
Ross McKitrick
1999 veröffentlichten Myles Allen und Simon Tett einen Artikel in der in der Zeitschrift Climate Dynamics (im Folgenden als „AT99“ bezeichnet), in dem sie ein Verfahren – den optimalen Fingerabdruck – beschrieben, um beobachtete Klimaveränderungen den zugrunde liegenden Ursachen zuzuordnen, mit besonderem Augenmerk auf den durch Treibhausgase verursachten Antrieb. Sie schlugen auch eine Methode vor, die als Residualkonsistenztest (RC) bezeichnet wird, um festzustellen, ob das statistische Modell gültig ist.
Das Optimal Fingerprinting, das manchmal auch als Optimal Detection bezeichnet wird, wurde sofort angenommen und vom IPCC in seinem Dritten Bewertungsbericht (TAR) von 2012 und wird seitdem in jedem IPCC-Bewertungsbericht erwähnt. TAR Anhang 12.1 trug die Überschrift „Optimale Erkennung ist Regression“ und begann:
Die Nachweismethode, die in den meisten Erkennungsstudien zum „optimalen Nachweis“ verwendet wurde, hat mehrere gleichwertige Darstellungen. Kürzlich wurde erkannt, dass es sich als ein multiples Regressionsproblem in Bezug auf verallgemeinerte kleinste Quadrate dargestellt werden kann (Allen und Tett, 1999; siehe auch Hasselmann, 1993, 1997.
2014 wies eine Gruppe von Autoren unter der Leitung von Jara Imbers, zu der auch Myles Allen als Koautor gehörte, auf die Auswirkungen hin, welche das statistische Verfahren in den vergangenen Jahren gehabt hatte:
Die Aussage des Zwischenstaatlichen Ausschusses für Klimaänderungen (IPCC), dass es ’sehr wahrscheinlich‘ sei, dass anthropogene Emissionen das Klima beeinflussen, basiert auf einer statistischen Nachweis- und Zuordnungsmethode, die stark von der Charakterisierung der internen Klimavariabilität abhängt, wie sie von [Klimamodellen] simuliert wird .³
Die Förderung und das Vertrauen des IPCC in das Optimum Fingerprinting hält bis heute an.4 Sie wurde in Dutzenden und möglicherweise Hunderten von Studien im Laufe der Jahre verwendet. wo auch immer man in der Fachliteratur beginnt, alle Wege führen zurück zu Allen und Tett (oft über das Folgepapier Allen und Stott 2003). Außerdem stützt sich die Literatur fast ausschließlich auf den RC-Test zur Überprüfung der Gültigkeit der Ergebnisse. Also spielen die Fehler und Unzulänglichkeiten des Papiers auch zwei Jahrzehnte später noch eine akute Rolle.
Ich habe einen Artikel in Climate Dynamics veröffentlicht, der zeigt, dass das optimale Fingerprinting-Verfahren, wie es in AT99 und dem Nachfolgepapier angewendet worden war, theoretisch fehlerhaft ist und sinnlose Ergebnisse liefert.6 Es beweist nicht, dass alle Ergebnisse dieser Methode falsch sind, aber es zeigt, dass die Grundlage, auf der sie für richtig gehalten wurden, nicht vorhanden ist.
Über die Logik und die Implikationen meiner Ergebnisse
Eine sorgfältige Erklärung der Auswirkungen meiner Feststellung muss ein elementares Prinzip der Logik beachten. Wir können ohne Angst vor Widersprüchen sagen:
Angenommen, A impliziert B. Wenn A wahr ist, ist auch B wahr.
Ein Beispiel: Alle Hunde haben ein Fell. Ein Beagle ist ein Hund, also hat ein Beagle hat ein Fell. Wir können dies jedoch nicht sagen:
Angenommen, A impliziert B. A ist nicht wahr, also ist B nicht wahr.
Beispiel: Alle Hunde haben ein Fell; eine Katze ist kein Hund, also hat eine Katze kein Fell. Aber natürlich können wir auch sagen:
Angenommen, A impliziert B; A ist nicht wahr, also wissen wir nicht, ob B wahr ist.
Beispiel: Alle Hunde haben ein Fell. Ein Delphin ist kein Hund, also wissen wir wissen wir nicht, ob ein Delfin ein Fell hat.
Betrachtet man die Auswirkungen meiner Ergebnisse, so ist „A“ das mathematische Argument, das Allen und Tett anführten, um ‚B‘ zu beweisen, nämlich die Behauptung, dass ihr Modell unvoreingenommene und genaue Ergebnisse liefert. In meiner Kritik habe ich gezeigt, dass ‚A‘, ihr mathematisches Argument, falsch ist. Wir haben also keine Grundlage, um etwas über „B“ zu sagen, und schon gar nicht, dass ihr Modell unvoreingenommene und genaue Ergebnisse liefert. Die Kritik trifft auch auf den RC-Test zu: Er liefert nichtssagende Antworten. In meinem Artikel führe ich die Bedingungen auf, die nachgewiesen werden müssen, um die Behauptungen über ihre Methode zu bestätigen. Ich glaube nicht, dass dies möglich ist, aus Gründen, die in dem Papier genannt werden, aber ich lasse die Möglichkeit offen. In Ermangelung eines solchen Beweises lassen die Ergebnisse ihres Verfahrens über die letzten 20 Jahren keine Aussagen über den Einfluss von Treibhausgasen auf das Klima machen. Hier werde ich versuchen, die wichtigsten Elemente des statistischen Arguments zu erläutern.
