
Was ist Chaos? Ich benutze diesen Ausdruck hier in seiner mathematischen Bedeutung. So, wie in den vergangenen Jahren die Naturwissenschaftler weitere Aggregatzustände der Materie entdeckten (neben fest, flüssig, gasförmig, nun auch plasma), so wurden von der Wissenschaft neue Zustände entdeckt, die Systeme annehmen können.
Systeme von Kräften, Gleichungen, Photonen oder des Finanzhandels können effektiv in zwei Zuständen existieren:
Einer davon ist mathematisch zugänglich, die zukünftigen Zustandsformen können leicht vorhergesagt werden; im anderen aber passiert scheinbar Zufälliges.
Diesen zweiten Zustand nennen wir “Chaos”. Es kann gelegentlich in vielen Systemen eintreten.
Wenn Sie z. B. das Pech haben, einen Herzanfall zu erleiden, geht der normalerweise vorhersehbare Herzschlag in einen chaotischen Zustand über, wo der Muskel scheinbar zufällig schlägt. Nur ein Schock kann ihn in den Normalzustand zurücksetzen. Wenn Sie jemals ein Motorrad auf einer eisigen Fahrbahn scharf abgebremst haben, mussten Sie ein unkontrollierbares Schlagen des Lenkrads befürchten, eine chaotische Bewegung, die meist zu einem Sturz führte. Es gibt Umstände, wo sich die Meereswogen chaotisch bewegen und unerklärlich hohe Wellen erzeugen.
Die Chaos-Theorie ist das Studium des Chaos und weiterer analytischer Methoden und Messungen und von Erkenntnissen, die während der vergangenen 30 Jahre gesammelt worden sind.
Im Allgemeinen ist Chaos ein ungewöhnliches Ereignis. Wenn die Ingenieure die Werkzeuge dafür haben, werden sie versuchen, es aus ihrem Entwurf „heraus zu entwerfen“, d. h. den Eintritt von Chaos unmöglich zu machen.
Es gibt aber Systeme, wo das Chaos nicht selten, sondern die Regel ist. So eines ist das Wetter. Es gibt weitere, die Finanzmärkte zum Beispiel, und – das ist überraschend – die Natur. Die Erforschung der Raubtierpopulationen und ihrer Beutetierpopulationen zeigt z. B. das sich diese zeitweilig chaotisch verhalten. Der Autor hat an Arbeiten teilgenommen, die demonstrierten, dass sogar einzellige Organismen Populationschaos mit hoher Dichte zeigen können.
Was heißt es also, wenn wir sagen, dass sich ein System anscheinend zufällig verhalten kann? Wenn ein System mit dem zufälligen Verhalten anfängt, wird dann das Gesetz von Ursache und Wirkung ungültig?
Vor etwas mehr als hundert Jahren waren die Wissenschaftler zuversichtlich, dass jedes Ding in der Welt der Analyse zugänglich wäre, dass alles vorhersagbar wäre, vorausgesetzt man hätte die Werkzeuge und die Zeit dazu. Diese gemütliche Sicherheit ist zuerst von Heisenbergs Unschärfeprinzip zerstört worden, dann durch Kurt Gödels Arbeiten, schließlich durch Edward Lorenz, der als Erster das Chaos entdeckte. Wo? natürlich bei Wetter-Simulationen.
Chaotische Systeme sind nicht gänzlich unvorhersagbar, wie wirklich Zufälliges. Sie zeigen abnehmende Vorhersagbarkeit mit zunehmender Dauer, und diese Abnahme wird durch immer größer werdende Rechenleistung verursacht, wenn der nächste Satz von Vorhersagen errechnet werden soll. Die Anforderungen an Rechnerleistung zur Vorhersage von chaotischen Systemen wächst exponentiell. Daher wird mit den verfügbaren begrenzten Möglichkeiten die Genauigkeit der Vorhersagen rapide abfallen, je weiter man in die Zukunft prognostizieren will. Das Chaos tötet die Ursache-Wirkungs-Beziehung nicht, es verwundet sie nur.
Jetzt kommt ein schönes Beispiel.
Jedermann hat ein Tabellenkalkulationsprogramm. Das nachfolgende Beispiel kann jeder selbst ganz einfach ausprobieren.
Die einfachste vom Menschen aufgestellte Gleichung zur Erzeugung von Chaos ist die „Logistische Karte“ (logistic map).
In einfachster Form: Xn+1 = 4Xn(1-Xn)
Das bedeutet: der nächste Schritt in Folge gleicht 4 mal dem vorhergehenden Schritt mal (1 – vorhergehender Schritt). Wir öffnen nun ein Blatt in unserer Tabellenkalkulation und bilden zwei Spalten mit Werten:
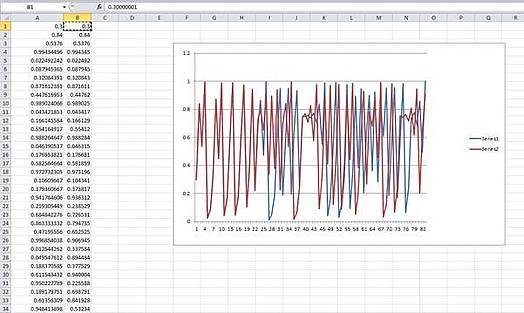
Jede Spalte A und B wird erzeugt, indem wir in Zelle A2 eingeben [=A1*4* (1-A1)], und wir kopieren das nach unten in so viele Zellen, wie wir möchten. Das gleiche tun wir für Spalte B2, wir schreiben [=B1*4* (1-B1)]. Für A1 und B1 geben wir die Eingangszustände ein. A1 erhält 0.3 und B1 eine ganz gering verschiedene Zahl: 0.30000001.
Der Graph zeigt die beiden Kopien der Serien. Anfänglich sind sie synchron, dann beginnen sie bei etwa Schritt 22, auseinander zulaufen, von Schritt 28 an verhalten sie sich völlig unterschiedlich.
Dieser Effekt stellt sich bei einer großen Spannweite von Eingangszuständen her. Es macht Spaß, sein Tabellenkalkulationsprogramm laufen zu lassen und zu experimentieren. Je größer der Unterschied zwischen den Eingangszuständen ist, desto rascher laufen die Folgen auseinander.
Der Unterschied zwischen den Eingangszuständen ist winzig, aber die Serien laufen allein deswegen auseinander. Das illustriert etwas ganz Wichtiges über das Chaos. Es ist die hohe Empfindlichkeit für Unterschiede in den Eingangszuständen.
In umgekehrter Betrachtung nehmen wir nun an, dass wir nur die Serien hätten; wir machen es uns leicht mit der Annahme, wir wüssten die Form der Gleichung, aber nicht die Eingangszustände. Wenn wir nun Vorhersagen von unserem Modell her treffen wollen, wird jede noch so geringe Ungenauigkeit in unserer Schätzung der Eingangszustände sich auf das Vorhersage-Ergebnis auswirken und das in dramatisch unterschiedlichen Ergebnissen. Der Unterschied wächst exponentiell. Eine Möglichkeit zur Messung gibt uns der sogenannte Lyapunov-Exponent. Er misst in Bits pro Zeitschritt, wie rasch die Werte auseinanderlaufen – als Durchschnitt über eine große Zahl von Samples. Ein positiver Lyapunov-Exponent gilt als Beweis für Chaos. Er nennt uns auch die Grenze für die Qualität der Vorhersage beim Versuch der Modellierung eines chaotischen Systems.
Diese grundlegenden Charakteristiken gelten für alle chaotischen Systeme.
Und nun kommt etwas zum Nachdenken. Die Werte unseres einfachen Chaos-Generators im Kalkulationsblatt bewegen sich zwischen 0 and 1. Wenn wir 0.5 subtrahieren, sodass wir positive and negative Werte haben, und dann summieren, erhalten wir diesen Graphen. Der ist jetzt auf tausend Punkte ausgedehnt.
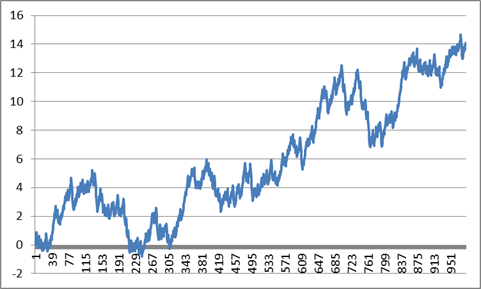
Wenn ich nun ohne Beachtung der Skalen erzählt hätte, das wäre der Kurs im vergangenen Jahr für eine bestimmten Aktie, oder der jährliche Meerestemperaturverlauf gewesen, hätten Sie mir vermutlich geglaubt. Was ich damit sagen will: Das Chaos selbst kann ein System völlig antreiben und Zustände erzeugen, die so aussehen, als ob das System von einem äußeren Antrieb gesteuert wäre. Wenn sich ein System so verhält, wie in diesem Beispiel, kann es wegen einer äußeren Kraft sein, oder ganz einfach nur wegen des Chaos.
Wie steht es also mit dem Wetter?
Edward Lorenz (1917 – 2008) ist der Vater der Chaosforschung. Er war auch Wetterforscher. Er schuf eine frühe Wetter-Simulation, indem er drei verkoppelte Gleichungen benutzte und er war erstaunt, dass die Simulationswerte mit dem Fortschritt der Simulation über der Zeit unvorhersehbar wurden.
Dann suchte er nach Beweisen, ob sich das tatsächliche Wetter in der gleichen unvorhersehbaren Weise verhielt. Er fand sie, bevor er noch mehr über die Natur des Chaos entdeckte.
Kein Klimatologe bezweifelt seine Erkenntnis vom chaotischen Charakter des Wetters.
Edward Lorenz schätzte, dass das globale Wetter einen Lyapunov-Exponenten gleich einem Bit von Information alle 4 Tage zeigt. Das ist ein Durchschnitt über die Zeit und über die globale Oberfläche. Zuweilen und an gewissen Stellen ist das Wetter chaotischer, das kann jedermann in England bezeugen. Das bedeutet aber auch, dass, falls man das Wetter mit einer Genauigkeit von 1 Grad C für morgen vorhersagen kann, die beste Vorhersage für das Wetter für den 5. Folgetag bei +/- 2 Grad liegen wird, für den 9. Tag bei +/-4 Grad und den 13. Tag bei +/- 8 Grad. Auf jeden Fall wird die Vorhersage für den 9-10. Tag nutzlos sein. Wenn Sie aber das Wetter für Morgen mit einer Treffsicherheit von +/- 0.1 Grad vorhersagen könnten, dann würde die Zunahme des Fehlers verlangsamt. Weil sie aber exponentiell steigt, wird auch diese Vorhersage bereits nach wenigen weiteren Tagen nutzlos sein.
Interessanterweise fällt die Treffsicherheit der Wettervorhersagen von Institutionen, wie z. B. dem englischen Wetterdienst, genau in dieser Weise ab. Das beweist einen positiven Lyapunov-Exponenten und damit, dass das Wetter chaotisch ist, wenn es noch eines Beweises bedurft hätte.
Soviel zur Wettervorhersage. Wie steht es mit der Langzeit-Modellierung?
