In einem vorangegangenen Beitrag (hier, auf Deutsch beim EIKE hier) wurde gezeigt, dass die auf die GHCN-Daten angewendeten Adjustierungs-Modelle geschätzte Werte für etwa 66% der Informationen erzeugt hat, die den Verwendern der Daten zur Verfügung gestellt wurden wie etwa GISS. Weil die US-Daten einen relativ großen Beitrag zum Umfang der GHCN-Daten leisten, nimmt sich dieser Beitrag die Auswirkungen der Adjustierungs-Modelle auf die USHCN-Daten vor. Die Graphiken in diesem Beitrag verwenden den um 14 Uhr am 25.9.2015 heruntergeladenen Datensatz von der USHCN FTP Site.
Im USHCN V2.5-File ,Readme‘ liest man: „Die Version USHCN 2.5 wird jetzt erzeugt mittels des gleichen Processing-Systems, das auch auf die monatliche Version der GHCN 3-Daten angewendet worden ist. Dieses Reprocessing besteht aus einem Konstruktions-Prozess, der die monatlichen Daten der Version 2.5 des USHCN in einer speziellen Prioritäts-Reihenfolge zusammenfasst (eine, die monatliche Daten bevorzugt, die direkt aus der jüngsten Version von GHCN-Daily berechnet wurden). Qualität kontrolliert die Daten, findet Inhomogenitäten und führt Adjustierungen durch, wo es möglich ist“.
Es gibt drei wichtige Unterschiede im GHCN-Prozess. Erstens, der USHCN-Prozess erzeugt einheitliche Ergebnisse, die Schätzungen der Beobachtungszeit an jeder Station zeigen. Zweitens, USHCN wird Werte für fehlende Daten zu schätzen versuchen, ein Prozess, der bekannt ist unter der Bezeichnung infilling [im Folgenden mit „Auffüllung“ übersetzt]. Derartige Daten werden jedoch vom GHCN nicht verwendet. Der dritte Unterschied ist, dass die homogenisierten Daten für die US-Stationen von den durch das GHCN adjustierten Daten der gleichen US-Stationen abweichen. Meiner Vermutung nach ist der Grund hierfür, dass die Homogenisierungs-Modelle des GHCN Daten über nationale Grenzen hinweg einbringen, während dies beim USHCN nicht der Fall ist. Dies muss noch näher untersucht werden.
Beitrag des USHCN zum GHCN
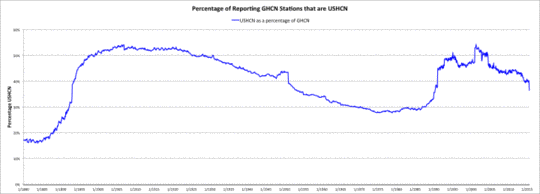
Im Kommentarbereich des o. g. Beitrages wies Tim Ball darauf hin, dass das USHCN eine unverhältnismäßig hohe Datenmenge zum GHCN-Datensatz beiträgt. Die erste Graphik unten zeigt diesen Beitrag im zeitlichen Verlauf. Man beachte, dass das US-Landgebiet (einschließlich Alaska und Hawaii) 6,62% der gesamten Festlandsfläche der Erde ausmacht.
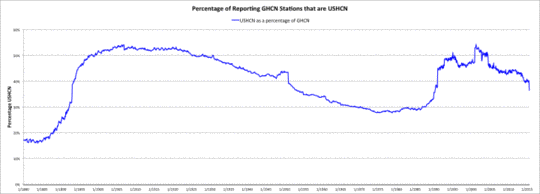
Prozentzahl der Stationen im GHCN, die aus dem USHCN stammen
Wie viele der Daten sind modelliert?
