Es ist wichtig, die Isolation der Paläoklima-Gemeinschaft zu unterstreichen; selbst wenn sie sich stark auf statistische Methoden stützen, die sie anscheinend nicht mit der Gemeinschaft der Statistiker abgesprochen haben.
Offensichtlich wussten sie, dass ihr Gebrauch und Missbrauch von Statistik und statistischen Methoden niemals untersucht werden würde. Das galt für den „Hockeyschläger“, einem Beispiel von falscher Anwendung und für die Erzeugung ‚einheitlicher‘ statistischer Methoden, um das Ergebnis vorweg zu bestimmen. Unglücklicherweise ist diese Gefahr in der Statistik inhärent. Ein Statistik-Professor sagte mir: je ausgeklügelter eine statistische Methode ist, umso schwächer sind die Daten. Alles jenseits grundlegender statistischer Methoden ‚unterminierte‘ die Daten und entfernte sich immer weiter von der Realität und einer vernünftigen Analyse. In der Klimatologie ist dies wegen unzureichender Daten unvermeidlich. Im Bericht des US National Research Council vom 3. Februar 1999 heißt es:
„Defizite hinsichtlich Genauigkeit, Qualität und Kontinuität der Aufzeichnungen begrenzen ernstlich das Vertrauen in die Forschungsergebnisse“.
Methods in Climatology von Victor Conrad ist ein klassisches Lehrbuch, das die meisten der grundlegenden Dinge in der Klimaanalyse anspricht. Seine Stärke liegt in der Erkenntnis, dass die Menge und Qualität der Daten kritisch ist. Dieses Thema war für Hubert Lamb zentral, als er die Climate Research Unit (CRU) ins Leben gerufen hatte. Meiner Ansicht nach hat sich die Statistik, so wie sie hinsichtlich des Klimas angewendet wird, seitdem kaum weiterentwickelt. Es stimmt zwar, dass wir inzwischen über andere Methoden verfügen wie die Spektralanalyse, aber alle diese Methoden sind bedeutungslos, wenn man nicht akzeptiert, dass es Zyklen gibt oder dass man Aufzeichnungen hinreichender Qualität und zeitlicher Länge braucht.
Ironischerweise entfernen einige Methoden Daten, wie z. B. gleitende Mittel. Eisbohrkern-Aufzeichnungen sind ein gutes Beispiel. Die antarktischen Aufzeichnungen aus Eisbohrkernen, zum ersten Mal im Jahre 1990 gezeigt, illustrieren die Mahnung des Statistikers William Briggs:
Jetzt werde ich Ihnen die große Wahrheit über Analysen von Zeitreihen verkünden. Sind Sie bereit? Solange die Daten nicht mit Fehlern gemessen werden, darf man die Zeitreihe niemals, jemals, unter keinen Umständen und auf keinen Fall GLÄTTEN! Und wenn man dies aus irgendwelchen bizarren Gründen doch tut, werden Sie diese geglättete Reihe absolut NIE als Input für andere Analysen benutzen! Werden die Daten mit Fehlern gemessen, kann man versuchen, diese zu modellieren (das heißt zu glätten), und zwar in einem Versuch, den Messfehler abzuschätzen, aber selbst in diesen seltenen Fällen muss man eine von außen kommende Abschätzung jenes Fehlers haben, das heißt eine, die nicht Ihre gegenwärtigen Daten zur Grundlage hat (Fettdruck von ihm).
Die Aufzeichnungen der antarktischen Eisbohrkerne hat man mit einer über 70 Jahre gehenden Glättung versehen. Dies eliminiert einen großen Teil dessen, was Briggs „reale Daten“ nennt, im Gegensatz zu „fiktiven Daten“, die die Glättung hervorbringt. Die Glättung verkleinert eine wesentliche Komponente grundlegender Statistik, nämlich die Standardabweichung der Rohdaten. Dies ist teilweise der Grund, warum diese in den Klimastudien so wenig Aufmerksamkeit erfahren hat, obwohl sie ein kritischer Faktor hinsichtlich des Einflusses von Wetter und Klima auf Flora und Fauna ist. Die Konzentration auf Mittelwerte und Trends war ebenfalls dafür verantwortlich. Noch wichtiger aus wissenschaftlicher Perspektive ist deren Wichtigkeit zur Berechnung von Mechanismen.
