… in neun von zehn Fällen deutet unser Modell darauf hin, dass der im 20. Jh. vom Menschen verursachte Treibhausgasausstoß das Risiko von Überschwemmungen in England und Wales im Herbst 2000 um mehr als 20% erhöht hat und in zwei von drei Fällen sogar um mehr als 90%.
Zu Beginn meiner Analyse mußte ich erst einmal das Gesetz von der Güte wissenschaftlicher Autorenschaft zu Rate ziehen (Qualitative Law of Scientific Authorship). Es ist ein allgemeingültiges Gesetz und lautet:
Q ca = 1 / N^2
wobei Q die Güte der wissenschaftlichen Veröffentlichung ist, und N^2 das Quadrat der Anzahl der aufgelisteten Autoren. Noch wichtiger ist aber, dass wir uns erst einmal folgender Frage zuwenden: Wie viele historische englische Überschwemmungen haben die Autoren ausgewertet, um zu ihrem Urteil über das Überschwemmungsrisiko in England zu kommen?
Seltsamerweise haben sie überhaupt keine historischen Daten von Überschwemmungen ausgewertet. Kein Scherz, auch keine trickreiche Behauptung! Folgendermaßen sind sie vorgegangen:
Sie haben ein einzelnes Computer-Klima-Modell mit jahreszeitlicher Auflösung (HadAM3-N144) benutzt, um 2 268 Einzeljahre mit synthetischen Herbstwetter-Daten zu erzeugen. Die beobachteten Klimavariablen vom April 2000 (Temperatur, Luftdruck, usw.) wurden als Eingangswerte für das HadAM3-N144 Modell benutzt. Damit wurde das Modell gestartet und man ließ es mehrere tausend Male sich wiederholen. Die Auhoren von Pall2011 nennen diese vom Computer erzeugten 2 268 Einzeljahre die „Daten“ des “A2000 Klimas”. Ich werde es das „A2000 synthetische Klima“ nennen, damit keine Verwechslung mit der Wirklichkeit stattfindet.
Das „A2000 synthetische Klima“ ist ein ganzes Universum von mehreren tausend Einzeljahres-Rechenergebnissen aus einem einzigen Computermodell (mit einem festen Satz von internen Parameter-Einstellungen). Vermutlich sind die benutzten Parameter im Modell gut abgebildet … Das heißt noch lange nicht, dass deren wirkliche Variation im Modell gut abgebildet wäre. Aber ich schweife ab.
Die 2.268 fache Modellsimulationen für ein Jahr des A 2000 Herbstwetter-Datensatzes wurden dann in ein zweites, viel einfacheres Modell eingegeben, in ein “Niederschlags-Ablauf Modell” (P-R). Dieses P-R Modell schätzt die Flußpegel in SW-England und Wales ab. Es geht von den Niederschlägen in den Gitternetzkästchen aus.
Anschließend wurde das P-R Modell mit Hilfe der Ergebnisse aus einem dritten Klima-Modell kalibriert, dem ERA-40 Computermodell, das historische Daten reanalysiert. Wie die anderen Modelle wirft das ERA-40 die Variablen bezogen auf ein globales Gitternetz aus. Die Autoren haben multiple lineare Regression eingesetzt, um das P-R Modell zu kalibrieren, dergestalt, dass zwischen den angezeigten Flußpegelständen der 11 untersuchten englischen Niederschlagsmessungen mit den ERA-40 computerausgewerteten Gitternetzdaten die beste Übereinstimmung erzielt wurde.
Wie gut die Übereinstimmung mit der Wirklichkeit zusammenpaßt? Keine Ahnung, darüber haben sie nichts gesagt …
Also unter dem Strich kommen irgendwelche Daten heraus. Aber diese Daten wurden überhaupt nicht analysiert. Stattdessen wurden sie benutzt, um die Parameter des P-R Modells einzustellen.
Fassen wir ein Zwischenergebnis zusammen:
• Wirkliche Daten vom April 2000 und wirklichen Muster von Bodentemperaturen, Luftdruck und anderen Variablen sind in ständiger Wiederholung als Eingabedaten für 2 268 einjährige Wetterberechungen benutzt worden. Die Ergebnisse werden das „A2000 synthetische Klima“ genannt. Dieses 2 268fache einzeljährige Wetter wurde benutzt als Eingabe für ein zweites Modell zur Errechnung des Abflusses des Niederschlags über die Flüsse. Dieses P-R Modell wurde dann auf die beste Übereinstimmung mit den Reanalyse-Ergebnissen der auf das Gitternetz bezogenen Niederschläge getrimmt. Mit Hilfe der A2000 Wetterdaten erzeugt das P-R Modell 2 268 Jahre mit synthetischen Flußpegelständen und Hochwasserdaten.