Zuerst zur wissenschaftlichen Methode. Das Grundprinzip ist, dass die Wissenschaft sich so entwickelt, dass jemand eine Hypothese formuliert, diese Hypothese durch ein Experiment erprobt und sie modifiziert, sie beweist oder verwirft, indem er die Ergebnisse des Experiments auswertet.Ein Modell, ob nun eine Gleichung oder ein Computer-Modell, ist nur eine große Hypothese. Wenn man die mit der Hypothesenbildung betroffene Sache nicht durch ein Experiment modifizieren kann, dann muss man Vorhersagen mit dem Modell machen und am System selbst beobachten, ob die Vorhersagen damit zu bestätigen oder zu verwerfen sind.##Ein klassisches Beispiel ist die Herausbildung unseres Wissens über das Sonnensystem. Bei den ersten Modellen standen wir im Mittelpunkt, dann die Sonne, dann kam die Entdeckung der elliptischen Umläufe und viele Beobachtungen, um die exakte Natur dieser Umläufe zu erkennen. Klar, dass wir niemals hoffen konnten, die Bewegungen der Planeten zu beeinflussen, Experimente waren unmöglich. Aber unsere Modelle erwiesen sich als richtig, weil Schlüsselereignisse zu Schlüsselzeiten stattfanden: Sonnenfinsternisse, Venusdurchgänge usw. Als die Modelle sehr verfeinert waren konnten Abweichungen zwischen Modell und Wirklichkeit benutzt werden, um neue Eigenschaften vorherzusagen. Auf diese Art konnten die äußeren Planeten Neptun und Pluto entdeckt werden. Wenn man heute auf die Sekunde genau wissen will, wo die Planeten in zehn Jahren stehen, gibt es im Netz Software, die exakt Auskunft gibt.Die Klimatologen würden nur allzu gerne nach dieser Arbeitsweise verfahren. Ein Problem ist aber, dass sie aufgrund des chaotischen Charakters des Wetters nicht die geringste Hoffnung hegen können, jemals Modellvorhersagen mit der Wirklichkeit in Einklang bringen zu können. Sie können das Modell auch nicht mit kurzfristigen Ereignissen zur Deckung bringen, sagen wir für 6 Monate, weil das Wetter in 6 Monaten völlig unvorhersagbar ist, es sei denn in sehr allgemeinen Worten.Das bedeutet Schlimmes für die ModellierbarkeitNun möchte ich noch etwas in dieses Durcheinander einwerfen. Das stammt aus meiner anderen Spezialisierung, der Welt des Computer-Modellierens von selbst-lernenden Systemen.Das ist das Gebiet der „Künstlichen Intelligenz“, wo Wissenschaftler meist versuchen, Computer- Programme zu erstellen, die sich intelligent verhalten und lernfähig sind. Wie in jedem Forschungsfeld ruft das Konzept Mengen von allgemeiner Theorie hervor, und eine davon hat mit der Natur der Stück-um-Stück zunehmenden Erfahrung (Inkrementelle Erfahrung) zu tun.Inkrementelle Erfahrung findet statt, wenn ein lernender Prozess versucht, etwas Einfaches zu modellieren, indem er vom Einfachen ausgeht und Komplexität zufügt, dabei die Güte des Modells beim Fortgang testet.Beispiele sind Neuronale Netzwerke, wo die Stärke der Verbindungen zwischen simulierten Hirnzellen mit dem Prozess des Lernens angepasst wird. Oder genetische Programme, wo Bits von Computerprogrammen modifiziert werden und bearbeitet werden, um das Modell immer mehr anzupassen.Am Beispiel der Theorien über das Sonnensystem können Sie sehen, dass die wissenschaftliche Methode selbst eine Form des inkrementellen Lernens ist.Es gibt einen universellen Graphen über das Inkrementelle Lernen. Er zeigt die Leistung eines beliebigen inkrementellen Lern-Algorithmus bei zwei Datensätzen, ganz gleich bei welchem.Voraussetzung ist, dass die beiden Datensätze aus der gleichen Quelle stammen müssen, aber sie sind zufällig in zwei Datensätze aufgespaltet, in den Trainingsdatensatz für die Trainierung des Modells und in einen Testdatensatz, der immer wieder für das Überprüfen gebraucht wird. Normalerweise ist der Trainingsdatensatz größer als der Testdatensatz, aber wenn es viele Daten gibt, macht das nichts aus. Mit der Zunahme des Wissens im Trainingsmodell benutzt das lernende System die Trainingsdaten, um sich selbst anzupassen, nicht die Testdaten, die zum Testen des Systems benutzt und sofort wieder vergessen werden.
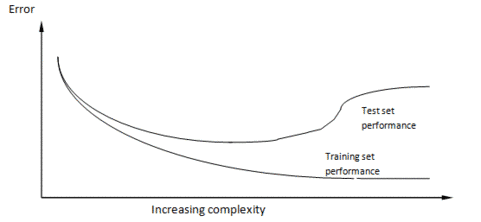
Wie zu sehen ist, wird die Leistung mit dem Trainingsdatensatz immer besser, je mehr Komplexität dem Modell zugefügt wird, auch die Leistung des Testdatensatzes wird besser, beginnt aber dann, schlechter zu werden.
Um es deutlich zu sagen: der Testsatz ist das Einzige, was zählt. Wenn wir das Modell für Vorhersagen benutzen wollen, werden wir es mit neuen Daten füttern, wie mit unserem Testdatensatz. Die Leistung des Trainingsmodells ist irrelevant.
Über dieses Beispiel wird diskutiert, seit Wilhelm von Ockham den Satz geschrieben hat: “Entia non sunt multiplicanda praeter necessitatem“, besser bekannt als „Ockhams Rasiermesser“ und am besten so übersetzt: “Die Entitäten dürfen nicht ohne Not vermehrt werden”. Mit Entitäten meinte er unnötige Verzierungen und Schnörkel einer Theorie. Die logische Folge daraus ist, dass die am einfachsten die Fakten erklärende Theorie wahrscheinlich stimmt. Es gibt Beweise für die Allgemeingültigkeit dieses Satzes aus dem Gebiet der Bayesianischen Statistik und der Informationstheorie.
Das heißt also, dass unsere kühnen Wettermodellierer von beiden Seiten her in Schwierigkeiten stecken: wenn die Modelle für die Wettererklärung nicht ausreichend komplex sind, sind ihre Modelle nutzlos, wenn sie allzu komplex sind, auch.
Wer möchte da noch Wettermodellierer sein?
Unter der Voraussetzung, dass sie ihre Modelle nicht anhand der Wirklichkeit kalibrieren können, wie entwickeln und prüfen die Wettermodellierer ihre Modelle?Wie wir wissen, verhalten sich auch Wettermodelle chaotisch. Sie zeigen die gleiche Empfindlichkeit auf die Eingangsbedingungen. Das Mittel der Wahl für die Evaluierung (von Lorenz entwickelt) ist, Tausende von Läufen durchzuführen mit jeweils geringfügig anderen Eingangsbedingungen. Die Datensätze heißen „Ensembles”.Jedes Beispiel beschreibt einem möglichen Wetter-Pfad, und durch die Zusammenstellung des Satzes wird eine Verteilung möglicher Zielentwicklungen erzeugt. Für Wettervorhersagen zeigen sie mit dem Spitzenwert ihre Vorhersage an. Interessanterweise gibt es bei dieser Art von Modell-Auswertung wahrscheinlich mehr als nur eine Antwort, also mehr als einen Spitzenwert, aber über die anderen, auch möglichen Entwicklungen, wird nicht gesprochen. In der Statistik heißt dieses Verfahren „Monte Carlo Methode“.Beim Klimawandel wird das Modell so modifiziert, dass mehr CO2 simuliert wird, mehr Sonneneinstrahlung oder andere Parameter von Interesse. Und dann wird ein neues Ensemble gerechnet. Die Ergebnisse stellen eine Serie von Verteilungen über der Zeit dar, keine Einzelwerte, obwohl die von den Modellierern gegebenen Informationen die alternativen Lösungen nicht angeben, nur den Spitzenwert.Die Modelle werden nach der Beobachtung der Erde geschrieben. Landmassen, Luftströmungen, Baumbedeckung, Eisdecken, usw. werden modelliert. Sie sind eine große intellektuelle Errungenschaft, stecken aber noch immer voller Annahmen. Und wie man erwarten kann, sind die Modellierer stets bemüht, das Modell zu verfeinern und neue Lieblingsfunktionen zu implementieren. In der Praxis gibt es aber nur ein wirkliches Modell, weil alle Veränderungen rasch in alle eingebaut werden.Schlüsselfragen der Debatte sind die Interaktionen zwischen den Funktionen. So beruht die Hypothese vom Durchgehen der Temperaturen nach oben infolge von erhöhtem CO2 darauf, dass die Permafrostböden in Sibirien durch erhöhte Temperaturen auftauen würden und dadurch noch mehr CO2 freigesetzt würde. Der daraus resultierende Feedback würde uns alle braten. Das ist eine Annahme. Die Permafrostböden mögen auftauen oder auch nicht, die Auftaugeschwindigkeit und die CO2-Freisetzung sind keine harten wissenschaftlichen Fakten, sondern Schätzungen. So gibt es Tausende von ähnlichen „besten Abschätzungen“ in den Modellen.Wie wir bei den inkrementell lernenden Systemen gesehen haben, ist allzu viel Komplexität genau so fatal, wie zu wenig. Niemand weiß, wo sich die derzeitigen Modelle auf der Graphik oben befinden, weil die Modelle nicht direkt getestet werden.Jedoch macht die chaotische Natur des Wetters alle diese Argumente über die Parameter zunichte. Wir wissen natürlich, dass Chaos nicht die ganze Wahrheit ist. Es ist in den ferner vom Äquator gelegenen Regionen im Sommer im Durchschnitt wärmer als im Winter geworden. Monsune und Eisregen kommen regelmäßig jedes Jahr vor und daher ist die Sichtweise verführerisch, dass das Chaos wie das Rauschen in anderen Systemen aussieht.
Das von den Klimawandel-Anhängern benutzte Argument geht so: Chaos können wir wie Rauschen behandeln, daher kann das Chaos „herausgemittelt“ werden.
Um ein wenig auszuholen: Diese Idee des “Ausmittelns” von Fehlern/Rauschen hat eine lange Geschichte. Nehmen wir das Beispiel von der Höhenmessung des Mount Everest vor der Erfindung von GPS und Radar-Satelliten. Die Methode der Höhenermittlung war, auf Meereshöhe mit einem Theodoliten zu beginnen und die lokalen Landmarken auszumessen, indem man deren Abstand und Winkel über dem Horizont maß, um die Höhe zu schätzen. Dann wurde von den vermessenen Punkten aus das Gleiche mit weiteren Landmarken gemacht. So bewegte man sich langsam im Binnenland vor. Zum Zeitpunkt der Ankunft der Landvermesser am Fuße des Himalaja beruhten ihre Messungen auf Tausenden vorhergehenden Messungen. Alle mit Messfehlern. Im Endeffekt lag die Schätzung der Vermesser von der Höhe des Everest nur um einige zig Meter daneben.Das kam, weil die Messfehler selbst eine Tendenz zum Ausmitteln hatten. Wenn ein systemischer Fehler drin gewesen wäre, etwa von der Art, dass jeder Theodolit um 5 Grad zu hoch gemessen hätte, dann wären die Fehler enorm groß geworden. Der Punkt dabei ist, dass die Fehler dann keinen Bezug zum vermessenen Objekt gehabt hätten. Es gibt viele Beispiele dafür in der Elektronik, in der Radio-Astronomie und auf anderen Gebieten.Sie verstehen nun, dass die Klimamodellierer hoffen, dass das auch für das Chaos gilt. Sie behaupten ja tatsächlich, dass es so wäre. Bedenken Sie aber, dass die Theodolitenfehler nichts mit der tatsächlichen Höhe des Everest zu tun haben, wie auch das Rauschen in Radioteleskopverstärkern nichts mit den Signalen von weit entfernten Sternen zu tun hat. Das Chaos dagegen ist Bestandteil des Wetters. Daher gibt es keinerlei Grund, warum sich das „ausmitteln“ würde. Es ist nicht Bestandteil der Messung, es ist Bestandteil des gemessenen Systems selbst.Kann Chaos überhaupt „ausgemittelt“ werden? Falls ja, dann müssten wir bei Langzeitmessungen des Wetters kein Chaos erkennen. Als eine italienische Forschergruppe um meine Chaos-Analyse-Software bat, um eine Zeitreihe von 500 Jahren gemittelter süditalienischer Wintertemperaturen auszuwerten, ergab sich die Gelegenheit zur Überprüfung. Das folgende Bild ist die Ausgabe der Zeitreihe mittels meines Chaos-Analyse-Programms „ChaosKit“.
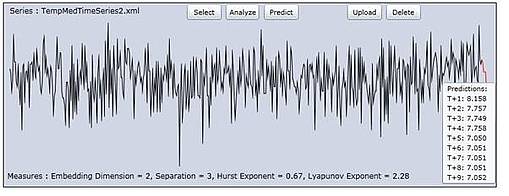
Ergebnis: Ein Haufen Chaos. Der Lyapunov-Exponent wurde mit 2.28 Bits pro Jahr gemessen.
Auf gut Deutsch: Die Treffsicherheit der Temperaturvorhersage vermindert sich um den Faktor 4 für jedes weitere Jahr, für welches eine Vorhersage gemacht werden soll, oder anders herum: die Fehler vervierfachen sich.