Regression
Die meisten Menschen mit einem gewissen Maß an wissenschaftlicher Bildung sind mit dem Gedanken vertraut, eine Linie der besten Anpassung durch eine Daten-Punktwolke zu ziehen. Dies wird als lineare Regression bezeichnet. Betrachten Sie Abbildung 1. Sie zeigt für eine Stichprobe von Ehepaaren das Alter der Ehefrau im Vergleich zum Alter des Ehemannes:
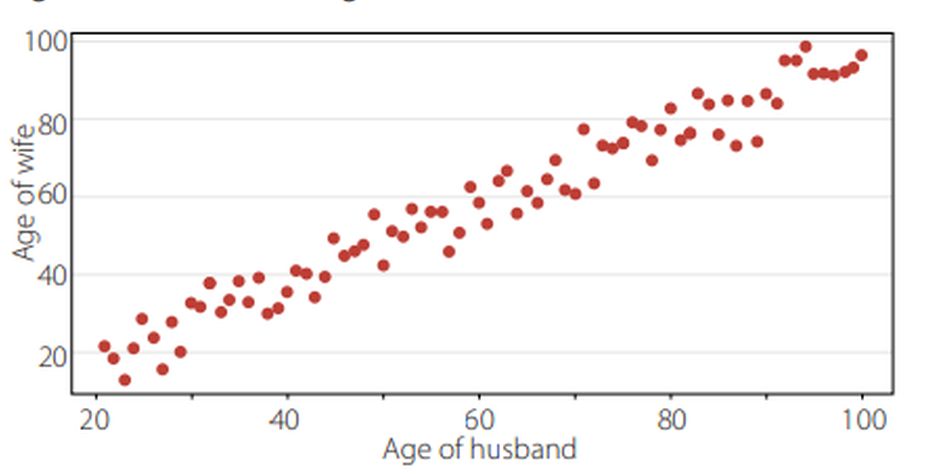
Abbildung 1: Ehepaare: Altersvergleich von Ehefrauen und Ehemännern
Es besteht ein eindeutiger Zusammenhang zwischen beiden: Ältere Männer haben ältere Ehefrauen und umgekehrt. Sie können sich leicht vorstellen, eine gerade Linie der durch die Punkte zeichnen. Es ist üblich, die horizontale Achse als x-Achse und die vertikale Achse als y-Achse zu bezeichnen. Die Linie kann mit zwei Zahlen definiert werden: der Steigung und dem Achsenabschnitt auf der y-Achse. Wenn die Steigung positiv ist, sind höhere Werte auf der Werte auf der x-Achse auch mit höheren Werten auf der y-Achse verbunden. Dies ist im obigen Beispiel eindeutig der Fall; jede vernünftige Linie durch die Stichprobe würde sich nach oben neigen. Aber in anderen Fällen ist es nicht so offensichtlich. Abbildung 2 zeigt zum Beispiel den Wert von Immobilien im Verhältnis zu ihrer Nähe zu einer Hauptverkehrsstraße:
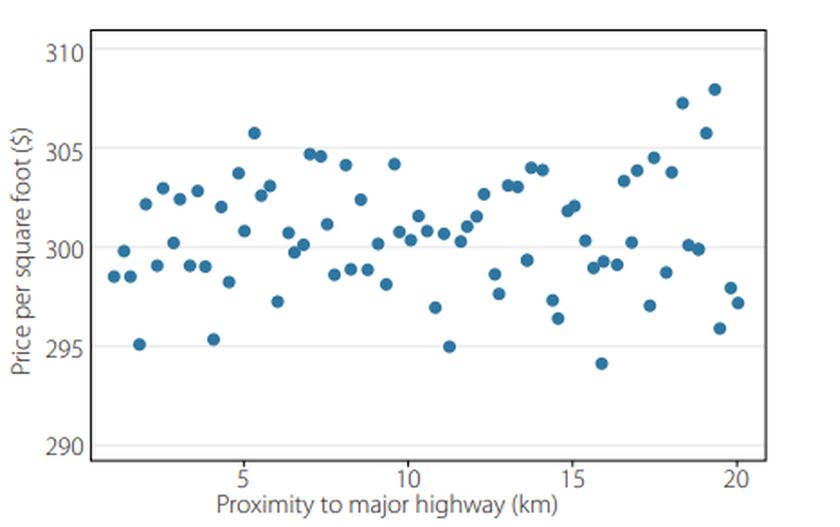
Abbildung 2: Vergleich von Immobilienpreisen relativ zur Nähe einer Autobahn
Hier kann eine Linie der besten Anpassung nahezu horizontal verlaufen, aber auch ansteigend sein. Um zu veranschaulichen, warum die statistische Theorie für die Interpretation der Regressionsanalyse wichtig ist, sollte man sich eher Abbildung 2 als Abbildung 1 vor Augen halten. Wir haben selten Daten, bei denen die Beziehung so offensichtlich ist wie im Beispiel des Ehepaares. Viel häufiger versuchen wir, subtile Muster aus viel mehr streuenden Daten herauszufinden.
Es kann besonders schwierig sein, zu erkennen, ob Steigungslinien positiv sind, wenn wir in mehreren Dimensionen arbeiten. In Abbildung 2 gibt es viele andere Variablen als die Nähe zu einer Autobahn, die die für Schwankungen bei den Immobilienwerten verantwortlich sein könnten. Wenn, sagen wir, es drei mögliche Einflussfaktoren für den Wert von Einzelhandelsimmobilien gibt, müssen wir schätzen.
Beachten Sie, dass Regressionsmodelle eine Korrelation herstellen können, aber Korrelation ist keine Kausalität. Ältere Männer verursachen nicht, dass ihre Frauen älter sind; es ist nur so, dass Menschen, die heiraten, dazu neigen, jemanden aus der gleichen Altersgruppe zu wählen. Wenn wir feststellen, dass weiter von Autobahnen entfernt liegende Grundstücke wertvoller sind, könnte das bedeuten, dass die Entfernung zu einer Autobahn den Immobilienwert beeinflusst, oder es könnte bedeuten, dass Autobahnen tendenziell auf Land gebaut werden, das aus anderen Gründen weniger wertvoll war. Regressionsmodelle können die Interpretation der Kausalität unterstützen, wenn es andere Gründe für einen solchen Zusammenhang gibt, aber man muss hierbei sehr vorsichtig vorgehen und kann erst nach einer strengen Prüfung beurteilen, ob das Modell wichtige erklärende Variablen ausgelassen hat.
Stichproben und Varianz
Unabhängig davon, wie wir den Steigungsparameter (oder die Parameter) schätzen, brauchen wir eine Möglichkeit zu testen, ob er definitiv positiv ist ist oder nicht. Das erfordert ein wenig mehr Theorie. Abbildung 1 war eine Darstellung einer Stichprobe von Daten. Es handelt sich eindeutig nicht um die gesamte Sammlung von Ehemännern und Ehefrauen auf der Welt. Eine Stichprobe ist eine Teilmenge einer Grundgesamtheit. Wenn wir eine statistische Analyse durchführen, müssen wir die Tatsache berücksichtigen, dass wir mit einer Stichprobe arbeiten und nicht mit der gesamten Grundgesamtheit. (Grundsätzlich gilt: Je größer die Stichprobe, desto repräsentativer ist sie für die Gesamtbevölkerung.)