So! Das war die erste Halbzeit.
In der zweiten Halbzeit haben die Autoren die Ergebnisse von vier globalen Zirkulationsmodellen (GCM) benutzt. Daraus haben sie errechnet, wie eine synthetische Welt ausgesehen hätte, wenn es keine anthropogenen Klimaänderungs-Antriebe gegeben hätte. Oder in den Worten von Pall2011: jedes der vier Modelle erzeugte “eine hypothetische Lage, welche die “Erwärmung der Erdoberfläche” abbildete, wie sie vielleicht ohne anthropogene Treibhausgasemissionen eingetreten wäre (A2000N).”
Und so beschreiben sie die Veränderungen zwischen A2000 and A2000N:
In der A2000N-Lage wird versucht, einen hypothetischen Herbst 2000 im [HadAM3-N144] Modell abzubilden, indem die A2000-Lage wie folgt verändert wird: Treibhausgasemissionen sind auf die Mengen des Jahres 1900 zurückgesetzt; SSTs [Temperaturen über der Meeresoberfläche] werden verändert, indem der den Treibhausgasemissionen zurechenbare Erwärmungsanteil herausgerechnet wird, wobei die Ungewißheit in Rechnung gestellt ist; das Meereis ist gleichermaßen verändert, indem eine einfache empirische Meersoberflächen-Lufttemperatur-zu-Meereis-Beziehung hergestellt wird, die aus beobachteten Lufttemperaturen an der Meeresoberfläche und dem Meereis bestimmt wird.
Eine interessante Auswahl von Veränderungen, das sollte man sich auf der Zunge zergehen lassen …
Treibhausgasemissionen für das Jahr 1900, kühleres Meer, mehr Meereis, aber keine Änderung bei den Temperaturen über dem Land … Sieht so aus, als ob es auf ein wärmeres Großbritannien in einem kälteren Ozean hinausliefe. Und es sieht so aus, dass dadurch bestimmt die Niederschläge beeinflußt würden. Aber lassen wir uns nicht von den logischen Ungereimtheiten ablenken …
Dann haben sie das Original-Klimamodell (HadAM3-N144) mit den Startbedingungen aus den vier GCM-Modellen benutzt und mit den gleichen Anfangsstörungen aus A2000 einige weitere Tausende von Ein-Jahres-Simulationen erzeugt. Mit anderen Worten: gleiches Modell, gleiche Startdaten, unterschiedliche Startbedingungen aus Ergebnissen der vier GCMs. (Gerade fällt mir auf, dass die synthetischen Wetterdaten am 1. April beginnen!). Das Ergebnis heißt A2000N synthetisches Klima, obwohl sie das „synthetisch“ weglassen. Ich vermute mal, das „N“ steht für “no warming”.
Diese mehrere Tausende von Jahren an modelliertem Wetter, das synthetische A2000N-Klima, sieht dann wie das synthetische A2000-Klima aus. Die Daten sind in das zweite Modell eingegeben worden, in das P-R Modell, das mit Hilfe des ERA-40 Reanalyse-Modells abgestimmt worden war. Daraus ergab sich dann eine weitere Folge von Flußpegel- und Überschwemmungsvorhersagen.
Zwischenergebnis:
• Zwei Datensätze von Computer-erzeugten, vollständig und ausschließlich simulierten englischen Flußpegel- und Überschwemmungsdaten wurden errechnet. Keiner der Datensätze ist auf tatsächliche Messdaten bezogen, auch nicht auf Bluts-, angeheiratete oder auf sonstige verwandtschaftliche Nähe. Doch um fair zu sein: bei einem der Modelle sind die Eingangswerte mit Hilfe eines Vergleichs zwischen echten Meßdaten und den Ausgabedaten eines dritten Modells gesetzt worden. Einer der beiden Datensätze wird von den Autoren als “hypothetisch” beschrieben, der andere als “realistisch”.
Zum Schluss vergleichen die Autoren die beiden Datensätze. Heraus kommt das Urteil, dass der Mensch die Ursache ist:
Der genaue Umfang des anthropogenen Beitrags bleibt ungewiss, aber in neun von zehn Fällen deuten die Ergebnisse unseres Modells darauf hin, dass die anthropogenen Treibhausgasemissionen im 20. Jh. die Risiken von Überschwemmungen in England, wie sie sich im Herbst 2000 ereigneten, um mehr als 20% und in zwei von drei Fällen um mehr als 90% erhöht haben.