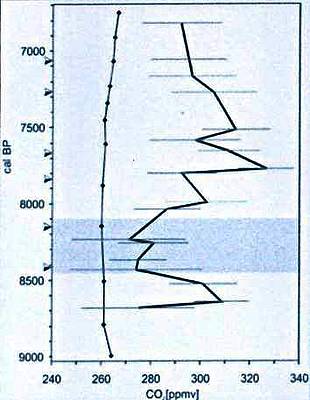
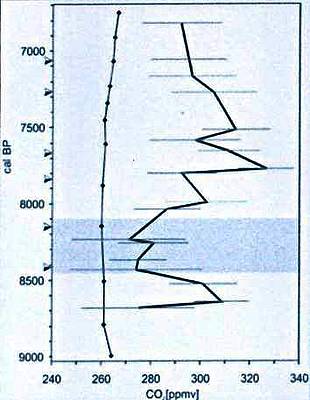
Abbildung (Beschreibung teils aus dem Original): Rekonstruierte CO2-Konzentrationen für das Zeitintervall zwischen etwa 8700 und 6800 Kalenderjahren vor heute, basierend auf CO2, das aus Luftbläschen des antarktischen Eises an der Stelle Taylor Dome extrahiert worden ist (linke Kurve; ref.2; Rohdaten erhältlich bei www.ngdc.noaa.gov/paleo/taylor/taylor.html) und SI-Daten für fossile B. pendula und B. pubescens [?] aus dem Lille Gribso-See in Dänemark. Die Pfeile kennzeichnen accelerator mass spectrometry 14C–Chronologien, die für zeitweilige Kontrollen verwendet wurden. Das schattierte Zeitintervall markiert das Abkühlungsereignis von 8200 Jahren vor heute.
Quelle: Proc. Natl. Acad. Sci. USA 2002 September 17: 99 (19) 12011 -12014.
Die Abbildung zeigt eine Bestimmung des atmosphärischen CO2-Gehaltes in einem Zeitraum von 2000 Jahren, wobei geglättete Daten aus einem Eisbohrkern (links) und aus Stomata (rechts) verglichen werden. Unabhängig von der Wirksamkeit jeder Methode der Datengewinnung ist es nicht schwierig zu bestimmen, welcher Plot wahrscheinlich die meisten Informationen über die Mechanismen vermittelt. Wo ist das Abkühlungsereignis vor 8200 Jahren in der Kurve des Eisbohrkerns?
Zu Beginn des 20. Jahrhunderts wandte man Statistik auf die Gesellschaft an. Universitäten, ursprünglich geteilt in Natur- und Geisteswissenschaften, sahen eine neue und ultimativ größere Disziplin heraufdämmern, die Sozialwissenschaften. Viele im Bereich der Naturwissenschaften sehen die Sozialwissenschaft als einen Widerspruch in sich und nicht als ‚wirkliche‘ Wissenschaft. Um die Bezeichnung zu rechtfertigen, begann man in den Sozialwissenschaften, deren Forschungen statistisch zu untermauern. Ein Buch mit dem Titel „Statistical Packages for the Social Sciences” (SPSS) erschien erstmals im Jahre 1970 und wurde zum Handbuch für Studenten und Forscher. Man gebe ein paar Zahlen ein, und das Programm liefert Ergebnisse. Die Brauchbarkeit der Daten, wie der Unterschied zwischen kontinuierlichen und diskreten Zahlen, sowie die Methode waren wenig bekannt oder sind ignoriert worden, obwohl die Ergebnisse beeinflusst worden sind.