Was heißt das? Chaos mittelt sich nicht aus. Das Wetter bleibt auch über Hunderte von Jahren chaotisch.
Wenn wir einen laufenden Durchschnitt über die Daten bilden würden, wie es die Wettermodellierer tun, um die unerwünschten Spitzen zu verbergen, können wir eine leichten Buckel rechts sehen, und viele Buckel links. Wäre es gerechtfertigt, dass der Buckel rechts ein Beweis für den Klimawandel ist? Wirklich nicht! Man könnte nicht entscheiden, ob der Buckel rechts das Ergebnis des Chaos und der angezeigten Verschiebungen wäre, oder ob da ein grundlegender Wandel wäre, wie zunehmendes CO2.
Fassen wir zusammen: die Klimaforscher haben Modelle konstruiert auf der Grundlage ihres Verständnisses des Klimas, derzeitigen Theorien und einer Reihe von Annahmen. Sie können ihre Modelle wegen der chaotischen Natur des Wetters nicht über kurze Zeiträume testen, das geben sie zu.
Sie hofften aber, dass sie kalibrieren könnten, ihre Modelle bestätigen oder reparieren, indem sie Langzeitdaten auswerteten. Aber wir wissen jetzt, dass auch dort das Chaos herrscht. Sie wissen nicht, und sie werden niemals wissen, ob ihre Modelle zu einfach, zu komplex oder richtig sind, weil – selbst wenn sie perfekt wären – angesichts der chaotischen Natur des Wetters keine Hoffnung besteht, die Modelle an die wirkliche Welt anpassen zu können. Die kleinsten Fehler bei den Anfangsbedingungen würden völlig unterschiedliche Ergebnisse hervorbringen.
Alles, was sie ehrlich sagen können, ist: “Wir haben Modelle geschaffen, wir haben unser Bestes getan, um mit der wirklichen Welt im Einklang zu sein, aber wir können keinen Beweis für die Richtigkeit liefern. Wir nehmen zur Kenntnis, dass kleine Fehler in unseren Modellen dramatisch andere Vorhersagen liefern können, und wir wissen nicht, ob wir Fehler in unseren Modellen haben. Die aus unseren Modellen herrührenden veröffentlichten Abhängigkeiten scheinen haltbar zu sein.“
Meiner Ansicht nach dürfen regierungsamtliche Entscheider nicht auf der Grundlage dieser Modelle handeln. Es ist wahrscheinlich, dass die Modelle so viel Ähnlichkeit mit der wirklichen Welt haben wie Computerspiele.
Zu guter Letzt, es gibt eine andere Denkrichtung in der Wettervorhersage. Dort herrscht die Meinung, dass das Langzeitwetter großenteils von Veränderungen der Sonnenstrahlung bestimmt wird. Nichts in diesem Beitrag bestätigt oder verwirft diese Hypothese, weil Langzeit-Aufzeichnungen der Sonnenflecken enthüllen, dass die Sonnenaktivität ebenfalls chaotisch ist.
Dr. Andy Edmonds
Übesetzt von Helmut Jäger EIKE
Anmerkung von Antony Watts: Nur damit wir uns gleich verstehen: Chaos beim Wetter ist NICHT dasselbe wie der oben beschrieben Klimazusammenbruch – Anthony
Den Originalbeitrag finden Sie hier
Kurzbiografie
Dr. Andrew Edmonds ist Wissenschaftler und schreibt Computer Software. Er hat viele frühe Computer Software Pakete auf dem Gebiet der „Künstlichen Intelligenz“ entworfen und er war möglicherweise der Autor des ersten kommerziellen „Data Mining“ Systems. Er war Vorstandssprecher einer amerikanischen Aktiengesellschaft und bei mehreren erfolgreichen Firmen-Neugründungen tätig. Seine Doktorarbeit behandelte die Vorhersagen von Zeitreihen in chaotischen Reihen. Daraus entstand sein Produkt ChaosKit, des einzigen abgeschlossenen kommerziellen Produkts für die Analyse von Chaos in Zeitreihen. Er hat Papiere über Neuronale Netze veröffentlicht und über genetisches Programmieren von „fuzzy logic“ Systemen, „künstlicher Intelligenz“ für den Handel mit Finanzprodukten. Er war beitragender Autor von Papieren auf den Gebieten der Biotechnologie, des Marketings und des Klimas.
Seine Webseite: http://scientio.blogspot.com/2011/06/chaos-theoretic-argument-that.html














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Sehr geehrter Herr Klasen,
ich finde es traurig bis entsetzlich, dass 85% bis 99% meiner Landsleute Opfer einer massiven Propaganda geworden sind, so wie ich es vor Jahrzehnten in einer anderen Richtung war. Mit meinen Beiträgen versuche ich in der Regel, ohne wissenschaftliche Abschweifungen die Logik und den gesunden Menschenverstand anzuregen. In der Hoffnung, dass offensichtliche Widersprüche leise Zweifel hervorrufen, die das Fundament der ideologischen Gedankensperre langsam bröckeln lassen.
Mit NB und NF sind gegenseitig bereichernde Diskussionen nicht möglich, da sie die Argumentation und Fakten nicht folgen, sondern Stichpunkte aus dem Zusammenhang reißen und mit physikalischen Oberwissen oder scheinbare Nachweise wie Computerspiele dann zerpflücken.
Ob sie Betonköpfe sind oder im fremden Auftrag handeln ist mir gleich. Ich erwarte von niemanden, meine Meinung unkritisch zu übernehmen, aber von jedem Diskussionspartner, dass er zumindest zuhört.
Seitdem ich EIKE entdeckt habe, habe ich nicht mehr das Gefühl, dass ich allein in einer von allen guten Geistern verlassenen Welt geblieben bin.
Schönes Wochenende
PG
Sehr geehrter Hr. Georgiew,
Hr. Baecker und Hr. Fischer können mich nicht ärgern. Ich lese lange genug in diesem Forum, als dass ich diese beiden Synonyme mehr als genug kenne, auch bereits als NF und NB.
Es ist traurig mitanzusehen, dass zwei, angeblich Naturwissenschaftlich ausgebildete Menschen, sich hinter Synonymen verstecken, anstatt sich offen zu den Thesen, welche sie hier vertreten (müssen?!) zu bekennen. Insofern sollten wir ein wenig Rücksicht nehmen auf zwei, vielleicht zu tiefst frustrierte, Opfer ihrer eigenen Gesinnung.
Lieber Herr Klasen,
eine sinngemäß ähnliche Disskussion habe ich vor Monaten mit Fischer und Baecker (damals NF und NB)geführt, es hat keinen Sinn, es hilft nur ignorieren.
Genau so, wie mein Sohn sich stark fühlt, weil er in 30 Minuten 60 Monster besiegt hat, fühlen sich NB und NF schlau, weil eine Computersimulation Ihnen einen „Nachweis“ geliefert hat. Alle 3 haben zumindest temporär Probleme damit, Realität und virtuelle Welt exakt auseinanderzuhalten.
NB und NF wollen oder können nicht verstehen, dass ein jeder Computer ausschließlich nur das anzeigt, wass der Programmentwickler und der sapiens an der Tastatur befohlen haben. Dass bei komplexen Programmen das Ergebnis nicht immer 100% vorhersehbar ist und manchmal überrascht, widerspricht dem Grundgedanken nicht. Auf die Klimamodelierung bezogen: Wenn die Modelle bei einem CO2 Anstieg um x% einen Temperaturanstieg von y anzeigen, dann hat man keine neue Erkenntnis oder Nachweis gewonnen, sondern der Programmentwickler und der Bediener haben es im Computerprogramm im Voraus so festgelegt.
Mein Sohn merkt es manchmal, dass er doch nicht so stark ist, NF und NB nicht.
Lassen Sie sich nicht ärgern.
PG
Regionale Klimamodelle (STAR, REMO, CLM) und Tipping Points: Die Öffentlichkeit wird betrogen.
Zum Beispiel: dem STAR Modell des PIK wurde offenbar ein Temperaturtrend von +1.5 Grad bis 2050 zugrunde gelegt (gemäss Publikationen PIK), ohne aufzuzeigen, auf welcher Basis diese Annahme getroffen wurde (wahrscheinlich wieder von vergangenen „frisierten“ Temperaturmessungen stammend).
Ferner fehlen glaubhaft korrekte Abbildungen der Wolkenbedeckung Deutschlands in den nächsten 40 Jahren, die ohnehin jede Prognose lächerlich machen.
Angeblich werden auch Tipping Points in den Klimamodellen abgebildet. Das Problem ist ja nur, dass niemand weiss, was Tipping Points wirklich sind (wahrscheinich PIK’sche Hirngespinste).
Da kann man wieder nur lachen, über die tolle Qualität dieser Klimasysteme.
Herr Klasen, #131
ich nehme Ihnen nicht übel, dass Sie das Thema nicht klären wollen. Wenn Sie dies nicht gestoppt hätten, hätte es es getan. Denn es ist ja völlig offenkundig, dass Sie die wissenschaftliche Sichtweise nicht nachvollziehen können und da irgendwo einen unlösbaren Knoten im Hirn haben, der wohl noch mehr grundlegende Vorarbeit (in mathematischer Statistik, Begriff des stochastischen Prozesses, physikalische Modellbildung, etc. ) erfordert, was in einem solchen blog ohne minimale Vorbildung der blog-Teilnehmer nicht zu leisten ist.
Hr. Baecker,
nehmen sie es bitte nicht übel, aber besser wir beenden die Diskussion über Statistik / Prognosen / Szenarien. Auch mit ihrer Erklärung in #130 komme ich wieder zu meinen Rückschlüssen aus #125, ich denke, wir würden uns Argumentativ im „Kreise“ drehen wenn wir hier weiter machen würden.
Entgegen ihrer Vermutung in #126 habe ich ihre Erklärungen durchaus „kapiert“, weshalb ich hier die Diskussion beende.
Herr Klasen, #129
Nein, auch allgemein sind sie nicht zutreffend:
Sie in #125: „Statistiken lassen sich nur auf ermittelten Daten aufbauen, d.h. sie sind nur gültig für Vergangenes.“
Nicht jede Statistik basiert auf Daten, die zeitlich erhoben werden. Denken Sie mal an die Statistik über Qualitätsparameter von Produkten, die in verschiedenen nominell gleichartigen Maschinen zum gleichen Termin gefertigt wurden (Scharstatistik).
Sie in #125: „Prognosen und Szenarien lassen sich auf Basis dieser Daten in einer fast unendlichen Anzahl errechnen“
Das wäre im allgemeinen sinnlos, da sich die Randbedingungen der Einflußfaktoren der statistischen Gesamtheit für den Prognosezeitraum ändern und vor allem wenn man nicht sicher ist, dass alle relevanten Einflußfaktoren überhaupt erfasst sind. Da das Klima prinzipiell in naher Zukunft auch durch einen Meteroiteneinschlag stark geändert werden kann, man aber nicht weiß, ob und wann dieser eintrifft, ist eine Prognose ohne erhebliches „Restrisiko“ nicht möglich.
Daher macht man „nur“ Szenarien. Diese zeigen auf, was passiert, wenn man Einflußfaktoren ändert.
Diese dienen zu einer Risikoabschätzung durch die quantifizierten Einflußfaktoren. So weiß man zwar nicht, wann ein Meteorit einschlägt oder die CO2-Zunahme tatsächlich so eintrifft (das liegt ja im wesentlich nur an uns), man kann aber ein Szenerium machen, was passieren würde, wenn dies einträfe.
Dazu ist jedoch noch ein weiterer Schritt nötig, und dies haben Sie wohl nicht verstanden.
Szenarien und Prognosen kann man nur machen, wenn man weiß, wie die Statistik durch die Randbedingungen der Einflußfaktoren determiniert wird. Um dies herauszufinden, entwickelt man -wie immer in der Physik- quantitative Modelle.
Wenn nun die Einflußfaktoren in physikalisch hinreichend korrekter Modellierung mit den empirischen Daten aus der Vergangenheit befriedigend übereinstimmen (man quantifiziert den Einfluß einzelner Einflußgrößen indem man in den Daten nach spezifischen Mustern, die charakteristisch für diesen Faktor sind, sucht), kann man es auch wagen, Szenarien für die gezielte Auslenkung eines oder einer Kombination von Einflußfaktoren zu machen. Das Szenarium bzw. die Validierung anhand des inputs der gemessenen Einflußfaktoren des Validierungszeitraums berechnet denselben Typus Daten für die Klimastatistik wie die empirischen Messdaten liefern, nämlich eine Sequenz von Wetterzuständen, aber eben aus dem physikalischen Modell berechnete.