Zwischenergebnis:
• Die Autoren haben schlüssig gezeigt, dass in einem Computer-Modell für Südwest-England und Wales im synthetischen Klima A die synthetischen Überschwemmungen eine statistisch höhere Gefährdung darstellen als im synthetischen Klima B.
Ich bin mir nicht sicher, was ich dazu sagen soll, weil die Autoren auch nicht viel dazu sagen.
Ja, sie zeigen, dass ihre Ergebnisse in sich ziemlich konsistent sind und sie stimmen auch mehr oder minder darin überein, dass sie nicht außerhalb der Grenzen ihrer Bedingungen liegen, und dass die Autoren die Ungewissheit durch Monte-Carlo Eingaben abgeschätzt haben, und dass sie mit den Ergebnissen zufrieden sind … Aber in Anbetracht der Ungewissheiten, die sie NICHT einbezogen haben – nun, daraus können Sie Ihre eigenen Schlüsse ziehen hinsichtlich der Frage, ob die Autoren ihre Untersuchung unter Beachtung wissenschaftlicher Grundsätze durchgeführt haben.
Nur ein paar Fragen, die diese Analyse aufwirft:
FRAGEN, AUF DIE ICH ÜBERHAUPT KEINE ANTWORT WEISS
1. Wie wurden die vier GCMs ausgewählt? Wieviel Ungewißheit wurde dadurch eingebracht? Was würden vier andere GCMs ergeben?
2. Wie hoch ist die Gesamt-Ungewißheit, wenn das gemittelte Ergebnis eines Computer-Modells als Eingabe in ein zweites Computer-Modell genommen würde, wenn weiter dessen Ergebnis als Eingabe für ein drittes Computer-Modell genommen würde, das gegen ein unabhängiges Klima-Reanalyse-Computer-Modell kalibriert würde?
3. Bei den über 2000 Einjahres-Simulationen wissen wir, dass sie den HadAM3-N144 Modellraum für eine vorgegebene Einstellung der Modell-Parameter benutzt haben. Aber umfassen die unterschiedlichen Modelle den tatsächlichen Wirklichkeitsraum vollständig? Und wenn ja, stimmt die Verteilung der Ergebnisse mit der Verteilung der tatsächlichen Klimavariationen überein? Hier handelt es sich um eine unausgesprochene Annahme, die für die Aussage „in neun von zehn Computerläufen“ verifiziert werden muss, um stehen bleiben zu können. Vielleicht sind neun von zehn Computerläufen unrealistischer Mist, vielleicht auch reines Gold … Ich setze aber auf ersteres, es gibt ja keine Möglichkeit für die Entscheidung, was wahr und was falsch ist.
4. Ziehen wir die Warnungen über die Datenquellen (siehe unten) in Betracht, “dass es selten mit Sicherheit ausreicht, die Flußpegelmeßdaten so zu nehmen, wie sie sind”. Welcher Qualitätskontrolle wurden die Flußpegelmeßdaten unterworfen, um die Genauigkeit beim Setzen der P-R-Modelldaten sicher zu stellen? Im Allgemeinen haben die Überschwemmungen zugenommen, weil immer mehr Land wasserundurchlässig gemacht worden ist (Straßen, Parkplätze, Überbauung), und weil der ursprüngliche Bodenbewuchs beseitigt worden ist. Deshalb wird die Abflussmenge von vorgegebenen Niederschlägen erhöht, und das bringt einen Trend zu erhöhtem Abfluss in die Ergebnisse ein. Ich weiß nicht, ob das in der Analyse berücksichtigt wurde, trotz der Tatsache, dass die Flußpegelstandsmessungen zum Kalibrieren des P-R-Modells benutzt wurden.
5. Da das P-R-Modell mit Hilfe der ERA-40-Reanalyse-Ergebnisse kalibriert wurde, wie gut gibt es die tatsächlichen jährlichen Flußmengen wieder, und wie viel Ungewißheit steckt in den errechneten Ergebnissen?
6. Ausgehend vom Starttag 1. April für jedes Jahr: wie gut prognostiziert das im Papier skizzierte Verfahren – Beginn des HadAM3-N144 jeweils am 1. April zur Vorhersage der Niederschläge im Herbst – die ungefähr 80 Jahre Niederschläge, für die es tatsächliche Messdatenaufzeichnungen gibt?