Die folgende Graphik zeigt die Anzahl der Daten, in in der USHCN-Aufzeichnung für jeden Monat von Januar 1880 bis heute verfügbar sind. Auf der Y-Achse ist die Anzahl der Daten liefernden Stationen aufgetragen, so dass jeder Punkt auf der blauen Kurve die Anzahl der Monate repräsentiert, in denen das Monatsmittel aus unvollständigen täglichen Temperaturmessungen berechnet worden ist. USHCN berechnet einen monatlichen Mittelwert auch bei bis zu neun fehlenden Tagen und kennzeichnet den Monat mit einer Rangfolge von „a“ (1 fehlender Tag) bis zu „i“ (neun fehlende Tage). Wie man in der Graphik erkennt, wurden etwa 25% der monatlichen Werte berechnet, wenn einige Tage fehlen. Das offensichtlich jahreszeitliche Verhalten der roten Kurve verlangt nach weiteren Untersuchungen.
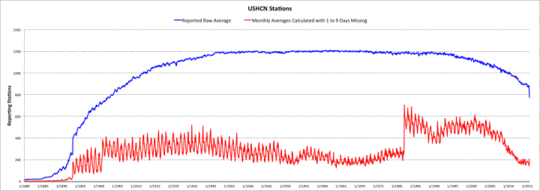
Aufzeichnende USHCN-Stationen
Die dritte Graphik zeigt das Ausmaß, mit dem die Adjustierungs-Modelle die USHCN-Daten beeinflussen. Die blaue Kurze zeigt wieder die für jeden Monat verfügbare Datenmenge im USHCN. Die violette Kurve zeigt die Anzahl von Messungen in jedem Monat, die infolge der Beobachtungszeiten geschätzt worden sind. Etwa 91% der USHCN-Daten weisen eine Beobachtungszeit-Schätzung auf. Die grüne Kurve zeigt die Anzahl von Messungen in jedem Monat, die mittels Homogenisierung geschätzt worden waren. Dies summiert sich zu etwa 99% in der Aufzeichnung. Wie oben schon erwähnt, unterscheiden sich die Schätzungen von GHCN und USHCN für US-Stationen. Im Falle des GHCN sind etwa 92% der US-Aufzeichnungen geschätzt.
Die rote Kurve ist die Anzahl der Daten, die durch eine Kombination von Homogenisierung und GHCN ausgesondert worden sind. Gelegentlich sondert die Homogenisierung die Originaldaten ganz aus und ersetzt sie durch ungültige Werte (-9999). Öfter jedoch werden ausgesonderte Daten durch gültige Werte berechnet aus benachbarten Stationen. Wenn dies geschieht, werden die homogenisierten Daten gekennzeichnet mit einem „E“. GHCN zeigt keine Daten, die auf diese Weise gekennzeichnet sind, weshalb sie in der roten Kurve als ausgesondert erscheinen.
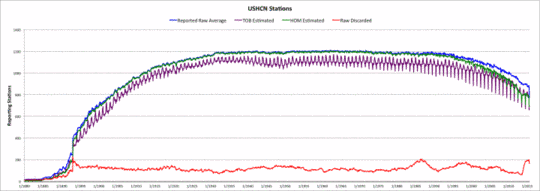
Anzahl der Messstationen und Ausmaß der Schätzungen
Die nächste Graphik zeigt die drei Datensätze (Beobachtungszeit, homogenisiert, ausgesondert) als Prozentzahl der Gesamtzahl der Stationen.
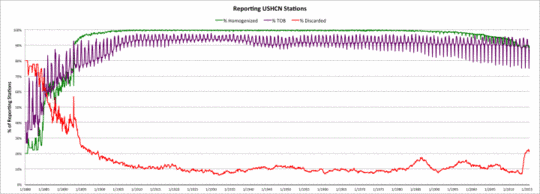
Ausmaß von USHCN-Schätzungen als Prozentzahl aller eingehenden Messstationen.
Die Auswirkung der Modelle
Die fünfte Graphik zeigt die mittlere Änderung der Rohdaten infolge des Beobachtungszeit-Adjustierungsmodells, wenn man diese durch einen geschätzten Wert ersetzt. Die Kurve schließt alle Schätzungen ein, einschließlich der 9% der Fälle, in denen der Beobachtungszeit-Wert gleich dem Wert der Rohdaten ist.