Die Meisten kennen den Kommentar von Disraeli: Es gibt drei Arten Lügen: Lügen, verdammte Lügen und Statistik“, aber nur Wenige verstehen, wie sehr die Anwendung von Statistik ihr Leben beeinflusst. Jenseits der ungenauen Anwendung von Statistiken liegt das Entfernen von allem jenseits der Standardabweichung, was die Dynamik der Gesellschaft beseitigt. Macdonald verkörpert die Anwendung von Statistiken – sie haben die Mittelmäßigkeit perfektioniert. Wir fühlen, wenn alles zu jedem passt, aber nie genau zu jedem einzelnen passt.
Klimastatistik
Klima ist ein Mittel des Wetters über einen bestimmten Zeitraum oder einem Gebiet, und bis zu den sechziger Jahren waren Mittelwerte effektiv die einzige entwickelte Statistik. Antike Griechen benutzten mittlere Bedingungen, um drei globale Klimaregionen zu bestimmen: die heißen, gemäßigten und kalten Zonen, erzeugt vom Winkel zum Sonnenstand. Klimaforschung enthält die Berechnung und Veröffentlichung mittlerer Bedingungen an individuellen Stationen oder Gebieten. Nur wenige verstehen, wie bedeutungslos eine Messung ist, obwohl schon Robert Heinlein schrieb: „Klima ist das, was man erwartet, und Wetter ist das, was man bekommt“. Auch Mark Twain war sich dessen bewusst, bemerkte er doch: „Klima ist immer, Wetter nur ein paar Tage“. Ein Landwirt befragte mich hinsichtlich der Wahrscheinlichkeit eines normalen Sommers. Er ärgerte sich über die Antwort „nahe Null“, weil er nicht verstanden hat, dass ‚Mittel‘ Statistik ist. Eine informativere Frage ist, ob es kälter oder wärmer als normal sein wird, aber dazu braucht man Kenntnis über zwei andere wesentliche statistische Parameter, nämlich Variation und Trend.
Nach dem Zweiten Weltkrieg kamen Planungen und Sozialforschung auf, als die Nachkriegs-Gesellschaften Entwicklungen einer einfachen Trendanalyse ausgelöst hatten. Man nahm an, dass ein darin erscheinender Trend immer so weiterlaufen würde. Die Mentalität hatte Bestand trotz offensichtlicher Auf- und Abschwünge; hinsichtlich des Klimas scheint es Teil der Zurückweisung von Zyklen zu sein.
Studien zu Klimatrends begannen im Wesentlichen in den siebziger Jahren mit der Vorhersage einer kommenden Mini-Eiszeit, hatten doch die Temperaturen bis dahin seit 1940 abgenommen. Als Mitte der achtziger Jahre die Temperaturen wieder stiegen, hieß es, dass sich dieser Trend ohne Abschwächung fortsetzen würde. Politische User des Klimas übernahmen etwas, das ich den Trend-Waggon nenne. Das IPCC machte den Trend unabwendbar mit der Aussage, dass das menschliche CO2 dafür der Grund war und dass CO2 immer weiter zunehmen werde, solange die industrielle Revolution noch andauert. Wie auch alle Trends zuvor hatte auch dieser Trend keinen Bestand, zeigte sich doch nach 1998 bei den Temperaturen ein Abwärtstrend.
Für das Leben und die Wirtschaft ist die Variabilität von Jahr zu Jahr wichtig. Landwirte wissen, dass die Arbeit des nächsten Jahres nicht auf der Grundlage des Wetters im vorigen Jahr geplant werden kann, aber eine reduzierte Variabilität reduziert das Risiko merklich. Die jüngste Änderung der Variabilität ist normal und durch bekannte Mechanismen erklärt, wird aber von denjenigen mit einer politischen Agenda als anomal hingestellt.
John Holdren, der Wissenschafts-Zar von Obama, nutzte die Autorität des Weißen Hauses, um die zunehmende Variation des Wetters und eines Mechanismus‘ auszuschlachten, der den meisten Wissenschaftlern, geschweige denn der Öffentlichkeit unbekannt ist, nämlich den Polarwirbel [the circumpolar vortex]. Er erzeugte eine ungenaue Propaganda-Veröffentlichung über den Polarwirbel, um zu implizieren, dass dieser etwas völlig Neues und unnatürliches sei und daher den Menschen zuzuordnen ist. Zwei der drei von den antiken Griechen festgelegten Klimazonen sind sehr stabil, nämlich die Tropen und die Polargebiete. Die gemäßigte Zone weist infolge jahreszeitlicher Veränderungen die größte kurzfristige Variabilität auf. Es gibt dort aber auch eine längerfristige Variabilität, weil der Polarwirbel zyklisch zonal und meridional hin und her schwingt. Letzteres führt zu einer zunehmenden Variation der Wetter-Statistik, wie es auch jüngst der Fall war.