7. Ausgehend vom Starttag 1. April für jedes Jahr, wie gut prognostiziert das im Papier skizzierte Verfahren -Beginn des HadAM3-N144 jeweils am 1. April zur Vorhersage der Pegelstände und Überschwemmungen – die Pegelstände und Flussmengen, für die es tatsächliche Messdatenaufzeichnungen gibt?
8. Nehmen wir an, in einem Glücksspiel sollen die Ergebnisse von vier unterschiedlichen Computer-Modellen mit der Wirklichkeit verglichen werden. Drei müssen falsch sein, wenn eine Vorhersage richtig ist, weil vier verschiedene Prognosen möglich sind. Alle vier können aber auch falsch sein. Der Erfolg einer Wette soll proportional zur Korrelation des Modells mit der Wirklichkeit sein.
Wie hoch ist die Erfolgserwartung mathematisch bei einer 1$-Wette auf eines der Modelle in diesem Spiel … und wie hoch ist die Ungewissheit für diese Erfolgserwartung? Wenn vier Modelle vorgegeben sind, wird dann eine Wette auf den Durchschnitt der Modelle meine Gewinnchancen verbessern? Und was unterscheidet diese Frage von den Schwierigkeiten und Unbekannten, die in der Abschätzung nur dieses einen Teils der gesamten Ungewissheit der Studie liegen, wenn man nur die Informationen besitzt, die in der Studie benannt worden sind?
9. Sechs unterschiedliche Klimamodelle wurden einbezogen, jedes davon hat unterschiedliche Größen der Gitternetzkästchen und Koordinaten. Es gibt unterschiedliche Methoden zur Durchschnittsbildung von einem Gitterkästchen-Schema mit einer bestimmten Größe zu einem anderen mit anderer Größe. Welche Methode wurde benutzt und wie hoch ist die Ungewissheit, die bei diesem Schritt eingeführt wurde?
10. Die Studie beschreibt die Benutzung eines bestimmten Modells, um zwei Datensätze von jeweils 2000+ Einzeljahren mit synthetischem Wetter zu erzeugen … wie unterschiedlich wären die Datensätze, wenn ein anderes Klimamodell benutzt würde?
11. In der Annahme, dass die GCMs andere Niederschlagsmuster erzeugen als das ERA-40 Reanalyse-Modell, und in der Annahme, dass das P-R-Modell auf die Ergebnisse des ERA-40-Modells kalibriert ist, wieviel Ungewißheit wird dadurch erzeugt, dass die gleichen ERA-40 Kalibrierungseinstellungen mit den GCM-Ergebnissen benutzt werden?
12. Haben die Autoren wirklich die A2000N Simulationen mit der Abkühlung des Ozeans gestartet und nicht des Landes, wie sie anscheinend sagen?
Wie man sieht, gibt es eine Menge von wichtigen Fragen, die derzeit unbeantwortet sind.
Nach erneutem Lesen meines Beitrags möchte ich noch klarstellen: Ich spotte nicht über die Studie, weil sie etwa falsch wäre. Ich spotte, weil die Studie so weit von der Wissenschaftlichkeit entfernt ist, dass keine Hoffnung besteht, je zu erkennen ob sie falsch oder wahr ist. Die Autoren haben uns nicht die geringste notwendige Menge von Informationen gegeben, um auch nur im Ansatz eine Beurteilung der Tragfähigkeit der Hypothese zu ermöglichen.
KOMMEN WIR MAL AUF DIE LANGWEILIGEN ALTEN DATEN ZURÜCK …
Wie man weiß, liebe ich Fakten. Ich pflichte Robert Heinlein bei:
Was sind die Fakten? Immer wieder muss nach den Fakten gefragt werden. Wunschdenken muss beiseite geschoben und göttliche Eingebung ignoriert werden. Was die „Sterne sagen“ gilt nicht, Meinungen sind zu vermeiden, Rücksichtnahme auf das, was der Nachbar denkt, ebenso. Man kümmere sich nicht um das “Urteil der Geschichte”. Was sind die Fakten und bis auf welche Dezimalstelle sind sie genau? Man segelt immer in eine ungewisse Zukunft. Nur Fakten haben Bestand. Holt die Fakten!