Die Linie der besten Anpassung durch die Stichprobe kann immer nur eine Schätzung des wahren Wertes der Steigung liefern, und da es sich um eine Schätzung handelt, können wir nur von einem Bereich möglicher Werte sprechen. Die Regression ergibt also eine Verteilung möglicher Schätzungen, von denen einige wahrscheinlicher sind als andere. Wenn Sie eine Linie durch die Daten mit einem einfachen Programm wie Excel an die Daten anpasst, gibt es vielleicht nur den zentralen Schätzung, aber die zugrunde liegende Theorie liefert eine Verteilung von möglichen Werten.
Die meisten Menschen sind mit dem Gedanken einer Daten zusammen fassenden „Glockenkurve“ vertraut. Ein Beispiel wäre die Verteilung der Zensuren in einer Klasse, bei der viele Werte um den Mittelwert gruppiert sind, aber immer weniger werden, je weiter man sich vom Mittelwert entfernt. Die Streuung einer Verteilung wird durch eine Zahl zusammengefasst der sogenannten Varianz. Ist die Varianz niedrig, ist die Verteilung eng, ist sie hoch, ist sie breit (Abbildung 3).
Die Regressionsanalyse liefert also neben der Schätzung der Steigung auch einen Schätzwert für die Varianz. Ein eng verwandtes Konzept ist die Standardabweichung der Steigung – wiederum ein Maß dafür, wie wie eng die Punkte in der Stichprobe um die gerade Linie streuen, die wir an sie angepasst haben.7 Die statistische Theorie sagt uns, dass solange das Regressionsmodell eine Reihe von Bedingungen erfüllt, mit 95-prozentiger Wahrscheinlichkeit den wahre Wert der Steigung (der den man erhalten würde, wenn man eine Stichprobe der gesamten Population nehmen könnte) innerhalb von etwa plus/minus zwei Standardabweichungen der Schätzung der Steigung erhält. Dies wird als 95%-Konfidenzintervall Intervall bezeichnet.
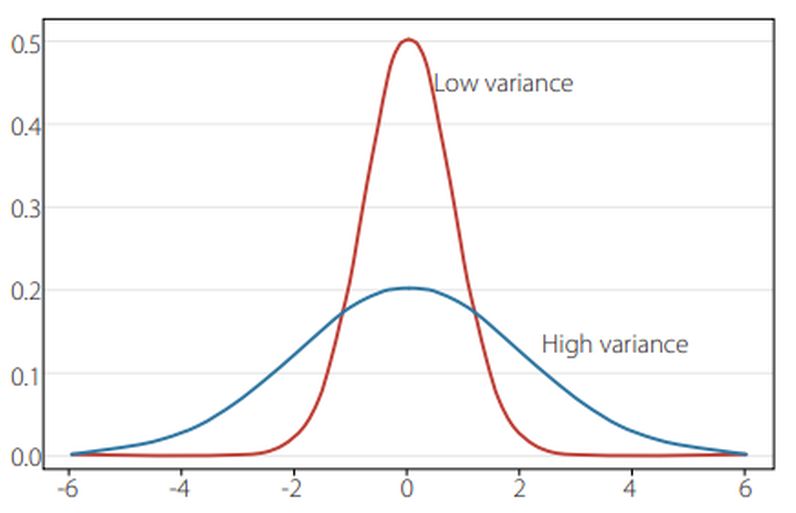
Abbildung 3: Varianz
Wir können also Regressionsverfahren anwenden, um eine Linie durch eine Stichprobe von Daten – z. B. Häufigkeit von Hurrikanen und Temperatur – zu ziehen, und wenn die geschätzte Steigung mehr als zwei Standardabweichungen über Null liegt, können wir sagen, dass wir „zuversichtlich“ sind, dass ein Anstieg der Temperatur zu einer Zunahme der Hurrikane führt. Wenn dies nicht der Fall ist, sagen wir dass die Beziehung positiv, aber statistisch nicht signifikant ist.
Bias, Effizienz und Konsistenz
Die Steigungsschätzung wird mit Hilfe einer Formel ermittelt, in welche die Anzahl der Stichprobendaten eingeht und die eine Zahl erzeugt. Es gibt viele Formeln die verwendet werden können. Die gängigste Formel ist die Ordinary Least Quadrate (OLS).8 OLS liefert auch einen Schätzwert für die Varianzen eines jeden Koeffizienten.
Es ist möglich, die Verteilung der Steigungsschätzungen mit Hilfe eines nach der Wahrscheinlichkeit gewichteten Durchschnitts auf einen einzigen Wert herunterzubrechen. In der Statistik wird dies als Erwartungswert bezeichnet. Mit Hilfe der statistischen Theorie lässt sich zeigen, dass, solange das Regressionsmodell eine Reihe von Bedingungen erfüllt, der Erwartungswert gleich dem Wert für die Grundgesamtheit ist. In diesem Falle sagen wir, dass der Schätzer unvoreingenommen ist. Wenn die oben genannte Gruppe von Bedingungen erfüllt ist, ist auch die Varianzschätzung unverzerrt.
Da es neben der OLS-Schätzung viele weitere mögliche Schätzformeln gibt, müssen wir uns überlegen, warum wir OLS den anderen Formeln vorziehen. Ein Grund ist, dass OLS unter allen Optionen, die zu unverzerrten Schätzungen führen, die geringste Varianz aufweist.9 Sie nutzt also die verfügbaren Daten am besten aus und liefert das kleinste 95%ige Konfidenzintervall. Wir nennen dies Effizienz.