Sie in #125: „sind somit also bestenfalls als Darstellung der eigenen Rechenleistung zu gebrauchen, keinesfalls aber zur Abbildung langfristiger, zukünftiger Entwicklungen.“
Daher macht man es ja auch nicht. Klimaprognosen/szenarien basieren nicht auf der Extrapolationen der Daten der Vergangenheit! Das geht nicht! Siehe meine Erklärungen.
Hr. Baecker,
also sind die Aussagen von mir in #125, mit Aussnahme des Klimas, zutreffend?
Herr Klasen,
weil ich in #119, #121, #122, #124 offensichtlich etwas anderes geschrieben habe als Sie in #125.
Hr. Baecker,
„schade, dass Ise es nach so vielen Versuchen immer noch nicht kapiert haben. Sonst haetten Sie gelernt, dass Ihre Zusammenfassung weder im allgemeinen noch im konkreten Fall des Klimas zutreffend ist.“
Warum?
Herr Klasen,
schade, dass Ise es nach so vielen Versuchen immer noch nicht kapiert haben. Sonst haetten Sie gelernt, dass Ihre Zusammenfassung weder im allgemeinen noch im konkreten Fall des Klimas zutreffend ist.
Sie scheinen mit mathematischer Statistik und Modellbildung nicht viel am Hut zu haben.
Hr. Baecker,
ich fasse mal zusammen:
Statistiken lassen sich nur auf ermittelten Daten aufbauen, d.h. sie sind nur gültig für Vergangenes.
Prognosen und Szenarien lassen sich auf Basis dieser Daten in einer fast unendlichen Anzahl errechnen, sind somit also bestenfalls als Darstellung der eigenen Rechenleistung zu gebrauchen, keinesfalls aber zur Abbildung langfristiger, zukünftiger Entwicklungen.
Herr Klasen, #123
„Das, Hr. Baecker, ergibt doch keinen Sinn. Ich kann doch kein Modell kreieren, mit, wie sie selbst schrieben, unterschiedlichen Randbedingungen, da die restlichen Daten zu unbestimmt sind, um dann darauß eine Statistik für eine zukünftige Prognose zu erstellen.“
Inzwischen sollte es sich rumgesprochen haben, dass man zwischen Prognosen und Szenarien unterscheiden muß. Alles, was Sie je für das Klima der Zukunft gesehen haben, sind Szenarien, die auf Variation der Randbedingungen der modellierten Prozesse beruhen. Da niemand weiß, ob in 50 Jahren ein Meteorit auf der Erde einschlägt und das Klima drastisch ändert, sind Klimaprognosen nicht möglich.
„Mit Verlaub, da kommt lediglich heraus, was der Ersteller dieser Statistik möchte, d.h. mit welchem Ziel wird diese Statistik erstellt.
Dies ist nicht objektiv!“
Das wäre Betrug. Wenn Sie das meinen, so meinen Sie das eben.
Aber Betrug müßte man nicht hinten aufwändigen physikalischen Prozessen verstecken.
„Ich vermutet, sie möchten mir erläutern, dass, durch die gewissenhafte Messung von Daten über einen langen Zeitraum, eine recht sichere Prognose im weitesten Sinne möglich ist.“
Nein, das sollten Sie eigentlich inzwischen verstanden haben! Es gibt keine Prognosen, wenn man nicht die Entwicklung aller relevanten Randbedingungen kennt. Man macht Szenarien im Sinne, was passiert mit dem Klima, wenn z.B. das CO2 in der Atmosphäre verdoppelt wird, die Sonnenenergie sich um 5% erhöht oder Aerosolmengen zunehmen (= Änderung von Randbedingungen). Der geschilderte Fall der Blindprognose fürs Wetter ist nur möglich, wenn man weiß, dass die Randbedingungen konstant sind oder sich nur langsam über den Prognosezeitraum ändern, sodass man von einem stationären Klima ausgehen kann. Dies ist über ein bis 3 Dekaden etwa erfüllt, wenn dazwischen keine drastische Änderungen der Randbedingungen auftreten (Meteoriteneinschlag, z.B.). Man weiß aber, dass eine CO2-Verdopplung eine so große Änderung der Randbedingungen ist, dass das Klima signifikante Änderungen darauf erfahren wird. Aber auch dies ist ein Prozeß, der langsam über Jahrzehnte abläuft.
Hr. Baecker,
Zitat:
„Die Statistik ist Ergebnis des Klimamodells und kann natürlich nur darauf basieren, welche Prozesse das Klimamodell berücksichtigt.“
Das, Hr. Baecker, ergibt doch keinen Sinn. Ich kann doch kein Modell kreieren, mit, wie sie selbst schrieben, unterschiedlichen Randbedingungen, da die restlichen Daten zu unbestimmt sind, um dann darauß eine Statistik für eine zukünftige Prognose zu erstellen.
Mit Verlaub, da kommt lediglich heraus, was der Ersteller dieser Statistik möchte, d.h. mit welchem Ziel wird diese Statistik erstellt.
Dies ist nicht objektiv!
Ich vermutet, sie möchten mir erläutern, dass, durch die gewissenhafte Messung von Daten über einen langen Zeitraum, eine recht sichere Prognose im weitesten Sinne möglich ist. Dem stimmte ich bereits zu, unter #120 machte ich sie Aufmerksam auf die Jahreszeiten mit ihren jeweiligen Wetter. Genauer ist es nicht möglich, zumindest nicht Global, vielleicht noch sehr eng örtlich Begrenzt (einzelne Städte z.B.).
Herr Klasen, #120
Ergänzung zu #121
„“Eine Statistik aus so vielen Unbekannten kann nicht für eine zukünftige Prognose herangezogen werden.“
„Wird sie ja auch nicht! Siehe meine Erläuterungen oben.“
Nochmal klarer: Die Statistik ist Ergebnis des Klimamodells und kann natürlich nur darauf basieren, welche Prozesse das Klimamodell berücksichtigt.
Wenn das Klimamodell nun die Klimazustände der Vergangenheit bei anderen Randbedingungen wie heute und für die Gegenwart richtig (= mit verträglicher Genauigkeit) mit den empirisich ermittelten Klimazuständen für diese Zeiträume liefert, so ist es nicht ganz unberechtigt, dies auch für die Zukunft zu erwarten, sofern man davon ausgehen kann, dass sich dieselben Prozesse aber nur bei evtl. anderen Randbedingungen abspielen.
Und die Statistik der Wetterzustände bei veränderten Randbedingungen eine vergleichbar gut zutreffende Blindprognose für das Wetter liefern als die unter heutigen Randbedingungen.
D.h. das Klima unter gegenüber heute veränderten Randbedingungen in gewissen Genauigkeitsgrenzen genauso determiniert wird ist, wie das heutige
Klima unter den heutigen Randbedingungen oder das der Vergangenheit unter den entsprechenden damaligen Randbedingungen.
Herr Klasen, #120
„danke für ihre Erklärung. “
Bitte.
„Aber selbst mit ihrer Erklärung, kommen wir über einen engen örtlichen Bereich nicht hinaus“
Brauchen wir auch nicht.
„, hinzu kommen weitere Unwägbarkeiten. “
Wofür?
„Letztlich gibt ihre Erklärung nicht mehr aus, als das was jeder Wissen sollte, die Jahreszeiten mit ihrer unterschiedlichen Wetterabfolge.“
Ich schrieb schon, die eintreffende Wettterabfolge ist nur kurzfristig vorhersagbar (wegen der Sensitivität auf die Anfangswertbedingungen) aber dennoch nicht ganz chaotisch, wie sich an dem jährlich wiederholenden Ausbilden charakterischer Wetterzustände im Lauf des Jahres zeigt, eben dies zeichnet ein stationäres oder quasistationäres Klima aus.
Dies setzt jedoch voraus, dass eben die Randbedingungen konstant bleiben!
Bei veränderten Randbedingungen verändern sich i.a. die charakteristischen Wetterzuständen, d.h. das Klima dort verändert sich.
„Eine Statistik aus so vielen Unbekannten kann nicht für eine zukünftige Prognose herangezogen werden.“
Wird sie ja auch nicht! Siehe meine Erläuterungen oben.
Hr. Baecker,
danke für ihre Erklärung.
Aber selbst mit ihrer Erklärung, kommen wir über einen engen örtlichen Bereich nicht hinaus, hinzu kommen weitere Unwägbarkeiten. Letztlich gibt ihre Erklärung nicht mehr aus, als das was jeder Wissen sollte, die Jahreszeiten mit ihrer unterschiedlichen Wetterabfolge. Eine Statistik aus so vielen Unbekannten kann nicht für eine zukünftige Prognose herangezogen werden.
Herr Klasen, #118
„dann sollten sie ihre Aussage präzisieren.“
gerne. Das war tatsächlich zu unpräziese ausgedrückt.
Ich schrieb, das Wetter in einem Zeitraum jenseits von 10 Tagen sei unbestimmt. Dies ist natürlich nicht ganz richtig. Denn ist ist nicht völlig unbestimmt, denn gröbere Aussagen lassen sich ja immer noch machen. So ist es zwar heute nicht klar, ob es am 31. Juli in Berlin Alexanderplatz 1 mm regnen wird oder nicht. Aber man kann mit ziemlicher Sicherheit sagen, dass es nicht schneien wird, die Wahrscheinlichkeit für Regen mit größer-gleich 1mm bei ca. 50% liegt, die Tageshöchsttemperatur mit 90% Wahrscheinlichkeit zwischen 15°C und 30°C liegen wird und mit 99% Wahrscheinlichkeit unter 34°C etc. Das ist wenig im Vergleich zu einer Wettervorhersage aber eben auch nicht Nichts!. Diese Daten sind eine Blindprognose (also ohne Berücksichtigung aktueller Wetterdaten) basierend auf der Klimastatistik. Diese Statistik ist von den Anfangswertbedingungen des Wetterzustandes unabhängig, sondern hängt von den Randwertbedingungen für das Wetter an diesem Ort ab. Wenn diese konstant sind oder sich langsam genug (quasistationär) ändern, kann man die Unbestimmheit des Wetterzustandes zumindest auf seine klimatischen Grenzen eingrenzen.
Klimamodelle berechnen nun Wetterzustände. Diese geben das Wetter nicht korrekt an, da das Chaos auf leicht unterschiedliche Anfangswerte im Laufe weinger Tage zu einem falschen Wetterzustand auslaufen. Dies ist jedoch für den Klimazustand egal, sofern die modellierten Wetterzustände Ensemblemitglieder der Statistik sein können, also zum Klimazustand passen. Mit solchen Tests verifiziert man Klimamodelle. Bei Klimaszenarien spielt man dann durch, wie sich die Wetterstatistik auf Änderungen der Randbedingungen ändert.
Alles klar nun?
Hr. Baecker,
dann sollten sie ihre Aussage präzisieren. Das Klima ist anhand ihrer Aussage unbestimmbar (also für die Zukunft nicht vorhersagbar)!
Lediglich für einen engen örtlichen Bereich, kann eine Statistik des vergangenen Wetters (über 30 Jahre ausgewertet das Klima) erstellt werden. Damit sind aber keinerlei Zukunftsprognosen möglich.
Herr Klasen,
eben nicht. Ist das so schwer zu verstehen?
#110 NB
Das ist ja ein gravierender Unterschied zu den in den technischen Rechenmodellen verwendeten probabilistischen Methoden!
Per Landesrecht sind über die „eingeführten technischen Bestimmungen“ probalilistische Methoden für sicherheitsrelevante technische Rechenmodelle gesetzlich vorgeschrieben. Hier wird mit dem Quantil von (chaotisch) streuenden Parametern gearbeitet. Zusätzliche werden diese mit probabilistisch zu ermittelnden, bzw. semiprobabilistisch genormten Sicherheitsfaktoren beaufschlagt. Als Ergebnis erhält man lediglich eine Grenzwertbetrachtung, welche das gewünschte Sicherheitsniveau mit einer Wahrscheinlichkeit von z. B. 1:1 Million nicht unterschreiet.