Das hat er 1973 geschrieben, was er ausließ, war “Hüte Dich vor Computermodell-Ergebnissen.” Also haben ich die Pegelstandsmessungen angesehen, wie sie in Pall2011 angegeben werden. Ich bin bis zum Teil gegangen, wo es heißt: (Hervorhebung von Willis Eschenbach):
Appraisal of Long Hydrometric Series [Beurteilung von Langzeit- Wasserstandsaufzeichungen]
… Die Genauigkeit der Daten und Konsistenz kann ein Hauptproblem bei vielen frühen Wasserstandsaufzeichnungen sein. Im Verlauf des 20. Jh. wurden die Instrumentierungen und die Aufzeichnungseinrichtungen verbessert, aber diese Verbesserungen selbst können Inhomogeneitäten in die Zeitreihen bringen – die noch verstärkt werden können durch Veränderungen (manchmal nicht dokumentiert) des Standorts der Meßstation oder der angewandten Methoden der Datenverarbeitung. Zusätzlich wurde die Einwirkung des Menschen auf das Fließverhalten der Flüsse und die Muster der Grundwasserspeisung immer ausgedehnter, besonders in den vergangenen 50 Jahren. Der sich daraus für das Fließverhalten der Flüsse und die Grundwasserspiegel ergebende Zustand kann zusätzlich noch durch die weniger sichtbaren Auswirkungen der Veränderungen der Bodennutzung beeinträchtigt werden; obgleich diese in einer Anzahl von wichtigen experimentellen Wassereinzugsbereichen im Allgemeinen quantifiziert worden sind, entziehen sie sich einer leichten Quantifizierung.
Wie in den meisten Langzeitaufzeichnungen von natürlichen Phänomenen lauern in der in der Studie benutzten Datenaufzeichnung auch Fallen für den Unaufmerksamen. Und in der Tat sagen die Autoren am Schluss des Abschnitts:
Man muss daher richtigerweise sehen, dass die Erkennung und Interpretation von Trends besonders stark auf der Verfügbarkeit von Referenz- und räumlicher Information beruht, um die Auswirkungen der Klimaveränderung von der Einwirkung eine Reihe von anderen Faktoren zu unterscheiden;>
Genau das haben sich die Autoren von Pall2011 zu Herzen genommen. Sie haben nämlich den Daten überhaupt keine Gelegenheit gegeben, auch nur ein einziges Wort zu sagen …
Um eine noch ernsthaftere Anmerkung zu machen: Weil mit diesen Daten die “Klimavariabilität” des P-R-Modells kalibriert wurde, haben deswegen die Pall2011-Leute den Rat des Verwalters der Daten befolgt? Auch davon sehe ich überhaupt nichts.
Ich konnte nur feststellen, dass die Flußpegeldaten überhaupt keine Hilfe für mich sein konnten. Ich war nur verwirrt wegen der impliziten Behauptung in der Studie, dass extreme Niederschläge in England zunähmen. Ich glaube, die Autoren wollen sagen, dass der Klimawandel mehr Überschwemmungen mit sich bringt, und das kann nur passieren, wenn es mehr Starkregen in England gibt.
Glücklicherweise haben wir da eine andere interessante Datenreihe. Dummerweise wieder vom Hadley Centre, es ist die Hadley UK Precipitation Datenreihe von Alexander und Jones; ja ja, es ist Phil Jones (HadUKP). Und glücklicherweise zeigt die herangezogene Studie überhaupt nichts Außergewöhnliches. Unglücklicherweise, aber irgendwie unvermeidlich, benutzt sie ein komplexes System der Durchschnittsbildung. Glücklicherweise unterscheiden sich die durchschnittlichen Ergebnisse nicht sehr von einem einfachen Durchschnitt, soweit unser Interesse hier betroffen ist. Unglücklicherweise gibt es keine Kontrolldaten, so dass man nicht exakt feststellen kann, was aus einem bestimmten Extremwetterereignis in einem bestimmten Gebiet zu einer bestimmten Zeit gemacht worden ist.