Einige Formeln (oder „Schätzer“) liefern uns geschätzte Steigungs-Koeffizienten oder Varianzen, die bei einem kleinen Stichprobenumfang verzerrt sind, aber mit zunehmendem Stichprobenumfang verschwinden. Die Verzerrung und die Varianz gehen dann gegen Null, so dass die Verteilung auf den wahren Wert kollabiert. Dies wird als Konsistenz bezeichnet. Ein inkonsistenter Schätzer hat die unerwünschte Eigenschaft, dass wenn wir immer mehr Daten erhalten, wir keine Sicherheit haben, dass unsere Koeffizienten der Schätzungen näher an die Wahrheit herankommen. Bei inkonsistenten Schätzern kann die Varianz mit zunehmendem Stichprobenumfang schrumpfen, aber die Verzerrung erreicht nie Null, was bedeutet, dass die Schätzung nicht zum wahren Wert konvergiert.
Wann sind Schätzungen zuverlässig?
Ich habe mehrfach auf „eine Reihe von Bedingungen“ hingewiesen, die ein Regressionsmodell erfüllen muss, damit OLS unvoreingenommene, effiziente und konsistente Schätzungen liefert. Diese Bedingungen sind in jedem einführenden Ökonometrie-Lehrbuch aufgelistet und werden als Gauß-Markov-Bedingungen (GM) bezeichnet. Ein Großteil des Bereichs der Ökonometrie (dem Zweig der Statistik, der versucht, Regressionsanalyse zur Erstellung von Wirtschaftsmodellen zu nutzen) ist auf das Aufspüren von Fehlern in den GM-Bedingungen konzentriert und daruf, wenn diese gefunden werden, Abhilfemaßnahmen vorzuschlagen.
Einige Ausfälle der GM-Bedingungen implizieren nur, dass die Varianz-Schätzungen verzerrt sind; die Steigungsschätzungen bleiben unverzerrt. Mit anderen Worten, wir erhalten eine sinnvolle Schätzung des Steigungsparameters, aber unser Urteil darüber, ob er signifikant ist oder nicht, ist unzuverlässig. Andere Ausfälle der GM-Bedingungen bedeuten, dass die Schätzungen sowohl der Steigung als auch der Varianz verzerrt sind. In diesem Fall kann die Analyse verfälscht und völlig bedeutungslos sein.
Ein Beispiel für ein schlechtes Forschungsdesign: Angenommen, wir haben Daten aus Hunderten von US-Städten über viele Jahre, die sowohl die die jährliche Zahl der Straftaten in der Stadt und die Zahl der Polizeibeamten auf den Straßen zeigen. Wir können eine Linie durch die Daten ziehen, um um zu prüfen, ob die Kriminalität zurückgeht, wenn mehr Polizisten eingesetzt werden. Es gibt jedoch mehrere Probleme, die wahrscheinlich zum Scheitern von mehreren GM-Bedingungen führen würden. Erstens besteht die Stichprobe aus Klein- und Großstädten zusammen, und wir können sehr unterschiedliche Kriminalitätsstatistiken in größeren und kleineren Städten erwarten. Wenn wir das nicht berücksichtigen, erhalten wir verzerrte Schätzungen der Varianzen der Steigungskoeffizienten.
Zweitens gibt es Verzögerungseffekte: Eine Veränderung der Zahl der Polizeibeamten kann erst nach einer gewissen Zeit zu einer Veränderung der Kriminalität führen. Auch dies kann die Steigungskoeffizienten und Varianzschätzungen verzerren. Drittens kann die Kriminalität zwar von der Zahl der Polizeibeamten abhängen, die Zahl der Polizeibeamten kann aber auch von der Höhe der Kriminalität abhängen, so dass beide Variablen durch die jeweils andere Variable bestimmt werden: eine ist nicht eindeutig außerhalb des Modells bestimmt. Dies kann die Koeffizienten stark verzerren und zu falsche Schlussfolgerungen führen (z. B. dass mehr Polizeiarbeit zu einer höheren Kriminalitätsrate führt).
Schließlich hängen sowohl Kriminalität als auch Polizeiarbeit von Faktoren ab, die nicht im Modell enthalten sind, und wenn diese externen Faktoren nicht mit dem Ausmaß der Polizeiarbeit korreliert sind, werden die Steigungs- und Varianzschätzungen verzerrt sein.
Daher ist es von entscheidender Bedeutung, ein Versagen der GM-Bedingungen zu testen. In der Ökonometrie gibt es eine umfangreiche Literatur zu diesem Thema, das Spezifikationstest genannt wird. Studenten, die Regressionsanalyse lernen, lernen Spezifikationstests von Anfang an. Wenn ein Regressionsmodell für die Wirtschaftsforschung verwendet wird, würden die Ergebnisse niemals für bare Münze genommen werden, ohne dass zumindest einige elementare Spezifikationstests angegeben werden.
Bei einigen Verstößen gegen die GM-Bedingungen besteht die Abhilfe in einer Transformation der Daten vor der Anwendung von OLS. Ein Beispiel wäre die Umwandlung aller Daten in Pro-Kopf-Werte. Wenn wir eine Datentransformation anwenden, um einen Verstoß gegen eine oder mehrere GM-Bedingungen zu beheben, sprechen wir von der Anwendung der Generalized Least Squares (GLS). Die Anwendung einer GLS-Transformation bedeutet nicht, dass wir davon ausgehen können, dass die GM-Bedingungen automatisch gelten; sie müssen immer noch getestet werden. In manchen Fällen reicht eine GLS-Transformation nicht aus, und weitere Änderungen am Modell sind erforderlich, um unverzerrte und konsistente Schätzungen zu erhalten.
Das Verfahren von Allen und Tett
Verschiedene Autoren hatten vor AT99 vorgeschlagen, beobachtete Klimamesswerte – z. B. Veränderungen der Temperatur, der Hurrikanhäufigkeit oder des Auftretens von Hitzewellen – mit Klima-Simulationen mit und ohne Treibhausgase zu vergleichen. Wenn die Einbeziehung von Treibhausgasen zu einer deutlich besseren Übereinstimmung mit den Beobachtungen führt, könnten die Wissenschaftler die menschlichen Emissionen als Ursache verantwortlich machen. Diese Verfahren wird als „Fingerprinting“ bezeichnet.