Das Scheitern der IPCC-Studien und –Vorhersagen war unvermeidlich, weil ihm Daten fehlen und Daten fabriziert wurden, weil Kenntnisse über Mechanismen fehlen und bekannte Mechanismen ausgeschlossen worden sind. Reduktion oder Entfernung der Standardabweichung führte zu Informationsverlusten und einer weiteren Verzerrung der natürlichen Wetter- und Klimavariabilität, die beide weiterhin innerhalb historischer und natürlicher Normen ablaufen.
Link: http://wattsupwiththat.com/2014/06/15/standard-deviation-the-overlooked-but-essential-climate-statistic/
Übersetzt von Chris Frey EIKE
Standardabweichung, das übersehene, aber essentielle Klima-Statistikum














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"@#11:
„Mit dergleichen elementaren Statistik ist man immer noch an einem völlig unzulänglichen Anfang. Das Wetter und die Strahlen-Verteilung müssten mit beliebig komplizierten Methoden multivariater Statistik beschrieben werden.“
– wie Recht Sie haben, und: m.E. und m.W:…
– Da reichen ‚komplizierte multivariate (leider ‚linear-basierte‘) Methoden‘ leider nicht, da es sich um dynamisch-selbstverändernde System handelt – also…
– ‚NLS (nicht-lineare-Systeme)‘ sind hier gefragt – was m.E. allerdings z.B. hypothesengeleitetes Forschen voraussetzt.
LG
Mit dergleichen elementaren Statistik ist man immer noch an einem völlig unzulänglichen Anfang. Das Wetter und die Strahlen-Verteilung müssten mit beliebig komplizierten Methoden multivariater Statistik beschrieben werden.
Vielen Dank an #9!
Und, #8: das, was Sie da benennen, macht doch die statistischen Signifikanzeinschätzungen noch bis zu um den Faktor 10 schlimmer, wenn Sie bitte berücksichtigen, worauf ich mich bei meinem Kommentar bezogen hatte, nämlich die Grundlagen der ‚Signifikanztabellen‘.
Herzliche Grüße!
@ #8
„Es gibt auch keine „Klimastationen“, Klima wird aus der Statistik des Wetters berechnet.“
Hader weiß es natürlich ganz genau, denn climate stations gibt es nicht und der DWD verwendet auch keine Stationskennungen mit KL für Klima.
Er kennt auch nicht den Unterschied zwischen Wirtschaft und Unternehmen, obwohl eine Wirtschaft ein Unternehmen zum Schnaps und Bierkonsum ist, landläufig Kneipe genannt.
Wirtschaftspolitik, drum bin ich hier dumdiedeldum …
#7: „Ich bin nun zwar kein ‚Klima’forscher im engeren Sinne, dennoch habe ich via Recherche herausfinden dürfen, dass es doch ‚etwas‘ mehr als 500 „Klima/Wetter“-Messtationen weltweit gibt.“
Sehr geehrter Steffen Boettcher, da haben Sie aber eine schlechte Informationsquelle erwischt. Allein der DWD nutzt über 100 offizielle Wetterstationen in D. GISS greift auf die Daten von über 5.000 Wetterstationen weltweit zurück. Es gibt auch keine „Klimastationen“, Klima wird aus der Statistik des Wetters berechnet.
@#6, Martin Landvoigt:
Vielen Dank für diesen Einwurf!