Sobald es ein wenig komplexer wird, sind seriös nur Schranken der möglichen Ergebnisse mit Rechenmodellen zu ermitteln.
Man kann also nur vorausberechnen: „Mit einer Wahrscheinlichkeit von X liegt das Ergebnis in einem Bereich von Y bis Z. Genaueres lässt sich leider nicht berechnen.“
Es ist toll, das die Menschheit mittlerweile über solche Berechnungsmethoden verfügt. Aber durch die große Streubreite der Ergebnisse, z. B. bei realen Versuchen, stellt sich sofort wieder Frustration und Demut ein.
Hr. Baecker,
Zitat in #114:
„D.h. das Wetter nach ein paar Tagen unbestimmt ist. Das Klima ist die Statistik des Wetters und die ist für beide Kurven aber gleich!“
Also ist Klima genauso unbestimmbar wie das Wetter, oder was möchten sie mit ihrer Aussage darstellen?
hier ein weiteres Beispiel für berechenbares Chaos.
x(n+1) = r*x(n)*{1-x(n)}
http://en.wikipedia.org/wiki/Logistic_map
„At r approximately 3.57 is the onset of chaos, at the end of the period-doubling cascade. From almost all initial conditions we can no longer see any oscillations of finite period. Slight variations in the initial population yield dramatically different results over time, a prime characteristic of chaos. “
Um die Analogie zum Klima herzustellen: man möge die x(n) als Wetterzustände über die Zeit ansehen. Eine kleine Änderung in x(1) führen im chaotischen r-Regime dazu, dass ab ungefähr x(20) die beide Kurven weit auseinandergehen. D.h. das Wetter nach ein paar Tagen unbestimmt ist. Das Klima ist die Statistik des Wetters und die ist für beide Kurven aber gleich!
„Denken Sie doch an einen der Pioniere des Chaosforschung, den Metereologen Edward N. Lorenz
und seinen „Schmetterlingseffekt“.
= Nichtberechenbarkeit!“
Was soll an den Lorenzgleichungen nichtberechenbar sein? Haben Sie noch nie die Lösungen graphisch abgebildet gesehen?
Der Schlußsatz meiner Ausführungen war:
@ #103: Jochen Ebel, 27.06.2011, 11:22
„Obwohl diese Vergleiche Ihre Ausführungen die Richtigkeit des Treibhauseffekts nahelegen werden sie ihn wahrscheinlich wieder bestreiten.“
– und Sie haben meine Prognose bestätigt:
@ #111: Dr.Paul, 28.06.2011, 19:52
„… die Richtigkeit des Treibhauseffekts …
richtig wäre:
… die Unrichtigkeit des Treibhauseffekts …“
@ #111: Dr.Paul, 28.06.2011, 19:52
„seinen „Schmetterlingseffekt“ = Nichtberechenbarkeit!“
des Wetters über längere Zeit.
Aber das Thema des Threads ist nicht das Wetter, sondern das Klima:
@ #111: Dr.Paul, 28.06.2011, 19:52
„Das war doch hier das Thema“
MfG
#103: Herzlichen Dank Herr Jochen Ebel,
für die sinnvollen Ergänzungen,
allerdings ist Ihnen im Schlusssatz eine kleiner Tippfehler unterlaufen,
den ich hiermit korrigieren möchte:
„Obwohl diese Vergleiche Ihre Ausführungen die Richtigkeit des Treibhauseffekts …“
richtig wäre:
Obwohl diese Vergleiche Ihre Ausführungen die Unrichtigkeit des Treibhauseffekts …
Denken Sie doch an einen der Pioniere des Chaosforschung, den Metereologen Edward N. Lorenz
und seinen „Schmetterlingseffekt“.
= Nichtberechenbarkeit!
Das war doch hier das Thema 🙂
Gruß
Herr Statiker, #105
„Um den (chaotisch) streuenden Parametern zu begegnen wird bei technischen Rechenmodellen mit probabilistischen bzw. semiprobabilistischen Methoden gearbeitet.“
Bei Ensemblerechnungen der operativen Wettermodelle oder die wenigen durchgeführten bei Klimamodellen werden nur die Anfangsbedingungen probabilistisch in plausiblen Grenzen variiert, die Zeitentwicklung des Klimasystems wird aus dem Gleichungssatz deterministisch numerisch integriert.
Man setzt also zum Rechnungsstartzeitpunkt des Klimamodells, dieser liegt in der Vergangenheit, z.B. 1980, nicht nur die zu dem Datum gemessenen Wetterdaten und die Daten der externen forcings (Sonne, Vegetation, Meeresströmungen, Treibhausgase) als Anfangswerte zur Integration der dynamischen Gleichungen an, sondern variiert den Wetter- (und evtl. Ozean-) -zustand innerhalb klimatologisch plausibler Grenzen des Startpunktes.
#107: NicoBaecker sagt:
„Aber lassen Sie doch der Fairness wegen wenigstens das ständige Anfeinden mit ad hominem Argumenten.“
Herr Baecker, ich hatte Sie bislang für humorlos gehalten, ich hab mich ja sowas von geirrt ;-). Sehr pointiert, wirklich, und dies Selbstironie, einfach nur gut. Weiter so!
@ #107
O-Ton Baecker: “ Aber lassen Sie doch der Fairness wegen wenigstens das ständige Anfeinden mit ad hominem Argumenten.“ Da barmt der Richtige! Ich lade jeden ein an Hand seiner Beiträge nachzuprüfen, ob er sich an seine eigene Regel hält. Beiträge gibt es ja genug.
Michael Weber
Herr Weiss,
wenn Sie meine Beiträge nicht verstehen und glauben, besser zu wissen, was Wissenschaft ist als Lehrbücher, Uniangestellte und Veröffentlichungen, so lasse ich Sie in dem Glauben. Ich habe festgestellt, dass es sinnlos ist, Menschen, die schon so weit abgedriftet sind, noch zum Nachdenken zu bringen.
Aber lassen Sie doch der Fainess wegen wenigstes das ständige Anfeinden mit ad hominem Argumenten.
@104 Bäcker:
Ich wage hier die Prognose, dass Sie wahrscheinlich niemals KAPIEREN werden, wie weit Sie und die Ihrigen (IPCC, die von Ihnen als „populäre Klimagurus“ bezeichneten Schellnhuber und Rahmsdorf, etc.) von wahrer Wissenschaftlichkeit entfernt sind. Ihre Auslassungen über Klimamodelle sind ein beredtes Beispiel dafür: dass diese mit Wissenschaft nicht das Geringste zu tun haben, entgeht Ihnen dabei – selbstredend – vollkommen.
Dafür, dass Ihre pseudo-wissenschaftliche Basis dermassen dürftig ist, nehmen Sie den Mund ungebührlich voll (zum Beispiel gegenüber Herrn Schneider). Ich haben Ihnen schon x-mal gesagt, dass Sie sich nur schon durch die Art und Weise Ihrer Ausdrucksweise (zum Beispiel in Form penetranter Besserwisserei, die notabene durch nichts begründet ist, durch verlächerlichende Verhöhnung Ihrer Diskussionspartner hier, und weitere sehr negative Ausdrucksformen im Sinne von Zynismen, Sarkasmen, etc.) sich den üblichen Umgangsformen von wahren Wissenschaftlern weit entfernt zeigen, und Ihrer Sache, Ihrem quasi-religiösen CO2-Glauben, der wissenschaftlich von einer beispiellosen Primitivität und Verwahrlosung wissenschaftlicher Prinzipen zeugt (Behauptungen, Spekulationen, Prophezeiungen der Öffentlichkeit als Wahrheit auszugeben), nicht den geringsten Dienst tun (Gott sei Dank). Dadurch wird ja für alle, die Ihre Texte hier lesen, überdeutlich klar, wes Geistes Kind Sie sind und durch welches Weltbild Sie geführt sind. Mit wissenschaftlichen Prinzipien der unbedingten Vorurteilsfreiheit der untersuchten Sache gegenüber hat Ihr geistiges Korsett nicht das Geringste gemein, weswegen Sie auch niemals für einen wahren Wissenschaftler gehalten werden können.
Wenn es endlich gelänge, die Öffentlichkeit von der Unsinnigkeit einer „Globaltemperatur“ gründlich zu überzeugen, zerfällt Ihre ganze CO2 Welt sofort vollkommen: Sie haben dann kein Spielzeug mehr für Ihre Computerspiele alias Klimamodelle und es wird Ihnen niemand mehr zuhören, wenn Sie etwas vom drohenden Ertrinkungstod vieler Millionen Menschen in 500 Jahren daherfaseln …
Um den (chaotisch) streuenden Parametern zu begegnen wird bei technischen Rechenmodellen mit probabilistischen bzw. semiprobabilistischen Methoden gearbeitet.
Seriöse Berechnungen „auf den Punkt“ sind leider nur bei sehr einfachen Systemen machbar, wenn ein analytischer Lösungsansatz vorliegt.
So ist es z. B. nicht möglich, das Schwingungs- und Dämpfungsverhalten einer Fußgängerbrücke halbwegs brauchbar (richtig!) vorher zu berechnen. Für erforderliche Schwingungstilger und Schwingungsdämpfer erfolgt die Auslegung durch Messungen am gebauten Objekt.
Es sei auf die diesbezügliche umfangreiche technische Fachliteratur und z. B. DIN 1055-100 verwiesen.
Lieber Herr Schneider, #89
„und halten grundsätzlich alle andern Leute für dämlich.“
So würde ich das nicht formulieren, es hängt von den Leuten ab.
„Und lesen können Leute wie Sie auch nie“
Nun, das trifft für Sie offensichtlich nicht weniger zu!
Herr Schneider,
ich mußte ja schon über Sie lachen. Sie haben meinen Beitrag #91 auch nicht richtig gelesen oder zumindest nicht verstanden, wie kämen Sie sonst auf diese dumme Frage:
„Was glauben Sie, warum alle Klimaforscher, die mit der Erstellung von Klima- Simulations- Software befasst sind, sich die Mühe machen alle möglichen physikalischen Vorgänge die ich genannt habe, bis hin zum Einfluss der Sonne zu integrieren, wenn die Sache so einfach wäre wie Sie tun, dass alles nur eine Frage der Statistik ist?“
Es steht doch eindeutig dort, dass die Ausgangsdaten für die Angabe des Klimazustandes Wetterdaten sind.
Ich schrieb in #91, dass ein Klimamodell Wetterzustände entsprechend der relevanten physikalischen Prozesse inkl. externer wie der Sonnenaktivität und der Wechselwirkung mit anderen Geobiosphären modelliert, und dies die Daten für die Ermittlung des Klimazustandes sind, der mitnichten alleine den mittleren Wetterdaten entspricht, sondern die Kennzahlen der statistischen Verteilung der Wetterzustände!
Also nochmal für jeden Halbgebildeten unmissverständlich: ein Klimamodell modelliert Wetterzustände, die Statistik davon ist das Modellklima, genauso wie man aus realen Wettermessdaten den realen Klimazustand bestimmt!
Dr.Paul ich bin verblüfft von Ihnen mal etwas fast Richtiges zu lesen:
@ #101: Dr.Paul, 26.06.2011, 22:18
„Entropie ist eine extensive Größe in der Thermodynamik … und zwar definiert als Anzahl der Möglichkeiten.“
Ihren folgenden Satz, würde ich umstellen:
@ #101: Dr.Paul, 26.06.2011, 22:18
„In einem geschlossenen System verlangt der 2.HS immer die maximale Entropie,“
und zwar so:
„Ein geschlossenes System strebt immer dem Zustand maximaler Entropie zu, was der 2.HS beschreibt.“
In ihren folgenden Satz gehört auch noch „und Energieabfuhr mit Entropieabfuhr“, also statt
@ #101: Dr.Paul, 26.06.2011, 22:18
„in dem sich durch die beständige Energiezufuhr „stabile“ Zustände weit ausserhalb des thermodynamischen Gleichgewichts einstellen können,“
besser:
„in dem sich durch die beständige Energiezufuhr und Energieabfuhr mit Entropieabfuhr „stabile“ Zustände weit ausserhalb des thermodynamischen Gleichgewichts einstellen können,“
das beweisen z.B. die Lebewesen, die mit ständiger Energiezufuhr (Nahrung) und Energieabfuhr mit Entropieabfuhr (Wärmeabgabe des Lebewesens) stabil über lange Zeit leben (analog Klima). Dabei laufen gleichzeitig chaotische Vorgänge ab (z.B. Arbeit des Darmsystems usw.) (analog Wetter).