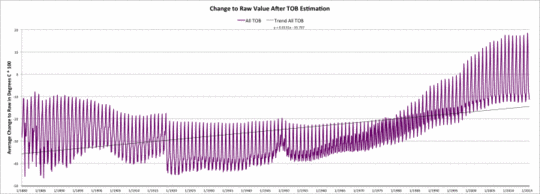
Änderung der USHCN-Rohdatenwerte nach der Beobachtungszeit-Schätzung
Die sechste Graphik zeigt die mittlere Änderung der Rohwerte infolge des Homogenisierungs-Modells. Die Kurve schließt alle Schätzungen ein, einschließlich des 1% aller Werte, in denen der homogenisierte Wert gleich ist dem Rohdatenwert.
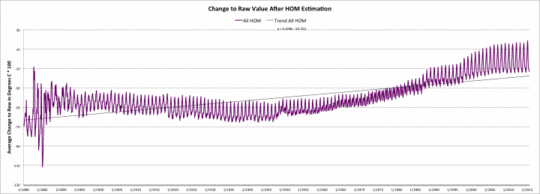
Änderung der USHCN-Rohdaten nach der Homogenisierungs-Schätzung
Unvollständige Monate
Wie zuvor beschrieben berechnet das USHCN ein monatliches Mittel, falls bis zu neun Tage mit Daten fehlen. Die folgende Graphik zeigt die Prozentzahl der Monate, in der die Aufzeichnung unvollständig ist (rote Kurve) sowie die Prozentzahl der Monate, die erhalten bleiben, nachdem man die Adjustierungs-Modelle angewendet hatte (schwarze Kurve). Es ist offensichtlich, dass unvollständige Monate nicht oft ausgesondert wurden.
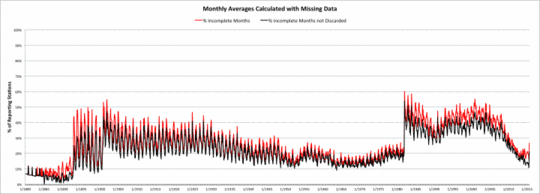
Anzahl der monatlichen USHCN-Mittelwerte, die aus unvollständigen täglichen Beobachtungen berechnet wurden.
Die nächste Graphik zeigt die mittlere Anzahl von Tagen, die fehlten, als die täglichen Aufzeichnungen der Monate unvollständig waren. Nach einer gewissen Volatilität vor dem Jahr 1900 beträgt die mittlere Anzahl fehlender Tage in unvollständigen Monaten zwei (6,5%).
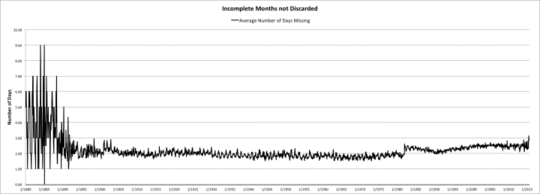
Anzahl der fehlenden Tage bei unvollständigen monatlichen Mittelwerten im USHCN
Ein Wort zum Auffüllen
Die USHCN-Modelle erzeugen Schätzungen für einige fehlende Monate und ersetzen gelegentlich einen kompletten Monat durch eine Schätzung, falls es zu viele Inhomogenitäten gibt. Die letzte Graphik zeigt die Häufigkeit, mit der dies in der USHCN-Aufzeichnung vorkommt. Die blaue Kurve zeigt die Anzahl der nicht existierenden Messungen, die durch den Auffüllungsprozess geschätzt worden sind. Die violette Linie zeigt die Anzahl bestehender Messungen, die ausgesondert und durch den Auffüllungsprozess ersetzt worden sind. Vor dem Jahr 1920 kam es sehr häufig zur Schätzung fehlender Daten. Seitdem ist es öfter zur Ersetzung fehlender Daten gekommen, als dass fehlende Daten geschätzt worden sind.
Aufgefüllte Daten sind in den Adjustierungs-Schätzungen des GHCN nicht enthalten.
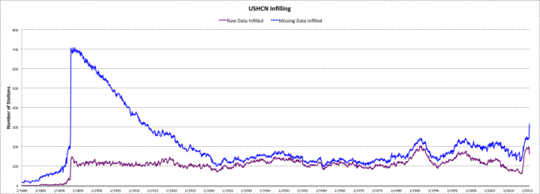
Anzahl der Auffüllung fehlender Daten im USHCN.