Diese Autoren hatten auch argumentiert, dass die Analyse durch eine Anpassung der Daten an die lokalen Klimaschwankungen gestützt werden muss, indem Gebiete mit einem von Natur aus stabileren Klima stärker gewichtet werden und Gebiete, in denen das Klima „unruhiger“ ist, weniger stark. Die erforderlichen Gewichtungen werden anhand der so genannten „Klima-Rausch-Kovarianz-Matrix“ berechnet, die die Variabilität des Klimas an jedem Ort misst und für jedes Paar von Orten angibt, wie ihre Klimabedingungen miteinander korrelieren. Die damit verbundene Mathematik würde den Rahmen dieser Abhandlung sprengen, aber für das Verständnis der Kernfragen ist es einfach notwendig zu verstehen, dass einer der erforderlichen Schritte darin besteht, die Inverse der Matrix zu berechnen.
Dies erwies sich jedoch in der Praxis als schwierig. Anstatt die Matrix anhand von Beobachtungsdaten zu berechnen, haben Klimatologen lange Zeit lieber Klimamodelle bevorzugt. Es gab zwar Gründe für diese Entscheidung, führte jedoch zu vielen Problemen (die ich in meinem Beitrag erörtere). Eines davon war, dass die Klimamodelle keine ausreichende Auflösung haben, um alle Elemente der Matrix unabhängig voneinander zu identifizieren. Dies bedeutete, dass die Matrix keine Inverse hatte.11 Daher waren die Wissenschaftler gezwungen, eine Annäherung zu verwenden, die als „Pseudo-Inverse“ bezeichnet wird, um die benötigten Gewichte zu berechnen. Dies führte zu weiteren Problemen.
Der Fehler
Die Argumentation von Allen und Tett lautete in etwa so: Sie stellten fest, dass die Anwendung eines Gewichtungsschemas das Fingerprinting Modell mit einer GLS-Regression vergleichbar macht. Und da ein richtig spezifiziertes GLS-Modell die GM-Bedingungen erfüllt, liefert ihre Methode unvoreingenommene und effiziente Ergebnisse. Das ist eine leichte Vereinfachung ihrer Argumentation, aber nicht viel. Und der Hauptfehler ist offensichtlich. Man kann nicht wissen, ob ein Modell die GM-Bedingungen erfüllt – es sei denn, man testet auf spezifische Verstöße. AT99 hat die GM-Bedingungen falsch formuliert, eine wichtige Bedingung ganz weggelassen und es versäumt, irgendwelche Tests für Verletzungen vorzuschlagen.
In der Tat haben sie die ganze Idee der Spezifikationsprüfung entgleisen lassen, indem sie argumentierten, dass sie nur testen müssten, ob die Rauschkovarianzschätzungen des Klimamodells „zuverlässig“ seien (ihr Begriff, den sie nicht definierten), und sie schlugen etwas vor, das sie die Residual Consistency (RC) nannten. Sie boten keinen Beweis dafür, dass der RC-Test das tut, was er angeblich tut.12 Tatsächlich lieferten sie nicht einmal eine mathematische Aussage darüber, was er testet; sie sagten nur, dass wenn die von ihnen vorgeschlagene Formel eine kleine Zahl ergibt, die Regression des Fingerabdrucks gültig ist. In meiner Studie habe ich erklärt, dass es leicht Fälle geben kann, in denen der RC-Test eine kleine Zahl ergeben würde, selbst bei Modellen, die bekanntermaßen als falsch spezifiziert und unzuverlässig gelten.
Zusammenfassend lässt sich also sagen, dass Allen und Tett mit ihrem Verfahren nicht sicherstellen konnten, dass die GM-Bedingungen erfüllt waren, und konnten daher nicht beurteilen, ob ihre Schätzungen zuverlässig waren. Wie ich in meinem Papier dargelegt habe, versagt die Methode von Allen und Tett, wie sie in ihrem Papier dargelegt ist, automatisch bei mindestens einer GM-Bedingung, wahrscheinlich sogar mehreren. Daher müssen die Ergebnisse als unzuverlässig angesehen werden.
In den Jahren seit der Veröffentlichung des Papiers sind jedoch niemandem die Fehler in der AT99-Diskussion über die GM-Bedingungen aufgefallen, niemand bemerkte das Fehlen einer Ableitung des RC-Tests, und keine der nachfolgenden Anwendungen der AT99-Methode wurde einer konventionellen Spezifikationsprüfung unterzogen. Das heißt, wir haben keine Grundlage für die Akzeptanz von Behauptungen, die sich auf das optimale Fingerprinting-Verfahren stützen.
Nebenbei: die leichte Modifikation
Der optimale Fingerabdruck-Ansatz von Allen und Tett wird mit nur einer geringfügigen Änderung seit 20 Jahren von den Klimawissenschaftlern verwendet.
Die leichte Änderung erfolgte 2003, als Myles Allen und ein anderer Koautor, Peter Stott, vorschlugen, von GLS auf einen anderen Schätzer mit der Bezeichnung Total Least Squares (TLS) überzugehen.13 Dabei wird die Klimavariabilität nach wie vor gewichtet, aber die Steigungskoeffizienten werden mit einer anderen Formel geschätzt. Die Begründung dafür war, dass die vom Klimamodell generierten Variablen in der Fingerprinting-Regression selbst ziemlich „verrauscht“ sind, was dazu führen kann, dass GLS Koeffizientenschätzungen liefert, die nach unten verzerrt sind. Das ist richtig, aber Ökonometriker gehen mit diesem Problem mit einer Technik namens Instrumentalvariablen (IV) an. Wir verwenden TLS nicht (in der Tat verwendet es fast niemand außerhalb der Klimatologie), weil TLS unter anderem dann, wenn das Regressionsmodell falsch spezifiziert ist, eine Überkorrektur vornimmt und den Ergebnissen eine Verzerrung nach oben verleiht. Außerdem ist sie im Vergleich zur OLS extrem ineffizient. IV-Modelle können konsistent und unverzerrt sein. TLS-Modelle können das nicht, es sei denn, der Forscher macht einige restriktive Annahmen über die Varianzen im Datensatz, die selbst nicht getestet werden können; mit anderen Worten es sei denn, der Modellierer ’nimmt das Problem weg‘. Ich werde dies in einer nachfolgenden Studie behandeln.