Obwohl diese Vergleiche Ihre Ausführungen die Richtigkeit des Treibhauseffekts nahelegen werden sie ihn wahrscheinlich wieder bestreiten.
MfG
@89 M. Schneider
Eine der grössten Unzulänglichkeiten in vielen Debatten – allgemein – ist das gleiche Verständnis der Debattanten der Definition wichtiger Begriffe, in Ihrem Wortwechsel mit Herrn Bäcker hier des Begriffs „Klima“. Da stellt sich schon gleich mal die Frage, wer den Inhalt eines bestimmten Begriffs allgemeingültig definiert. Wörterbücher, Nachschlagewerke, etc. gelten da ja im Allgemeinen als verbindliche Referenzwerke. Ich denke, dass die von Ihnen angeführte Definition von „Klima“ aus Wikipedia dem Anspruch eines, von der Allgemeinheit der Bürger und Spezialisten (besonders Meteorologen) des deutschen Sprachraums verstandenen und akeptierten, Inhalts des Begriffs gerecht wird.
Die Definition des Begriffs „Klima“ durch die sogenannte „Klimawissenschaft“ als eine statistische Grösse weicht eindeutig von der von Ihnen zitierten Definition ab. Um also Missverständnissen und Verwechslungen vorzubeugen wäre von der Klimawissenschaft zu fordern, ihren Begriff „Klima“ anders zu nennen, zum Beispiel „Amilk“.
Wenn Herr Bäcker dann von „Amilk“ spricht, wüsste man genau, dass er vom 30-jährigen Durchschnitt als „global“ berechneter Werte zum Beispiel der Temperatur 1.5 Meter über der Erdoberfläche spricht.
Die dem Geiste des IPCC nahestehende Klimawissenschaft arbeitet aber systematisch mit der Usurpation umgangssprachlicher, daher der Durchschnittsbevölkerung wohlgeläufiger, Begriffe, wie zum Beispiel „Treibhausgas“, „Klima“, „Globaltemperatur“, „globaler Meeresspiegel“, etc. Jeder dieser Begriffe ist für einen Durchschnittsbürger aber missverständlich und es werden völlig falsche Assoziationen geweckt, mit Absicht. Diese Absicht ist unwissenschaftlich und schäbig, da das Publikum vorsätzlich in die Irre geführt wird. Man will aber ja alarmieren und Aufmerksamkeit erregen, und Al Gore will ja viel Geld verdienen und wichig sein ….
Entropie ist eine extensive Größe in der Thermodynamik
wenn man sich auf die Physik beschränkt (was zunächst sinnvoll ist)
und zwar definiert als Anzahl der Möglichkeiten.
In einem geschlossenen System verlangt der 2.HS immer die maximale Entropie,
das heist hier verteilt sich „Molekülbewegung“ überall gleichmäßig, man kann es auch als maximale Unordnung bezeichnen, was aber möglicherweise zu Fehlschlüssen führt.
Eine Tablette Süßstoff hat sich also in einer Tasse Kaffee nach einer gewissen Zeit völlig gleichmäßig im Kaffee verteilt, auch ohne Umrühren. Mit Rühren geht es nur etwas schneller.
Entropie ist also nicht Energie oder Wärme selbst sondern ein Maß der Gleichmäßigkeit oder Ungleichmäßigkeit der Verteilung in einem dynamischen System.
Dabei ist die „Gleichmäßigkeit“ gemeint als größtmögliche (Bewegungs)freiheit.
Damit steigt die Entropie z.B. wenn ein Gasvolumen sich ausdehnen kann
und umgekehrt muss man nach dem 2.HS (äußere) Energie aufwenden (Druck) um das Gasvolumen wieder zu verkleinern und damit die Anzahl der Möglichkeiten für die Elemente wieder zu verringern.
Was die Relevanz für die Berechenbarkeit von Wetter und Klima anbelangt, ist sie deshalb nicht entscheidend,
weil die Erde thermodynamisch alles andere als ein geschlossenes System darstellt.
Sie liegt zwischen der heißen Sonne und dem kalten Weltall als dissipatives System,
in dem sich durch die beständige Energiezufuhr „stabile“ Zustände weit ausserhalb des thermodynamischen Gleichgewichts einstellen können,
worüber auch die Chaostheorie etwas aussagen kann.
Das sind Zustände die nach der Thermodynamik extrem unwahrscheinlich sind und auch statistisch nicht berechenbar sind.
Es ist eine (zeitlich begrenzte) Stabilität in der Bewegung, nicht in der Ruhe, die der kontinuierlichen Energiezufuhr bedarf.
Neben den bekannten Wetterkapriolen ist die unwahrscheinlichste Erscheinung im Sinne der Entropie die Entstehung von Leben (maximale chaotische Ordnung).
Nach Alt (Aachen) könnten die Pflanzen durch ihre Photosynthese den gesamten CO2 Vorrat der Atmosphäre in nur 6 Jahren verbrauchen.
#87
Lieber Herr Pual
Ich: „Chaostheorie ist Bestandteil der Mathematik. Mathematik ist keine Naturwissenschaft“
Sie: „Falsch!
Chaostheorie ist spätestens seit den 70ger Jahren ein anerkannter Zweig der Naturwissenschaft. Anwendungsbeispiele habe ich genannt!“
Es bleibt dabei, Chaos_theorie_ ist Bestandteil der Mathematik. Auch wenn sie von Naturwissenschaftlern henutzt wird, bleibt sie Mathematik. Wollen Naturwissenschaftler mit ihr etwas beschreiben, erstellen sie Modelle. Solange sie nur mit dem Modell arbeiten, ist es Mathematik. Naturwissenschaft wird es erst, wenn die Güte des Modell durch Experimente geprüft wird. Das sollten die AGWler erkennen, denn bei ihnen fehlen Experimente. Aber auch Sie sollten nicht stets den gleichen Fehler wie die AGWler machen: Ein mathematisches Modell ist nicht die Realität.
Lieber Herr Bäcker,
ich bin trotzdem anderer Meinung. Das Ensemblemittel nehmen heißt in einem nichtlinearen Modell, auch wenn es im Verifikationszeitraum geklappt hat meines Erachtens nur, dass man hoffen kann, dass es auch im Vorhersagezeitraum funktionieren könnte.
Weiter sind wir im Moment noch nicht. Zumindestens was ich bisher gelesen habe, aber vielleicht haben sie ja ein Zitat.
Zunächst mit der jetzigen Computerkapazität, dem jetzigen Verständnis zur Parametrisierung der Fundamentalprozess bereitet meines Erachtens auch noch eine assagekräftige Verifikation und die Vorhersage Schwierigkeiten.
Das erscheint mir aber normal für ein komplexes System.
Mit freundlichen Grüßen
Günter Heß
Lieber Herr Kinder,
sie können sich gerne ihre eigene Physik zusammenbasteln, aber die Thermodynamik ist so präzise wie immer. Zugegeben man muss sich sehr genau an die Definitionen halten, sonst kommt Unfug heraus. Ich persönlich habe festgestellt, dass es moderngeworden ist, die klassische Thermodynamik als Schrott zu bezeichnen. Diese Ausrede war zu meinen Unizeiten schon immer bei Nebenfächlern beliebt, die Schwierigkeiten damit hatten.
Ich bin allerdings nachwievor ein Fan von klassischer, irreversibler und statistischer Thermodynamik.
Und glauben sie mir so wie ich Ihnen den Zusammenhang zwischen Zustandsgrößen, Zustandsvariablen, totalem Differential , Entropie und Wärme beschrieben habe, kann man die Thermodynamik sehr gut benutzen und wird sie auch in allen Naturwissenschaften zum Erkenntnisgewinnbenutzt.
Und das ist ja letztendlich das Entscheidende.
Immerhin muss jedes physikalische Modell der Natur nach wie vor thermodynamisch konsistent sein, sonst muss es verworfen werden.
Zugegeben es wird viel Schrott über die Entropie gesagt und geschrieben, ihr synonymer Gebrauch von Entropie und Wärme gehört dazu.
Thermodynamik, Herr Kinder, ist kein Schrott, sondern das Fundament unserer Naturwissenschaft.
Mit freundlichen Grüßen
Günter Heß
Werter Herr Heß (#90),
„Entropie ist eine Zustandsfunktion und Wärme nicht. Die Entropie hat ein totales Differential, die Wärme nicht.“
Sie wollen mir bestimmt damit sagen, dass die momemtane Thermodynamik ein Haufen Schrott ist. Damit haben Sie nicht mal Unrecht. Die momentane Thermodynamik hat halt einige Krücken, mit denen sie durch die Wissenschaft humpelt.
Es gibt drei Größen, die Temperatur T, die Entropie S und die einer Arbeit gleichwertige Größe Q – „auf die der Name Wärme paßt“.
Temperatur T -> Wärme(-stärke)
Entropie S -> Wärme(-menge)
Arbeit/Energie Q -> Wärme(-arbeit/energie) -> Wärme(-menge)
Indem man der energetischen Größe Q die Bezeichnung „Wärmemenge“ gab und damit die ganzen Assoziationen, die mit diesem Wort verbunden sind, an diesem Begriff knüpfte, konnte man die Größe S nicht mehr anschaulich deuten; sie konnte nur formal eingeführt werden und mußte abstrakt bleiben. In dieser Lage wurde die Theorie noch dadurch fixiert, daß man die Gleichwertigkeit von Wärme und Arbeit zum ersten Hauptsatz der Wärmelehre erklärte und diesen Satz zu einem Eckpfeifer des ganzen Lehrgebaudes machte. Dies führte zu einem unlösbaren Widerspruch zwischen Theorie und Anschauung sowie zu einer Flut von abstrakten Begriffen.
Deshalb müssen dann Zwischen-Zustandsfunktionen (Krücken) wie Enthalpie (Wärmeinhalt) und Freie Energie definiert werden, um das Thermodynamik-Gebäude so einigermaßen im Lot zu halten. Dann wird eine Wärmekapazität definiert, die es eigentlich laut „momentaner Thermodynamik“ nicht geben drüfte, denn diese „Wärmekapazität“ ist in der Realität eine Entropiekapazität.
Mfg.
W. Kinder
@ #88: W. Kinder, 26.06.2011, 03:50
„Tatsächlich ist die Entropie aber eine der am leichtesten zu messenden Größen überhaupt.“
Unzutreffend. Entropie kann man gar nicht messen. Messen kann man z.B. Temperatur, Masse und einiges mehr, z.B. Energie, von der eine bestimmte Teilmenge die Wärme ist. Außer Energie in Form von Wärme gibt es z.B.
kinetische Energie,
potentielle Energie,
chemische Energie usw.
Entropie ist allein ein mathematisches Konstrukt, wobei man bei TdS = dQ in Wirklichkeit von dem anderen Zusammenhang dS = dQ/T ausgeht, weil dQ und T wirklich meßbare Größen sind. Dabei geht man davon aus, das sich in den Körper, der die Energie dQ erhält sich die Wärme zu einem Zustand maximaler Entropie verteilt. Bei einem Sytem mit vielen (in bestimmten Maße unabhängigen) Teilchen kann man das annehmen – aber in mit einer gewissen (geringen) Wahrscheinlichkeit ist sogar das nicht erfüllt.
Und die Entropie der Vakuumstrahlung können Sie schon deswegen nicht messen, weil der Faktor 4/3, den man der Vakuumstrahlung zuordnen muß, bei jedem Meßvorgang wieder verschwindet.
MfG
Lieber Herr Kinder #88,
noch eine Ergänzung : die Gibbsche Fundamentalform
dE = u*dQ + T*dS + µ*dn + p*dV + F*dr + v*dp + w*dL + gh*dm + M*da + s*dA + … .
ist das totale Differential der Zustandsfunktion E oder Zustandsgröße E. Das Differential gibt in der Tat an, auf welche Arten das System mit seiner Umgebung Energie austauschen kann. Beschreibt also zunächst eine differentielle Energieänderung. Die Zustandsgröße E hängt nun von einem Satz Zustandsvariablen ab, die das System im Zustand X charakterisieren.