Schlussfolgerung
Das US-Festland macht 6,62% der Landfläche der Erde aus, doch stammen von hier 39% der Daten im GHCN-Netzwerk. Von 1880 bis zur Gegenwart wurden etwa 99% aller Temperaturdaten im homogenisierten USHCN-Output geschätzt (mit Unterschieden zu den Original-Rohdaten). Etwa 92% der Temperaturdaten im Beobachtungszeitpunkt-Output des USHCN sind geschätzt worden. Die Adjustierungsmodelle des GHCN schätzen etwa 92% der US-Temperaturen, aber diese Schätzungen passen weder zu den USHCN-Beobachtungszeit-Schätzungen noch zu den homogenisierten Schätzungen.
Die Homogenisierungs-Schätzung führt einen positiven Temperaturtrend von etwa 0,34°C pro Jahrhundert relativ zu den USHCN-Rohdaten ein. Die Beobachtungszeit-Schätzungen führen einen positiven Temperaturtrend von etwa 0,16°C pro Jahrhundert ein. Diese sind nicht additiv. Der Homogenisierungs-Trend steht bereits für den Beobachtungszeit-Trend.
Anmerkung: Das US-Klima-Referenznetzwerk, von Anfang an vorgesehen zur freien Verfügung für JEDWEDE Adjustierung von Daten, zeigt keinerlei Trend, wie ich bereits im Juni 2015 in einem Beitrag mit dem Titel [übersetzt] „Trotz der Versuche, ihn global zu beseitigen, existiert der „Stillstand“ immer noch in ursprünglichen US-Temperaturdaten“ (hier) erläutert habe.
Plottet man die Daten aus jenem Netzwerk, sieht das so aus:
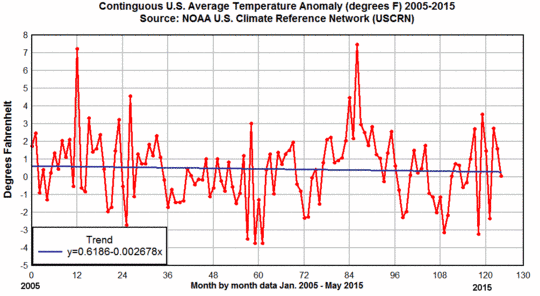
Bemerkungen von Anthony Watts hierzu: Natürlich haben Tom Karl und Tom Peterson von NOAA/NCDC (jetzt NCEI) niemals diese USCRN-Daten an das Tageslicht gebracht, weder in einer Presseerklärung noch in einem Klimazustands-Bericht für die Medien. Sie wurden auf eine Nebenseite der Website verbannt und niemals erwähnt. Wenn es um Behauptungen bzgl. wärmstes Jahr/Monat/Tag jemals geht, werden stattdessen der Öffentlichkeit ausschließlich diese stark adjustierten, höchst unsicheren USHCN/GHCN-Daten in diesen regelmäßigen Berichten gezeigt.
Man fragt sich, warum NOAA NCDC/NCEI Millionen Dollar ausgegeben haben, um ein Klimazustands-Netzwerk für die USA zu erschaffen und dieses dann niemals zur Information der Öffentlichkeit herangezogen wird. Vielleicht liegt es daran, dass es nicht die gewünschten Ergebnisse zeigt?
Link: http://wattsupwiththat.com/2015/09/27/approximately-92-or-99-of-ushcn-surface-temperature-data-consists-of-estimated-values/
Übersetzt von Chris Frey EIKE
Etwa 92% (oder 99%) aller USHCN-Temperaturdaten bestehen aus geschätzten Werten














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"#13: Manfred Oellien sagt:
‚Das gibt es auch auf KLIMASKEPTIGER INFO Aktuelles Meereis ist dort noch ausführlicher.
‚
Danke, daher habe ich den Link. Ich hatte nur vergessen, die URL mit zu liefern:
http://tinyurl.com/o83rr3d
11# K.Schoenfeld.
Das gibt es auch auf KLIMASKEPTIGER INFO Aktuelles Meereis ist dort noch ausführlicher.