Implikationen und die nächsten Schritte
Optimales Fingerprinting erfüllt nicht die GM-Bedingungen. Allen und Tett behaupteten fälschlicherweise das Gegenteil, und spätere Autoren zitierten und beriefen sich auf diese Behauptung. Das Verfahren (einschließlich der TLS-Variante) liefert Ergebnisse, die zufällig richtig sein könnten, aber im Allgemeinen verzerrt und inkonsistent sind und daher nicht als zuverlässig angesehen werden können. Nichts in der Methode selbst (einschließlich der Verwendung des RC-Tests) erlaubt es den Wissenschaftlern, mehr als das zu behaupten.
Neben der Untersuchung der Verzerrungen, die durch die Verwendung von TLS in Fingerprinting-Regressionen eingeführt werden, untersuche ich die Auswirkungen der Anwendung grundlegender Spezifikationstests auf Fingerprinting-Regressionen und die Behebung der daraus resultierenden Fehler.
Soweit dieser Beitrag. Es folgt noch eine längere Erwiderung auf Kommentare dazu sowie eine Liste von Referenzen.
Das vollständige PDF ist hier:
Übersetzt von Christian Freuer für das EIKE

Zusammenfassung aus dem Vortrag von R.McKittrick auf der 14.Climate Conference des Heartland Institutes
—————————————-
Es folgt noch ein Kommentar hierzu von der EIKE-Redaktion (Michael Limburg):
Was Ross herausgefunden hat, ist für mich und viele andere, die mit den Grenzen der Statistik einigermaßen vertraut sind, wirklich keine Überraschung. Aber es ist sehr gut erklärt für alle, die 1. wirklich gläubig sind und 2. sich für die Grenzen dieser Methoden interessieren, aber nicht in der Lage sind, die Methode so klar zu entwickeln wie Ross es tut. So z.B. für mich.
Aber es gibt noch einen weiteren Aspekt, den Ross (zumindest habe ich ihn noch nicht gesehen) in seiner Kritik völlig ausklammert. Nämlich, dass die „Fingerabdruck“-Methode selbst unecht ist. (in einem Sinne von „unberechtig“). Das liegt daran, dass sie als Grundlage annimmt, dass CO2 einen zurechenbaren Einfluss auf die Lufttemperatur hat. (Diese Temperatur selbst ist ein unwissenschaftlicher Begriff, sobald man sich mit „Mitteltemperatur“ beschäftigt. Eine Temperatur braucht in der Physik immer einen Ort und ein Medium, wo sie gemessen wird, um überhaupt ein gültiger Begriff zu sein). Die Modellierer sind also gezwungen, diese Abhängigkeit in ihre Modelle einzubauen. Sonst kann der Computer nicht rechnen. Also ist alles, was die Modelle zeigen, das was die Programmierer ihnen vorher gesagt haben. Das ist in meinem Verständnis ein Zirkelschluss, aber keineswegs ein Beweis. Noch schlimmer ist, dass sie alle natürlichen Kräfte, insbesondere die der Sonne, außen vor lassen.














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Tja, das sind Probleme von eher homöopathischer Bedeutung, während die Brachialfehler direkt vor der Nase übersehen werden. Wie wäre es mit dem: ein Großteil des Treibhauseffekts wird nicht von THGen ODER Wolken verursacht, sondern simultan von beiden. Die Größenordnung dieser Überlagerung beträgt ca. 50W/m2. Die Klimawissenschaft leugnet (mit wenigen Ausnahmen) aber diese und behauptet jener Anteil am THE sei einzig THGen zuzurechnen.
Die Auswirkungen könnten gravierender nicht sein, insbesondere bei ECS Schätzungen. Aber stört es jemanden? Nö! Offenbar versteht es keiner. Natürlich hat es die „Klimawissenschaft“ dann leicht mit dem gröbsten Unfug durchzukommen. Es ist traurig.
„Nö! Offenbar versteht es keiner.“ Könnten Sie mir bitte erklären, wie Sie auf die Werte 355, -80 und -85 W/m² kommen. Die langwellige Abstrahlung der Oberfläche beträgt nach Stephens 2012 „An update on Earth’s energy balance in light of the latest global observations“ 398 +/- 5 W/m². Meine Rechnung mit CERES-Daten ergibt für den Zeitraum 200003- 202102 für die absorbierte solare Einstrahlung TOA ASRAS 241,3 +/- 0,5 W/m². Strahlungs-Transfer-Rechnungen liefern nach CERES im gleichen Zeitraum für die absorbierte solare Einstrahlung der Oberfläche ASRSAS 163,9 +/+ 0,6 W/m². Daraus ergibt sich als Differenz die Absorption der solaren Einstrahlung durch die Atmosphäre ASRAAS mit 77,4 +/- 0,8 W/m². Der Trend von ASRAAS beträgt im betrachteten Zeitraum -0,06 +/- 0,08 W/m², hat also nicht signifikant abgenommen.
Ich wäre erst mal dazu geneigt zu fragen, was denn da unklar sein soll. Aber ok, ich versuche mal den dialektischen Ansatz. Sie betrachten also eine Publikation wie die oben genannte, Sie halten sie für seriös und entscheiden sich den Inhalt zu glauben. Außerdem steht da „Figure 1“ unter „observations“ für LW UP 398 +/-5W, was noch dazu zu den Modellannahmen passt.
Nun ist das aber ein blanke Lüge. Man kann die Emissionen der Oberfläche nun mal nicht messen! Das geht wegen den Treibhausgasen nicht, die im Großteil des IR Spektrums die Sicht durch die Atmosphäre auf die Oberfläche verunmöglichen. Innerhalb des atmosphärischen Fensters geht das schon, allerdings sehen wir da erhebliche Abweichungen von einem Emissionsgrad = 1. Und bei Wasser ist der Emissionsgrad vom Raumwinkel abhängig, da bringt der Blick von oben runter wenig.
Wenn man sich mit der Physik beschäftigt weiß man aber, dass Wasser einen spektralen hemisphärischen Emissionsgrad von 0.91 besitzt. Ich kann den Wert selbst berechnen (nicht ganz trivial), er findet sich aber auch in der Literatur wieder, oder zB. auch auf Wikipedia. Bei 288K emittiert Wasser also.. 0.91 x 288^4 x 5.67e-8 = 355W/m2. Die gesamten Oberflächenemissionen können nicht wesentlich davon abweichen, auch wenn halt Daten ob Landflächen fehlen.