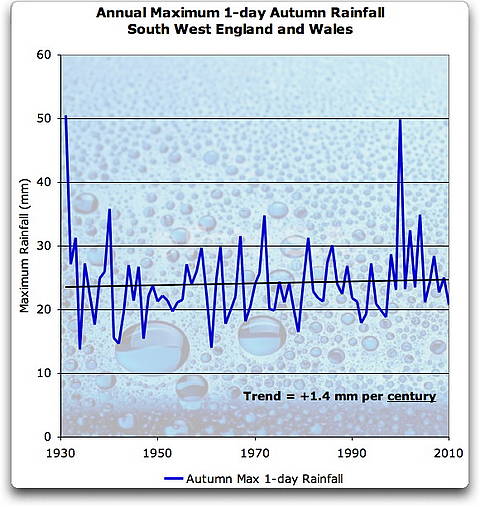
Jedenfalls ist das das Beste, was wir haben. Die gesamten täglichen Niederschlagsmengen sind für Bereiche in England aufgelistet, und einer dieser Bereiche ist South West England and Wales. Damit werden die Probleme der Durchschnittsbildung für größere Gebiete vermieden. Die Abbildung 2 zeigt das Herbstmaximum eines eintägigen Niederschlags in Südwest-England und Wales. Das war die Gegend und der Zeitraum, die in der Pall2011 Studie im Hinblick auf die Herbst-2000-Überschwemmungen untersucht wurde:
http://wattsupwiththat.files.wordpress.com/2011/02/max-1-day-autumn-rain-sw-england-wales.jpg
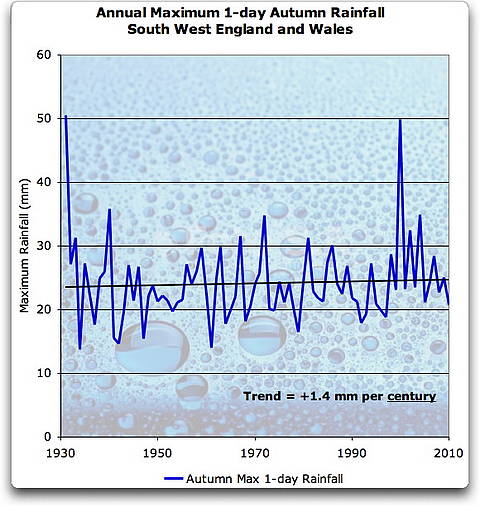
Abbildung 2. Herbstmaximum eines 1-tägigen Niederschlags, SW England und Wales, Sept-Okt-Nov. Der geringe Trend ist statistisch kaum von Null zu unterscheiden.
Der in dieser Aufzeichnung gezeigte Starkregen ist typisch für Aufzeichnungen von Extrema. In der Natur haben die Extrema selten eine Gauss’sche Normalverteilung. Stattdessen enthalten die Aufzeichnungen einige sehr große Werte, auch dann, wenn man nur nach Extrema Ausschau hält. Die Art des Starkregens, der zu den Überschwemmungen von 2000 führte, kann in Abbildung 3 betrachtet werden. Diese Abbildung halte ich für eine warnendes Beispiel, weil bei einer Verschiebung des Beginns der Darstellung um ein Jahr später, der eintägige Niederschlag bei weitem der größte im Bericht wäre.
Für die 70 aufgezeichneten Jahre gibt es keine Anzeichen für zunehmende Überschwemmungsrisiken als Folge von Klimafaktoren. In Pall2011 wurde klar gezeigt, dass in zwei von drei Jahren im synthetischen Klima B das Risiko einer synthetischen Herbstüberschwemmung in einem synthetischen Südwest-England und Wales um 90% zunimmt, gemessen am synthetischen Überschwemmungsrisiko im synthetischen Klima A.
Entsprechend den Messdaten gibt es kein Anzeichen für Zunahmen von Starkregen im Herbst in Südwest-England und Wales. Es ist also sehr unwahrscheinlich, dass wir über das uns bekannte Südwest-England und Wales sprechen … Damit erhält die String-Theorie von multiplen parallelen Universen eine neue Bedeutung, vermute ich mal.
IMPLIKATIONEN DER VERÖFFENTLICHUNG DIESER STUDIE
Es ist verstörend, dass NATURE diese Studie veröffentlich hat. Es gibt nur diesen einen Weg, über den diese Studie eine sehr geringe Chance für wissenschaftliche Anerkennung hätte haben können. Wenn nämlich die Autoren die exakten Datensätze und den Code veröffentlicht hätten, mit dem sie die Ergebnisse erzeugten. Eine reine Beschreibung der Verfahren ist ausgesprochen inadäquat für jegliche Analyse der Gültigkeit von Ergebnissen.