Hallo Doc,
Wieso soll ich von Ihrem Link überrascht sein?
In ihrem Link wird von Jahr 1938 als dem Jahr „1938: Unprecedented areas of open waters.“
In diesem Papier sehen Sie (Abb. 4.1) die Überlagerung der Karte vom August 1038 mit den Daten von 1. August und 15. August 2012.
http://tinyurl.com/DMI-NISDC-MapOverlay
Über methodische Fehler in der von Ihnen verlinkten Seite möchte ich mich jetzt nicht äußern, wenngleich diese auffällig sind (zumindest für skeptische Augen, nicht unbedingt für Augen der sogenannten „Skeptiker“).
Danke für das Posten dieser tollen Aufnahme der USS Skate in der Arktis. Das Bild überrascht mich keineswegs. Schon vor 4 Jahren hatte ich bei Eike mit Ihnen et. al. unter anderem wegen des auf den von A.Watts kolportierten HOAX („Skate (SSN-578), surfaced at the North Pole, 17 March 1959. Image from NAVSOURCE“) diskutiert.
Als Auffrischung: hier der Link:
http://tinyurl.com/DrPaulsEiswein
Auch ich bemerke mit zunehmendem Alter, dass man seinem Gedächtnis etwas nachhelfen muss.
Wenn Sie wissen wollen wie es beim Auftauchen der Skate am 1959 im März Nordpol aussah, dann sollten Sie mal nach dem Bericht des damaligen Kapitäns suchen.
Ihr Bild zeigt sicherlich nicht das Auftauchen der Skate am Nordpol 1959: Sie sind einer Fehlinformation aufgesessen. Hätten Sie sich informiert (oder erinnert), würde ich sogar Ihnen zutrauen zu erkennen weswegen das Bild nicht das Auftauchen der Skate am Nordpol 1959 zeigen kann. Aber wie ich schon sagte: für skeptische Augen sollte das offensichtlich sein, nicht unbedingt für die Augen aller sogenannten „Skeptiker“.
P.S.: vom Eiswein lasse ich meine Finger: bringt nur Stress in meinen Kopf.
Dänen lügen nicht:
http://tinyurl.com/d87ql2d
die Seite, auf der diese Bilder zu finden sind, ist zwar abgeschaltet, aber einige der Links zum Meereis Arktis/Antarktis liefern noch aktuelle Werte
Werter Herr Ketterer,
danke für den Link. leider enthält diese Arbeit keinerlei Fehlerangaben. das macht sie in meinen Augen für die Rekonstruktion der Meereisausdehnung der Arktis nicht besonders wertvoll.
Abb.12 zeigt eine Rekonstruktion, die auch einen tel der mittelalterlichen Warmzeit umfaßt. Diese war deutlich wärmer als heute. Da ist aber die Eisbedeckung etwa genauso groß (Augenmaß), wie während der nachfolgenden kleinen Eiszeit. das ist schlicht nicht glaubwürdig.
MfG
Hallo Doc,
Berechnen Sie doch mal wie hoch die Wahrscheinlichkeit für diesen Fall ist:
In 4 von 9 aufeinanderfolgenden Jahren liegen die „Ausreißer“ der minimalen Meereisausdehnung außerhalb des von Ihnen erwähnten Bereiches der 2 Standardabweichungen der Messreihe von 1981 bis 2010? (Der Einfachheit halber nehmen wir an die Einzeljahre seien unabhängig voneinander).
Größer 50%
Größer 3%
Größeer 1%
Kleiner 0,1%
?
#7: F.Ketterer, dann wird Sie vielleicht das überraschen:
http://tinyurl.com/7nqav5x
und erstaunlich dass 1959 am Nordpol ein Uboot auftauchen konnte
http://tinyurl.com/p3agf4x
mfG
Sehr geehrter Herr Urbahn,
zu # 6
die Daten der vergangenen 140 Jahre finden sie hier in Abb. 2:
http://tinyurl.com/HistArcticSeaIce
Ich kenne einen der Autoren persönlich, und zumindest er ist nicht dafür bekannt Humbug zu publizieren. Konkrete Zahlen für einzelne Jahre können Sie sich auch ergoogeln. Auch wenn ein Vergleich der Daten aus der Zeit vor den Satelliten mit den Satellitendaten Unschärfe mit sich bringt: Allem Anschein nach ist meine Aussage nicht falsch.