Die 398W/m2 sind also ein frei erfundener Wert basierend auf dem Emissionsgrad = 1 Mantra, der selbstverständlich auch in den Modellen verwendet wird, und dort zu falschen Ergebnissen führt. Tatsächlich ist die gesamte „Klimawissenschaft“ auf solchem Blödsinn aufgebaut.
Die 85W/m2 für THGe ergeben sich aus der Differenz 355-270, wobei 270W/m2 die Emission bei klarem Himmel sind. Bei den 80W/m2 bin ich mir nicht ganz sicher, es könnten vielleicht auch eher 75W/m2 sein. Jedenfalls ergibt sich der Wert aus dem Umstand, dass der brutto THE von Wolken ca. 2.5 bis 2.6mal größer sein muss, als der netto THE. Da der netto THE laut IPCC rund 30W/m2 beträgt, ergeben sich dann eben 75-80W/m2.
Den Faktor 2.6 habe ich selbst ermittelt. Erst später habe ich dann etwa Schmidt et al (2010) entdeckt, wo eine Relation von 2.5 behauptet wird (Table 1 „single factor addition“ zu „single factor removal“: 36.3 / 14.5). Dort allerdings mit viel zu niedrigen Absolutwerten.
https://pubs.giss.nasa.gov/docs/2010/2010_Schmidt_sc05400j.pdf
Herzlichen Dank für Ihre ausführliche Anwort. Das „Emissionsgrad = 1 Mantra“ hat mich auch schon beschäftigt. Ich halte es für eine Näherung, die bei starker Reemission der von der Oberfläche ausgesandten IR-Strahlung gut erfüllt ist. (All sky-Bedingungen). Bei direkter Emission ins All gilt dies natürlich nicht. Die von der Atmosphäre der Oberfläche zugestrahlte IR-Strahlung wird bei Emissionsgrad kleiner 1 teilweise reflektiert und dann von der Atmosphäre wieder absorbiert. Man kann dies als einen Speicher für elektromagnetische Strahlung betrachten. Letztlich findet die Strahlung mit einer Verzögerung doch ihren Weg ins All. Viel größere Speicher-Effekte treten bei der Absorption der Sonnen-Strahlung durch die Oberfläche auf. Die entstehende Wärme wird in die Tiefe transportiert. Diese Speicher-Effekte erschweren die Interpretation der IR-Daten. Deshalb habe ich mich auf die solare Einstrahlung beschränkt.
Nochmal: ich spreche vom Emissionsgrad der Oberfläche und dieser beträgt eben annähernd 0,91, oder 91%. Das heißt nicht 100%. Und da spielt es keine Rolle wie viel von diesen Emissionen von der Atmosphäre absorbiert werden oder nicht. Somit ist die Annahme eines Oberflächenemissionsgrades von 1 auch keine „gültige Annäherung“, sondern einfach nur völlig falsch.
„Somit ist die Annahme eines Oberflächenemissionsgrades von 1 auch keine „gültige Annäherung“, sondern einfach nur völlig falsch.“ Ich habe nicht behauptet, dass die Näherung richtig ist, sondern dass sie Ergebnisse liefert, die mit den Beobachtungen gut übereinstimmen. Beispiel CERES LW surface flux up All sky 202106 48.49°N, 11°..12°O 413,8 W/m² Mit Emissivität = 1 ergibt sich nach dem SB-Gesetz 19,1 °C. Mit dem GHCNv4-Stations-Daten erhalte ich 18,9 °C. Im Mittel 2000..2021 beträgt die Differenz CERES- GHCNv4 0,3 °C.
Konkrete Datenquellen täten da gut. Welche Temperatur soll 19.1°C denn sein? Bei einem „all sky flux“ von 413,8 W/m² ist es definitiv nicht die Oberflächentemperatur, sonst gäbe es ja keinen THE.
Achja, ich habe nachgesehen. Selbst bei klarem Himmel und äußerst trockenen Verhältnissen, müsste in modtran schon eine Oberflächentemperatur von 46.6°C vorherrschen, damit an Ende TOA ca. 413W/m2 emittiert werden. Ich kann also nur schlussfolgern was Sie da zitieren.
Die 413,8W/m2 sind offensichtlich kein gemessener Wert, sondern ein Schätzwert bzgl der Emissionen an der Oberflläche, basierend auf der falschen Annahme, bei 19,2°C würde die Oberfläche wir ein perfekter Emitter eben jene Strahlungsmenge abgeben. Wie der Bewölkungsgrad beschaffen ist, ist hierbei sowieso irrelevant. Somit ist die gesamte Argumentationslinie rekursiv. Nochmal: ein Satellit kann die Oberflächenemissionen nicht messen, weil er sie mit kleinen Ausnahmen nicht „sieht“. Dass die per Satellit geschätzen Oberflächentemperaturen ungefähr mit jenen vor Ort gemessenen übereinstimmen, tut da nichts zur Sache.
E. Schaffer schrieb am 30. Oktober 2021 um 17:37
Herr Berberich hat sich auf „CERES LW surface flux up“ bezogen. Wenn ich mich recht entsinne ist das die vom Satelliten im atmospärischen Fenster beobachteten Daten – dort sieht der Satellit also sehr wohl die Strahlung, die von der Erdoberfläche kommt. Vielleicht kann Herr Berberich den Datensatz ja mal verlinken (oder beschreiben, wie man dort hinkommt? Ich verlauf mich auf der Ceres seite regelmäßig…)
Dann sieht man vielleicht, ob und wie von den Daten aus auf die Oberflächentemperatur geschlussfolgert wird …
Der Fehler ist ohnehin offensichtlich. Zum einen wissen wir, das in der Realität nichts wie ein perfekter Schwarzkörper strahlt. Zum anderen können wir leicht ermitteln.. (19.1 + 273.15)^4 * 5.67e-8 = 413.6
Abgesehen von der kleinen Rundungsdifferenz, wird „CERES LW surface flux up“ also auf Basis Emissionsgrad = 1 aus der gemessenen Temperatur errechnet, nicht gemessen. Selbst mit einem extrem hohen Emissionsgrad von 0.99 wären es schon 4W/m2 weniger. Herr Berberich irrt hier, da er glaubt eine Messung würde den Emissionsgrad von 1 begründen. Das Gegenteil ist der Fall.