Um auch nur eine kleine Hoffnung auf Gültigkeit zu hegen, ist als absolutes Minimum die elektronische Veröffentlichung der A2000 und A2000N Klimadaten in zugänglicher Form nötig, zusammen mit den Resultaten einfacher Tests der einbezogenen Modelle (d. h. Computer-Vorhersagen von Herbstüberschwemmungen zusammen mit tatsächlichen Flußpegelständen). Darüberhinaus müssen die benutzten ex-ante Kriterien für die Auswahl der vier GCMs und des Leitmodells erklärt werden. Auch die Antworten auf meine oben erhobenen Fragen. Nur dann kann man die Studie annäherungsweise für wissenschaftlich halten. Und selbst dann, wenn man sich die derzeit nicht zugänglichen A2000 und A2000N synthetischen Klimata anschaut, könnte es sein, dass diese keine Ähnlichkeit mit irgenwelcher Wirklichkeit haben, hypothetisch oder sonstwie …
Im Endergebnis sehe ich die Verantwortung bei der Fachzeitschrift NATURE. Weil derzeit das Beste, was wir über die Studie sagen können ist: a) wir haben keine Möglichkeit festzustellen, ob sie stimmt. Und b) sie ist nicht falsifizierbar … Wenn das auch gut im “Journal of Irreproducible Results“ aussieht, bedeutet es nichts Gutes für eine Zeitschrift wie NATURE, die sich mit fachbegutachteter Wissenschaft befaßt.
Willis
PS – Bitte verstehen Sie das nicht als Schimpfen auf Computermodelle. Ich habe Computer seit 1963 programmiert, länger als manche Leser hier leben. Ich kann in R, C, VBA, Pascal schreiben, und ich kann in einem halben Dutzend anderer Computer-Sprachen lesen und (langsam) schreiben. Ich benutze Computer-Modelle, habe einige gelegentlich geschrieben und verstehe die Stärken, Schwächen und Grenzen vieler Computer-Modelle von Echtwelt-Systemen. Mir ist wohlbewußt, dass “alle Modelle falsch, einige aber nützlich sind”. Deshalb benutze ich sie, vertiefe mich in sie und schreibe gelegentlich welche.
Mein Argument ist, dass man ohne wirkliche Überprüfung der Ergebnisse aus Modellrechnungen gegen die Wirklichkeit mit den genauesten vorstellbaren Tests nur ein komplexes Spielzeug von unbekannter Aussagekraft hat. Und sogar nach ausgedehnten Tests können Modelle sich irren gegenüber der realen Welt. Deshalb läßt Boeing immer noch Testflüge mit neuen Flugzeugen durchführen, obgleich die teuersten Computer-Modelle eingesetzt werden, und trotz der Tatsache, dass die Modellierung von Luftströmungen um ein Flugzeug um Größenordnungen einfacher ist als die Modellierung des globalen Klimas.
Andere und ich haben an anderer Stelle gezeigt, (Lesen Sie hier, Sehen Sie diesen Kommentar hier, und die Grafik hier), dass die vom NASA-Glanz-und-Gloria-Klimamodell (dem GISS-E GCM) errechnete jährliche globale Durchschnittstemperatur mit 98%iger Genauigkeit mit folgender einfacher, einzeiliger Gleichung, die nur eine Variable benutzt, errechnet werden kann:
T(n) = [lambda * Forcings(n-1)/tau + T(n-1) ] exp(-1/tau)
wobei T(n) die Temperatur zum Zeitpunkt n ist, und lambda und tau die Konstanten der Klima-Sensitivität und der Verzögerung sind …
Angesichts der Komplexität des Klimas ist es sehr wahrscheinlich, dass das GISS-E Modell falsch und noch nicht einmal nützlich ist. Und wenn man vier von derartigen GCMs auf das Problem der englischen Überschwemmungen ansetzt, macht es die Genauigkeit der Ergebnisse bestimmt nicht besser …
Das Problem sind nicht die Computer-Modelle. Das Problem ist die Fachzeitschrift NATURE, die versucht, die Endergebnisse aus einer langen Computer-Modell-Perlenkette, bestehend aus gezielt ausgesuchten, unausgetesteten, nicht verifizierten, nicht untersuchten Computer-Modellen, als gültige, falsifizierbare, fachbegutachtete Wissenschaft zu verkaufen. Man mag mich ja verrückt nennen: Aber wenn die Ergebnisse von vier Computer-Modellen, die in ein fünftes Computer-Modell eingespeist werden, dessen Ergebnisse wiederum in ein sechstes Computer-Modell gehen, das gegen ein siebtes Computer-Modell kalibriert wird, dann als Resultate gegen eine Reihe von anderen Resultaten aus einem fünften Computer-Modell verglichen werden, aber nach Anwendung anderer Parameter, um zu beweisen, dass das Überschwemmungsrisiko sich wegen zunehmender Treibhausgase geändert hat, … nun, wenn man so etwas macht, dann muss man schon mehr tun, als mir nur zuzuwinken, um mich zu überzeugen, dass das Überschwemmungsrisiko nicht nur eine mögliche Abbildung der Realität ist, sondern auch eine genügend genaue Abbildung der Realität, um zukunftsgerichtetes Handeln zu leiten.