Hallo Doc (#5) ist ja nett, dass Sie darauf hinweisen, dass auch 2015 die Meereseisausdehnung (Arktis) einige Wochen nicht mehr im Konfidenzintervall 2sigma lag und somit eine „Ausreißer“-Jahr war. Seltsam nur, dass diese „Ausreißer“-Jahre ich in den vergangenen 9 (glaziologischen) Jahren häufen.
Werter Herr Ketterer,
so, so Sie kennen also die Meereisausdehnung der letzten 200 Jahre ( ich unterstelle Sie reden nur über etwas, was Sie wirklich wissen. Seien sie doch so freundlich und nennen Sie die Meereisausdehnung des Jahres 1927 oder 1942 oder 1873.
MfG
#4:aber Frau Ketterer, gerade weil es im Semptember so wenig war, IST doch die Eiszunahme so eindrucksvoll.
Denken Sie dochmal in so kurzer Zeit auch 2015 entsteht 1,365 Millionen km2 Eis,
das ist immerhin
3,823529411764706 mal die Fläche der Bundesrepublik Deutschland,
in der so viele Hasenfüße vor der Erderwärmung sitzen. Also in einem einzigen Monat!!!
Die Eisausdehnung liegt damit bereits im Bereich der 2 Standardabweichung von
1981 bis 2010.
Da kann einem ja richtig heiß werden,
vor dieser unglaublichen, kaum vorstellbaren Eisproduktion.
Ich vermute, dass das mit der Kälte da oben irgendwie zusammen hängen muss,
was meinen Sie?
PIK wird sicher nachweisen, dass er die Wärme ist
die das Eis so wachsen lässt.
Die kriegen ja Geld für diese intellektuelle Leistung.
mfG
#1: Dr.Paul sagt: am Samstag, 10.10.2015, 17:50
passend zu den „Klimawerten“ und der katastrophalen „Hitze“ in diesem Sommer ist wiedermal ein Rekordeiszunahme am Nordpool vom Minimum sowohl 2015, besinders natürlich gegenüber dem Minimum von 2012.
http://tinyurl.com/mach5ge
[. . . ]
##########################
Hallo Doc,
Sie haben das mit der Grafik allem Anschein nach nicht verstanden: klicken Sie rechts auf die Jahreszahlen und Sie sehen die entsprechenden Kurven:
– Seit 2000 (dann wurde mir die Klickerei zu viel) war zum 9. Oktober nur in den Jahren 2012, 2007 und 2011 weniger Meereis in der Arktis als 2015.
-2008 hatte das Eis schneller zugenommen.
– Im Spetember 2015 hatten wir die viertniedrigste Meereisausdehnung in der Arktis seit langer Zeit (mehr als 200 Jahre).
Was reden Sie also von Rekordeiszunahme.
#1: Verehrter Herr Dr. Paul,
die viel besungene Logik der Wohlstands-Grünen führt alles zurück, wohin immer die wollen. Die sind pervers. Die machen aus jedem Esel ein Rennpferd, mit sanfter Gewalt. Diese Spezies ist dem Ungehorsam gehorsam. [Grübel!?] Ja, Sie lesen richtig.
Mit freundlichen Grüßen
pardon 2,4 Millionen km2 natürlich!
passend zu den „Klimawerten“ und der katastrophalen „Hitze“ in diesem Sommer ist wiedermal ein Rekordeiszunahme am Nordpool vom Minimum sowohl 2015, besinders natürlich gegenüber dem Minimum von 2012.
http://tinyurl.com/mach5ge
Hierzu beträgt die Differenz genau heute ca. 2,4 km2,
das ist für die, die sich das schwer vorstellen können
das 6 bis 7-fache der Fläche der Bundesrepublik Deutschland.
Hier erkennt man wieder die brillante Denkfähigkeit aller Grünen,
die vermutlich das viele Eis auf die Erderwärmung zurückführen werden.
mfG