit nicht dazu verwendet werden zu bestimmen, welche Jahre die wärmsten gewesen waren oder auch nicht.
Link: http://wattsupwiththat.com/2015/01/29/best-practices-increase-uncertainty-levels-in-their-climate-data/
Übersetzt von Chris Frey EIKE
BEST mit praktizierten Sprüngen des Unsicherheits-Niveaus in ihren Klimadaten














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Mit „Breakpoint“ ist bei Temperaturreihen ein Temperatursprung gemeint, nach oben oder nach unten. Der wird oft dadurch erzeugt, wenn die Messtation etwas versetzt wird, oder das Gelände besser oder weniger geschützt wird. Oder wenn die Thermometer getauscht wurden.
Natürlich sollte man solche Vorgänge beachten und die Daten entsprechend anpassen. Nur ist die Methode von BEST und auch von GISS/NASA und anderen diese, dass man das nur auf dem Papier versucht, herauszubekommen. Nämlich indem man schaut, ob Stationen von Nachbarstationen auffällig abweichen.
Und dann wird der Ausreißer glattgebügelt. Dabei wird missachtet, das ein lokales Klima ganz anders sein kann als der Durchschnitt.
Bei der GISS-Datenreihe werden übrigens fehlende Temperaturmesstationen durch Daten von Nachbarstationen, die bis zu 1250km entfernt sind, ersetzt. Weil es eben in manchen Gegenden dazwischen nichts gibt. Das ist, als würde man die Temperatur von München mit der von London und Rom vergleichen und korrigieren.
#2: Ach, Herr Fischer, Sie als Politiker immer wieder mit Ihren Nullsätzen. Gewöhnen Sie sich besser daran, dass die CO2-Lüge auffliegen wird, die Energiewende scheitern wird oder Deutschland ein Agrarstaat wird. Hoffentlich erlebe ich noch, dass Leute wie Sie zur Rechenschaft gezogen werden.
Ja, Herr Hartmann, genau das sollen Sie glauben. Sehr brav, bravo!
Ganz nach dem alarmistischen, klimawissenschaftlichen Motto:
Glaube keiner Statistik, die du nicht selbst gefälscht hast!
😉