Das Integral über dieses Differential gibt nun an um wie viel sich die Energie bei dem betrachteten Prozess ändert. Es ist also eine Änderung einer Zustandsgröße, die nicht mit der Zustandsgröße E selbst verwechselt werden kann und darf.
Das gleiche gilt für die differentielle Entropieänderung dS. Das Integral darüber ergibt eine Entropieänderung und darf auch nicht mit der Zustandsgröße Entropie verwechselt werden.
In meiner, sie bezeichnen das als orthodox, Definition von Wärme kann deshalb die Entropie nicht mit Wärme verwechselt werden.
Die physikalische Realität für einen Zustand ist immer die Zustandsgröße. Ein physikalischer Prozess wird beschrieben durch die Änderungen der Zustandsgrößen also dem Integral der Gibbschen Fundamentalform und damit dem Austausch von Materie und Energie mit der Umgebung.
Den Begriff „Wärme“ können sie natürlich nun in diesem Kontext wegen mir definieren wie sie wollen, sollten aber das dann immer dazu sagen.
Ich bevorzuge die orthodoxe thermodynamische Definition, die Wärme lediglich als Energietransportform zu betrachten.
Übrigens widersprechen sie sich ja auch, da sie in #88 schreiben:
„Die Zuordnung des Wortes Wärme zu der Energieform TdS schlechthin darf nicht darüber hinwegtäuschen, daß die Energieform TdS, ebenso wenig wie irgendeine andere Energieform, eine Variable eines physikalischen Systems ist.“
Denn die Entropie ist selbstverständlich ebenso wie die Temperatur eine Zustandsvariable oder die Zustandsgröße eines Systems. Entropie darf man auch nicht mit TdS verwechseln.
Das ist es ja genau, die Wärme in der schönen alten thermodynamischen Definition ist weder eine Zustandsfunktion noch eine Zustandsvariable. Die Entropie schon. Und damit wird klar, dass es gut ist Entropie und Wärme nicht synonym zu gebrauchen
Mit freundlichen Grüßen
Günter Heß
@91 Bäcker: Ihre ‚Globaltemperatur‘ ist wissenschaftlicher Unsinn, um nicht zu sagen wissenschaftlicher Mist. Alles, was Sie daran aufhängen (Klimamodelle, IPPC Berichte) ist wissenschaftlicher Mist.
Es besteht die Pflicht, die Öffentlichkeit darüber aufzuklären und finanziellen Schaden abzuwenden.
Wir werden nicht ertrinken oder verbrennen, wie IHRE geliebten Klimamodelle uns das prophezeien!
#82: Klima und Statistik (nicobaecker)
Chaos im mathematischen Sinne und statistische Aussagen sind inhaltlich NICHT identisch;
auch wenn chaotische „Ordnungsstrukturen“ ähnlich wie die Quantentheorie gelegentlich nur statistische Zustandsbeschreibungen zulässt.
Das war der tiefere Sinn des Artikels.
Man kann aber „das Klima“ nicht mit Hilfe von Statistik (reduktiv) einer chaotischen Gesetzmäßigkeit entziehen, wenn man damit irgend etwas physikalisches meint.
Insbesondere fragwürdig ist dieser Reduktionismus für den Begriff „Globalklima“ (Weltklima).
Man „rechnet“ hier sozusagen mit einer real nicht existierenden Fiktion.
Küstenklima, Kontinentalklima, Wüstenklima, Hochgebirgsklima sind jeweils Beschreibungen von real existierenden Wetterperioden, die ein Metereologe (physikalisch) „erklären“ kann (mit den bekannten Grenzen).
„Weltklima“ ist dagegen eine abstrakte „Definition“ für etwas, dessen realer Hintergrund eigentlich etwas im Dunklen bleibt um es vorsichtig auszudrücken.
Hier nun eine lineare Kausalität für einen einzigen Faktor, noch dazu ein so lächerlich winzigen (antropogener CO2-Anteil) berechnen zu wollen und entgegen aller bisher schon dazu erfolgten (negativen) Teste Prognosen für die ferne Zukunft zu erstellen,
ist schlimmer als Astrologie!
Es ist nicht nur unseriös,
sondern imho vorsätzlicher Betrug.
Im übrigen, wenn Sie trotz dieser Kritik an dem GLOBAL festhalten wollen, müssen Sie selbstverständlich gerade auch Vulkanausbrüche etc. „mitteln“, sie finden nun mal statt.
Freundliche Grüße
Herr Kinder,
wenn Sie unbedingt den physikalischen Begriff „Wärme“ als Zustandsgröße haben wollen und daher mit der Zustandsgröße Entropie äquivalent setzen, können Sie das ja für sich machen. Da dies jedoch nicht mit der Definition in der Thermodynamik übereinstimmt, müssen Sie notwendigerweise Ihre eigentümliche Konvention bei der Kommunikation in die übliche übersetzen, sonst sind masslos sinnlose Missverständnisse vorprogrammiert.
Lieber Herr Fischer, #79
in der Diskussion und auch in Edmonds Artikel geht einiges durcheinander.
Ein chaotischer Prozeß setzt die Naturgesetze nicht außer Kraft. Wenn ein System abgeschlossen ist und eine definierte Energiemenge hat, so bleibt diese konstant. Die Dynamik des Systems ist somit nur auf diejenigen Phasenraumzuständen beschränkt, die die Systemenergie haben und keine anderen. Das mögliche Chaos beschränkt sich also nur auf eine kleine Teilmenge aller Zustände des gesamten Phasenraumes.
Ein Klimazustand ist definiert als Zustand des Klimasystems, welche mit vorgegebenen Randbedingungen (Energieflüsse von und nach außen, Treibhausgasmengen, …) konform sind, d.h. es sind die Zustände des Klimasystems, die als Lösungen der physikalischen Prozesse bei diesen Randbedingungen eingenommen werden können. In der Regel sind dies mehrere mögliche Zustände, davon wird jedoch in Natur natürlich nur einer realisiert. Welcher das ist, hängt von der Vorgeschichte der Randbedingungen ab. An kritischen Punkten (Bifurkationen) ist ein Verzweigen auseinanderdriftender Klimazustände möglich.
Bei der Diskussion wird aber übersehen und bei der Klimaskeptikern wird dieses Missverständnis als vermeintliche wissenschaftsinterne Konfusion postuliert, dass ein Klimazustand KEIN bestimmter Wetterzustand ist oder eine bestimmte Sequenz von Wetterzuständen bedeutet, sondern einem ganzen Bündel von Wetterzuständen äquivalent ist! Diese Wetterzustände genügen alle den Randbedingungen!
Der Klimazustand wird durch die Statistik dieser Wetterzustände definiert. Also etwa die statistische Verteilung der Temperaturen an einem Ort. Der Klimazustand wird also nicht durch die Angabe der langfristig gemittelten Temperatur an diesem Ort definiert, sondern die statistische Verteilung der Temperaturen ist Teil der Zustandsbeschreibung des Klimas dort (dabei ist der Mittelwert nur eine von vielen Kennzahlen).
Wenn man also den Klimazustand empirisch ermitteln will, so muss man die Wetterzustände statistisch analysieren. Die Genauigkeit des Klimazustandes hängt vom Umfang der Statistik ab und diese wiederum (neben anderen Restriktionen) von der Dauer der Stationarität des Klimazustandes, was ebenfalls statistisch zu ermitteln ist.
Dieses Prinzip wendet man sowohl zur Klimabeschreibung der Vergangenheit an, wie auch für die Szenarien der Zukunft. Klimamodelle liefern als output eine Sequenz von Wetterzuständen, die viel gröber als heutige Wettervorhersagen sind und deren Sequenz wegen der fehlenden Anfangsbedingungen nicht mit der eingetroffenen Sequenz übereinstimmen, aber zumindest das empirische Klima näherungsweise wiedergeben.
Nun kann man also dasselbe Klimamodell mehrmals z.B. am 1.1.1900 starten lassen und bis 2100 durchlaufen lassen. Dabei werden bis heute die gemessenen resp. rekonstruierten zeitlichen Verläufe der Randbedingungen einsetzten und für die Zukunft Szenarien davon konstant gehalten. Variiert man die Anfangswerte am Startpunkt, so driften die Wettersequenzen der modellierten Ensemble mit der Zeit auseinander, einmal regnet es am 26.6.2011 über Berlin, einmal nicht.
Die Verifikation des Klimamodells kann nun so passieren, dass man das Klima jedes Ensembles entsprechend wie bei der empirischen Klimaermittlung aus den Ensemble-Wetterzuständen ermittelt (Zeitstatistik) oder auch die Statistik über die Ensembles macht (Scharstatistik). Die Abweichung der Zeitstatistiken der Ensembles gegenüber der empirischen Messdaten ist ein Maß für die Güte des Klimamodells. Wenn die Zeitstatistiken des Ensembles untereinander weniger abweichen als von den empirischen Daten, so hat das Modell einen systematischen Fehler. Wenn nicht, so beschreibt das Modell das empirische Klima über den Verifikationszeitraum hinreichend gut. In diesem Fall lohnt es sich die Scharstatistik des Modells zur genaueren Erfassung des Klimas heranzuziehen, denn empirisch liegt ja nur eine Realisation mit begrenzter Signifikanz vor.
Die Klimaszenarien und –modelle basieren also IMMER auf Wettersequenzen jenseits der deterministischen Vorhersagbarkeit des Wettermodells!
In Edmonds Artikel wird leider (absichtlich oder aus Unfähigkeit) nicht sauber differenziert:
Die Abbildung, die er aus einem random walk zufallsverteilter Größen generiert hat und beschrieben ist mit:
„Wenn ich nun ohne Beachtung der Skalen erzählt hätte, das wäre der Kurs im vergangenen Jahr für eine bestimmte Aktie, oder der jährliche Meerestemperaturverlauf gewesen, hätten Sie mir vermutlich geglaubt. Was ich damit sagen will: Das Chaos selbst kann ein System völlig antreiben und Zustände erzeugen, die so aussehen, als ob das System von einem äußeren Antrieb gesteuert wäre. Wenn sich ein System so verhält, wie in diesem Beispiel, kann es wegen einer äußeren Kraft sein, oder ganz einfach nur wegen des Chaos.“
suggeriert Ähnlichkeit mit der globalen Mitteltemperatur, und Edmonds will suggerieren, dass man bei den Ergebnissen von Klimamodellen nur die Spitzenwerte sieht. Das ist so einfach nicht! Es werden nämlich von den komplexen Klimamodellen nur wenige Ensembles gerechnet (wegen des Rechenaufwandes), wenn Klimaoutputs verglichen werden, so sieht man in der Regel die Zeitmittel der Modelle, Ensemble-Spitzenwerte eines Modells existieren gar nicht, weil man für dasselbe Modell nur ein 1 bis 3 Ensembles hat. Wenn Edmonds suggerieren will, dass auch Modellergebnisse existieren, die einen grotesk anderen Verlauf des globalen Temperaturmittels zeigen, dies aber geheim gehalten wird, so ist dies eine Behauptung, die er mal klar formulieren soll und beweisen soll! Ein grotesk anderer Verlauf würde bedeuten, dass das Modell unbrauchbar ist, denn es ist leicht nachrechenbar, dass ein anderer Temperaturverlauf einen Verlauf der Energieflüsse benötigte, deren physikalische Gründe unerklärbar wären und daher auch nicht im Modell existieren! Ein grob anderer Temperaturverlauf wäre mit den Randbedingungen nicht konform – soviel Chaos ist nicht drin!
Lieber Herr Kinder #88,
sie schreiben:
„Mit Wärme (= Entropie) kann man Energie übertragen.“
Und gebrauchen damit in der Tat Entropie und Wärme synonym.
Das ist falsch.
Entropie ist eine Zustandsfunktion und Wärme nicht. Die Entropie hat ein totales Differential, die Wärme nicht.
Mit jedem Wärmetransport ist allerdings ein Entropietransport verknüpft.
Herr Ebel hatte sie leider doch richtig verstanden.