* Der Beitrag findet sich hier
Ergänzende Information finden Sie hier, darin sind die Leitgedanken des Papiers enthalten.
Willis Eschenbach , den Originalbeitrag finden Sie hier
Die Übersetzung besorgte Helmut Jäger EIKE
**Die Ergänzungsinformation dazu finden Sie hier, sie enthält den größten Teil des Konzeptes dieses Papiers














{kind=link}
{kind=link}
{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"„Andere und ich haben an anderer Stelle gezeigt, (Lesen Sie hier, Sehen Sie diesen Kommentar hier, und die Grafik hier)“
Ist der Dritte oder vierte Abschnitt von unten. Da funktionieren die ersten beiden „hier´s“ (links) nicht.
*Kommentar muss nicht veröffentlicht werden*
Klimamodelle taugen schon deshalb nichts, weil man die Klimaprozesse nicht ausreichend versteht.
Jemand hat es sehr zutreffend formuliert: „Müll rein – Müll raus“.
werden nicht unsere Katastrophen-Prognos-Modelle, die H. Schellnhuber so gern als mit der Vergangenheit überprüft darstellt, nicht ausschliesslich nur mit errechneten Zahlen/Temperaturen und nicht mit direkt abgelesenen, gefüttert ? Errechnete Daten auch dann wen man Rohdaten hat ?
Rohdaten sind anscheinend ungeeignet, wie man schon am Beispiel Neuseeland feststellen konnte. Justierte Daten bringen wenigstens eine Erwärmung zustande. (Mit Rohdaten gab es in Neuseeland die letzten 150 Jahre !! keine Erwärmung (+0,06°C), mit justierten Daten war die Erwärmung +0,93°).
Ein Fachmann/Experte hätte dafür natürlich eine plausible Erklärung.
(Natürlich : sachlich/nüchtern gesehen bleibt es sich vom kurzzeitigen Ergebnis her gesehen egal ob ich mit einer reellen Frau oder einer tollen Modellpuppe von Frau Uhse in die Kiste gehe)
Ein Dank an die Autoren. Sie haben uns genau erklärt wie Märchen in heutiger Zeit durch den Computer erzeugt werden. Die Gebrüder Grimm nannten so was „Frau Holle“ und legten es in Ihrem Buch „Märchen- und Sagensammlung“ ab.
Moderne Märchen entstehen mit dem Computer und die Autoren nennen es eine wissenschaftliche Arbeit. Neben dem Computerspiel „Fußballmanager“ für alle Bundesligainteressierte und dem „Handballmanager“ gibt es eben auch etliche „Klimamanager“ als Spielesoftware auf dem Markt.
@Harry Hain
Dieses Gesetz ist in der Tat der Renner
Q = 1/N^2
Jetzt wissen wir auch, warum Guttenberg nicht soviel zitieren wollte. Wenn wir dieses Gesetz auf den IPCC Bericht anwenden wird es trostlos.
„Q ca = 1 / N^2 “
Der absolute Brüller. Kannte ich noch nicht und wird sofort in meiner Hall of Fame-Formelsammlung aufgenommen! 🙂 Danke.
Für mich ist das kein Ausrutscher, sondern passt in die festzustellende, bewusste Verschärfung der Klimawandel-Hysterie.
Am 16.2. stand ein Artikel vom DWD in der Zeitung: „Der fortschreitende Klimawandel wird nach Berechnungen des Deutschen Wetterdienstes (DWD) ab 2040 zu deutlich mehr extremen Regenfällen und Überschwemmungen führen“.
Und heute (19.3.11) steht: „Sommer 2010 brach alle Rekorde. In den vergangenen 500 Jahren war es noch nie so heiss“.
Dazu passt dann, dass auf „wallstreet-online“ berichtet wurde, dass ein Verband eine Zwangs-Versicherungspflicht gegen Umweltereignisse auch in Deutschland fordert.
Inzwischen interessiert keine Zeitung mehr auch nur im Geringsten, ob das, was sie da abdruckt noch eine Spur von Wahrheit enthält.
Es ist der Ökolobby gelungen, ihre Meinung durchzusetzen und wirksamer Widerstand ist zumindest in Deutschland nicht mehr erkennbar.
„Nature“ ist damit endgültig auf der Liste der vorsätzlichen Manipulatoren (=Fälscher) der Öko-Angstmacher.
Wirklich faszinierend was das in der „Wissenschaft“ abläuft.