Dabei ist das ohnehin absurd. Für die Bestimmung der Temperatur anhand der Emissionen im atmosphärischen Fenster sind reale Emissionsgrade notwendig. Diese werden aufwendig vor Ort ermittelt, gelten aber halt nur für das atmosphärische Fenster. Nachdem man die Temperatur so halbwegs korrekt errechnet hat, wirft man diesen partiellen Emissionsgrad über Bord und setzt den spektralen Emissionsgrad wieder = 1.
Schaffer 30.10.2021 um 15:36 „Konkrete Datenquellen täten da gut.“ Die von mir am 29. Oktober 2021 um 20:11 erwähnten Daten finden Sie bei https://ceres.larc.nasa.gov/data/ -> EBAF -> order data -> surface fluxes -> long wave flux up all sky -> Time range 06-2021 to 06-2021 -> visualize data.
Wie bereits erwähnt ist Emissivität=1 eine gute Näherung wenn der Netto-Fluss LWSUp-LWSDown klein gegen LWSUp ist. LWSUp ist der gsamte IR-Strahlungsfluss, also nicht nur im Fenster-Bereich.
E. Schaffer schrieb am 3. November 2021 um 16:26
Auf der Ceres-Webseite steht bei der Beschreibung der Instrumente auf den Satelliten folgendes:
Ich kann mir irgendwie nicht vorstellen, dass die Messgeräte hochschicken und dann Werte des Satelliten basierend auf Temperaturessungen berechnen.
In der „Klimawissenschaft“ wird vieles getan was nicht vorstellbar ist, lol. Die Mathematik lügt nicht, die Physik ebenso wenig. Die angebenen Emissionen sind NUR mit einem Emissionsgrad von exakt 1 vereinbar, und den gibt es in der Realität halt nicht.
Ich habe mir die Daten angesehen, und die bestätigen genau das was ich sage. Einfach mal auf den hellroten Fleck östlich der Philippinen achten. Dort wird ein Wert von ca. 480W/m2 ausgewiesen. Selbst mit einem Emissionsgrad von 1, und der von Wasser beträgt nunmal 0.91(!), müsste das Wasser dort schon 30.2°C warm sein um so viel zu emittieren. Die Temperatur glaub ich schon, das Wasser wird dort sehr warm. Allerdings ist das eben null Spielraum für eine realiten Emissionsgrad. Deshalb nochmal: diese angegebenen Werte haben nichts mit der Realität zu tun, es sind keine Messwerte, sondern pauschale Umrechnungen der Oberflächentemperatur mit einem unterstellten Emissionsgrad = 1.
Hier übrigens der Reflexionsgrad von Wasser (= 1-Emissionsgrad):
Erinnert mich übrigens an eine „Fettmesswaage“ die ich mal hatte. Das musste man alles mögliche Eingeben (Größe, Statur usw.), und wenn man sich dann raufstellte wurde eben der Körperfettanteil angegeben. Der war aber anscheinend viel zu hoch und so wurde ich stutzig. Ein paar Tests später war klar, da findet gar keine Impedanzmessung statt. Stattdessen wurde einfach aus den eingegeben Parametern und dem Gewicht der Fettanteil „errechnet“. Sowas gibt’s..
Marvin Müller schrieb am 3. November 2021 um 18:55
Der Artikel „Surface Irradiances of Edition 4.0 Clouds and the Earth’s Radiant EnergySystem (CERES) Energy Balanced and Filled (EBAF) Data Product“ by Kato et.al. beschreibt genauer, wie die Daten ermittelt werden. Ich habe es nicht gründlich gelesen, beim Überfliegen bleibt hängen, dass Temperaturmessungen ausgewählter Stationen zur Verfikation der Ceres-Daten benutzt werden – im Gegensatz zu „die werden aus Temperaturmessungen der Stationen abgeleitet“.
E. Schaffer am 29. Oktober 2021 um 15:59 „Und da spielt es keine Rolle wie viel von diesen Emissionen von der Atmosphäre absorbiert werden oder nicht.“ Vielleicht können Sie mir dann folgendes Problem lösen. Ein Hohlraum habe die Temperatur T. Die obere Hälfte des Hohlraums hat eine andere Emissivität wie die untere Hälfte. Welche Strahlungstemperatur hat die Strahlung im Hohlraum?
„Wie wäre es mit dem: ein Großteil des Treibhauseffekts wird nicht von THGen ODER Wolken verursacht, sondern simultan von beiden.“
Mit „dem“ ist nix!
Es gibt keinen Treibhauseffekt!
Es gibt bloß Propaganda.
Ein Beispiel aus der Klimawissenschaft wäre hier sehr hilfreich. Die Satelliten Terra und Aqua (siehe z.B. CERES EBAF) messen die solare Einstrahlung (SolarIn) und die reflektierte Strahlung (SWOutAS). Die Differenz ASRAS= SolarIn-SWOutAS ist die von der Erde absorbierte solare Einstrahlung. Sie variiert saisonal. Deshalb sind 12-Monate-Mittelwerte empfehlenswert. Wie hier gezeigt nimmt ASRAS zwischen 2000 und 2021 im globalen Mittel stark zu. Der Trend beträgt 0,64 +/- 0,18 W/m² zu (95%-Vertrauens-Intervall +/-0,36 W/m²) und ist somit signifikant. Die unmittelbare Ursache ist klar: abnehmende Bewölkung. Wie lässt sich nun statistisch die Ursache der abnehmenden Bewölkung finden? Die ortsaufgelösten Messungen zeigen dass die dominanten Beiträge von den Ozeanen der gemäßigten Zone Nord (25-65 °N) stammen. Ich habe versucht dies mit der abnehmenden Windgeschwindigkeit in Verbindung zu bringen (Daten siehe CERES). Doch bei saisonaler Betrachtung ist keine Korrelation zu erkennen. Ich befürchte dass statistische Verfahren hier nicht viel weiterhelfen.