Mit freundlichen Grüßen
Günter Heß
82: nicobaecker sagt:
„Herr Schneider,
die Definition des Klimas in Wiki findet sich hier und deckt sich mit meinen Angaben, die ich vor kurzem bei Eike gemacht habe, suchen sie im archiv
http://de.wikipedia.org/wiki/Klima
Der Klimazustand ergibt sich aus der Statistik der Wetterzustaende. Herr Schneider, wenn sie alles als Bloedsinn bezeichen, was Sie nicht verstehen, leben Sie in einer reichlich beschraenken Gedankenwelt.“
Hallo Herr Baecker
Es ist wirklich lästig mit Leuten wie Ihnen. Sie leiden grundsätzlich an maßloser Selbst-überschätzung, glauben grundsätzlich selber alles zu verstehen und halten grundsätzlich alle andern Leute für dämlich.
Und lesen können Leute wie Sie auch nie, was ist das, irgendeine Art Reflex gleich immer Leute beleidigen zu wollen die Leuten wie Ihnen nicht zustimmen, schon dann wenn man das was diese sagen gar nicht richtig gelesen hat?
Damit werden Sie wohl nicht weit kommen und beeindrucken werden Sie damit niemanden.
Wenn Sie schon selber diesen link angeben, den ich ja selber benannt hatte, dann suchen Sie sich nicht irgend eine Zeile am Ende raus, sondern lesen Sie die Definition gleich am Anfang. Genau diese Definition am Anfang gibt real wieder worüber wir reden.
„Das Klima steht als Begriff für die Gesamtheit aller meteorologischen Vorgänge, die für den durchschnittlichen Zustand der Erdatmosphäre an einem Ort verantwortlich sind. Oder anders ausgedrückt: Klima ist die Gesamtheit aller an einem Ort möglichen Wetterzustände, einschließlich ihrer typischen Aufeinanderfolge sowie ihrer tages- und jahreszeitlichen Schwankungen. Das Klima wird dabei jedoch nicht nur von Prozessen innerhalb der Atmosphäre, sondern vielmehr durch das Wechselspiel aller Sphären der Erde (Kontinente, Meere, Atmosphäre) sowie der Sonnenaktivität geprägt. Es umfasst zudem unterschiedlichste Größenordnungen, wobei vor allem die zeitliche und räumliche Dimension des Klimabegriffs von entscheidender Bedeutung für dessen Verständnis ist.“
So, was gibt es wohl daran noch zu ergänzen. Sehen Sie sich diesen Satz genau an:
„Das Klima wird dabei jedoch nicht nur von Prozessen innerhalb der Atmosphäre, sondern vielmehr durch das Wechselspiel aller Sphären der Erde (Kontinente, Meere, Atmosphäre) sowie der Sonnenaktivität geprägt.“
Er beinhaltet alles das, was ich Ihnen gesagt habe. Und von Statistik steht da gar nichts.
Und ich frage Sie noch mal, nachdem sie mir beim ersten Mal schon nicht geantwortet haben:
Was glauben Sie, warum alle Klimaforscher, die mit der Erstellung von Klima- Simulations- Software befasst sind, sich die Mühe machen alle möglichen physikalischen Vorgänge die ich genannt habe, bis hin zum Einfluss der Sonne zu integrieren, wenn die Sache so einfach wäre wie Sie tun, dass alles nur eine Frage der Statistik ist?
Die sind nach Ihrem Verständnis alle blöd und haben alles nicht verstanden, hätten mal lieber Herrn Nico Baecker fragen sollen.
Ihre Statistik Herr Baecker können Sie sich an den Hut stecken, dafür gibt es nur das alte Wort von Churchill „ich glaube nur der Statistik die ich selber gefälscht habe.“
Bei Klimaprognosen spielen wir hier nicht mit Förmchen im Statistik- Sandkasten, sondern wir versuchen Klima in der Realität zu verstehen, eine Realität, von der Leute wie Sie glauben, dass Sie sie verstanden haben, per Statistik.
Das ist einfach nur lachhaft.
Anstatt sich an der Hauptdefinition des Begriffes Klima zu orientieren, haben Sie sich einen Teilaspekt der Ihnen genehm ist rausgepickt, die Statistik.
Die Statistik hat dabei aber nur eine Aufgabe, man versucht für einen Ort eine Glättung der Wetterspitzen, um kurzfristige Schwankungen des Wetters zu filtern und charakteristische Werte für verschiedene meteorologische Größen zu erhalten, welche in ihrer Gesamtheit wiederum das Klima eines Ortes beschreiben.
Man versucht Langzeittrends zu ermitteln.
Je wechselhaft aber das Wetter ist, je größer diese Schwankungen sind, desto weniger repräsentativ ist eine statistische Auswertung der Daten eines Referenzzeitraumes.
Selbst Langzeitauswertungen verlieren durch diese Schwankungen teilweise ihren Aussagegehalt.
Betrachtet man das Klima eines Ortes mit einem Referenzzeitraum von 1000 Jahren, so hat man sicher alle Extremereignisse gefiltert, jedoch gilt dies bei einem solch langen Zeitraum auch für alle kurzfristigen Schwankungen. Selbst wesentliche Trends, wie der der Kleinen Eiszeit, könnten durch die Wahl eines solchen Zeitraums schlicht übersehen werden.
Das ist wohlgemerkt alles eine rückwärtslaufende Statistik.
Wir reden aber über Klimaprognosen in der Zukunft. Da können Sie mit Ihrer Statistik gar nichts werden. Erst recht nicht, wenn ein vorher nicht dagewesener Faktor eintritt.
Dabei rede ich nicht mal von Vulkanen oder Meteoriten, die kommen noch zusätzlich dazu.
Ökofanatiker behaupten doch dauernd, der Anstieg des CO2 würde das Klima verändern.
Dann erzählen Sie mir doch mal bitte, wo die Auswirkungen des CO2 in Ihrer Statistik auftaucht, wenn der Anstieg bisher angeblich nie da war?
Herr Baecker, Sie haben sich mit Ihrer Statistik gerade selber ins Bein geschossen.
Sie machen sich die Welt zu einfach, Sie haben Klima nicht verstanden, das ist keine Schande, niemand weiß wie Klima funktioniert, aber anstatt das zuzugeben, wollen Sie aus Statistikdaten der Vergangenheit (und die sind auch schon mehr als begrenzt) das fehlende Wissen wie Klima funktioniert durch Statistik ersetzen.
Ein Gärtner der Kräuter anbaut und vermarktet ist deshalb noch kein Koch Herr Baecker.
Werter Herr Heß (#83)
„Die Entropie ist eben vor allem eine Zustandsfunktion eines Systems“
Warum wird ausgerechnet bei der Entropie betont, sie sei eine Funktion? Die Entropie ist zunächst eine physikalische Größe. Zur Funktion wird sie erst, wenn man sie in Abhängigkeit von anderen Größen darstellt. Je nachdem, welche anderen Größen man wählt, ist der funktionale Zusammenhang natürlich ein anderer.
Und warum wird betont, sie sei eine Zustandsfunktion oder Zustandsgröße? Alle extensiven physikalischen Größen sind Zustandsgrößen (und noch viele andere mehr), aber diese Tatsache ist so selbstverständlich, daß man sie normalerweise nicht erwähnt.
Tatsächlich ist die Entropie aber eine der am leichtesten zu messenden Größen überhaupt. Man kann Entropiewerte mit recht guter Genauigkeit mit Hilfe von Geräten bestimmen, die man in jeder Küche findet.
Zur Frage, was Wärme (Entropie) eigentlich ist oder wie man sie auffassen sollte, gibt es ein buntes Spektrum von Lehrmeinungen. Diese Vielfalt der Auffassungen über einen zentralen Begriff erinnert mehr an den Meinungspluralismus in den Geisteswissenschaften als an den sonst vorherrschenden Meinungskonformismus in den Naturwissenschaften.
Beispiele der Meinungsvielfalt:
+ Wärme ist die durch thermische Kontakte einem System zugeführte Energie.
(orthodox: Unter Thermodynamikern die verbreiteteste Auffassung)
+ Wärme ist die in der Molekularbewegung steckende Energie.
(mechanistisch: Die herrschende Meinung in einführenden Büchern)
+ Wärme ist ungeordnete Bewegung.
(Verallgemeinerung der zu engen mechanistischen Auffassung)
+ Wärme ist die zur Entropiezufuhr oder Entropieerzeugung erforderliche Energie.
(Erweiterung der restrikten orthodoxen Auffassung)
Mal ganz einfach ausgedrückt:
+ Die Temperatur charakterisiert den Zustand des „Warmseins“ eines Körpers, unabhängig von dessen Größe, Masse, Material, etc.
+ Die Wärme (= Entropie) ist etwas, das in dem Körper enthalten ist, abhängig von dessen Größe, Masse, Material, Temperatur, …
+ Die Energie ist etwas, das in allem enthalten ist. Alles ist Energie und für alles braucht man Energie. Mit Wärme (= Entropie) kann man Energie übertragen.
+ Es kostet Energie, die Entropie eines Systems zu verringern.
Physikalisch interessant ist weniger der Energieinhalt, sondern es sind vielmehr die Energieströme, weil die Energieströme Vorgänge und Prozesse charakterisieren.
Energie strömt nie allein, sondern braucht einen Energieträger. Energieströmung ohne Energieträger gibt es nicht. Diese Energieträger sind die bekannten physikalische Größen: Impuls p, Drehimpuls L, elektrische Ladung Q, Stoffmenge n, … und Entropie S. Der Zusammenhang zwischen dem Energiestrom und dem Energieträgerstrom ist sehr einfach, nämlich proportional.
Jede Energieänderung (Energieströmung, Energiefluss, Energietransport) dE eines Systems ist verbunden mit der Änderung, Strömung, dem Fluss, Transport, … mindestens einer anderen mengenartigen Größe dX, und dE lässt sich schreiben als Summe: dE = u*dQ + T*dS + µ*dn + p*dV + F*dr + v*dp + w*dL + gh*dm + M*da + s*dA + … . Diese Form nennt man Gibbssche Fundamentalform.
Die Zuordnung des Wortes Wärme zu der Energieform TdS schlechthin darf nicht darüber hinwegtäuschen, daß die Energieform TdS, ebenso wenig wie irgendeine andere Energieform, eine Variable eines physikalischen Systems ist. Eine Energieform ist ja nur Zustandsänderungen zugeordnet, aber nicht den Zuständen des Systems selbst. Anstatt also von Wärmeaustausch/-erzeugung oder Entwärmung eines Systems zu sprechen, ist es unmißverständlicher und an das Begriffsschema von physikalischen Größen oder Variablen besser angepaßt, von Entropieänderungen zu sprechen, wobei zusätzlich die Temperatur anzugeben ist, bei der die Entropieänderung erfolgt.
Um eine physikalische Größe zu definieren, muß eine Skala festgelegt werden, indem eine Einheit und eine Vorschrift für die Konstruktion von Vielfachen der Einheit festgelegt wird. Die Einheit der Energie 1 J ist als abgeleitete Größe über die SI-Basiseinheiten 1J = 1 kg*m^2/s^2 festgelegt. Die Vielfachen der Energie und Entropie ergeben sich trivialerweise aus der Mengenartigkeit der beiden Größen. Die Vielfachen der Temperatur und die Einheit der Entropie sind über die Gleichung P=T*I(s) oder dE=T*dS mit [S]=1 J/K festgelegt. Es ist diejenige Entropiemenge, mit der man bei Normaldruck 0,893 cm^3 Eis schmilzt. Der „krumme“ Wert bei der Festlegung der Temperatureinheit ergab sich aus der Forderung, die Temperaturdifferenz 1 K mit der früher festgelegten Celsius-Skala in Übereinstimmung zu bringen.
Mfg.
W. Kinder
#86: N. Koksch
„Chaostheorie ist Bestandteil der Mathematik. Mathematik ist keine Naturwissenschaft“
Falsch!
Chaostheorie ist spätestens seit den 70ger Jahren ein anerkannter Zweig der Naturwissenschaft. Anwendungsbeispiele habe ich genannt!
Sie ist insbesondere den AGW´lern ein Dorn im Auge!
Sie argumentieren also wie ein solcher.
Der Kern der Theorie ist die Irreversibilität und die PRINZIPIELLE Unberechenbarkeit von chaotischen Prozessen, TROTZ bekannter streng naturgesetzlicher Abhängigkeit.
Es ist nicht meine Theorie! Und nicht nur für mich ist sie die logische Begründung eines Sytemindeterminismus und positiv ausgedrückt die Selbstorganisationspotenz für prinzipiell neues (Emergenz).
Machen Sie sich damit vertraut!
Freundlichen Gruß