Dazu möchte ich ergänzen:
Die gängige ‚Statistik‘ basiert ja nicht nur auf der Normalverteilungsannahme (und somit im Rechenverfahren auf ‚Varianz‘ in Abweichung eines postulierten ‚Mittelwertes‘), sondern die dazu verwendeten „Signifikanztabellen“ zeigen leider bereits ab spätestens N=500 (F-Tabelle, T-Tabelle etc.) stets eine ‚unendliche Relevanz‘, auch geringster ‚Korrelationen (deren EinflussRichtung ja zudem undefiniert ist)‘ auf.
Bei z.B. Erhebungen an 250.000 Probanden (vgl. ‚Pisa‘) ergibt sich z.B. das Problem, die ‚irrelevanten‘ von den ‚relevanten‘ Signifikanzen -wissenschaftlich begründet- auszusortieren.
Ich bin nun zwar kein ‚Klima’forscher im engeren Sinne, dennoch habe ich via Recherche herausfinden dürfen, dass es doch ‚etwas‘ mehr als 500 „Klima/Wetter“-Messtationen weltweit gibt.
Und somit müsste sich, m.E., z.B. ein Herr Rahmstorf -inhaltlich- fragen lassen, warum, wieso und wie genau er sein -theoretisches- (und hoffentlich hypothesengeleitetes) Modell begründen wollte.
Herzliche Grüße!
Auch mein Lob für den Artikel.
Zwei Anmerkungen:
1. In den Klimarechnungen werden of Durchschnitte, teilweise gewichtet, gebildet. So z.B. in der Globalen Durchschnittstemperatur. Aus dieser wird dann eine virtuelle Strahlungstemperatur gebildet. etc.
Der Witz ist, dass man das gar nicht machen kann. Denn die Strahlungstemperatur eines Schwarzkörpers kann man nur dann sinnvoll bestimmen, wenn diese überall konstant ist. Ist die Temperaturverteilung inhomogen, muss über die gesamte Oberfläche integriert werden. Haben wir dann auch noch zeitliche Schwankungen, muss auch das Integriert werden.
Dies haben Gerlich & Tscheuschner und Kramm gezeigt.
Zu meinen, dass das ein arithmetisches Mittel eben eine Repräsentanz und Statistik sei, ist da grober Unfug. Offensichtlich tun sich auch vermeintliche Klimaexperten schwer, das zu verstehen.
2. Die analytische Statistik kennt vor allem Testverfahren für die Signifikanz von Hypothesen. Diese beziehen sich auf Stichprobengrößen und Varianzen. Viele Studienabsolventen haben aber mit empirischen Arbeiten da ihr Problem: Meist reichen die Erhebungen nicht aus, um signifikanz nachzuweisen. Im Besonderen ist bei großen Rauschanteilen dies nahezu ausgeschlossen.
Das gilt auch für einen Großteil der Klimaforschung. Ihr Beispiel an den Eisbohrkernen ist kein Problem der Statistik, sondern der schlicht fehlerhaften Nutzung derselben.
Solide Argumentationen müssten schlicht auf Veröffentlichungen verzichten, wenn keine Signifikanz einer Aussage nachgewiesen wäre. Dann aber wäre die Literatur zum Thema wohl stark dezimiert.
Nachtrag zu #4
Übrigends wenn wir von einen Kernfaktor/Parameter beim Klima sprechen, dann ist der Faktor/Parameter „ZEIT“ ein ganz wesentlicher und zentraler Faktor/Parameter.
Und nur die Sonne kann diesen Faktor konstant vom Anfang des Klima bis zum Ende abdecken.
Und genau aus diesem Grund wird sich alles andere beim Thema Klima der Sonnenaktivität unter ordnen.
@steffen boettcher #3
Und der beliebteste Parameter in der Wissenschaft ist die „ZEIT“….Alles ist Relativ. Wie schon Einstein es formulierte.
Mit dem Parameter (Faktor) Zeit wird alles relativ, weil sich Alles mit dem Faktor Zeit verändert.
@#2. M.Hofmann:
Danke für Ihren Beitrag,
m.E.: wenn ich maximal möglich ‚Parameter‘ ausschließe, dann erwarte ich ‚im Schnitt‘ -keinerlei- signifikante Ergebnisse, was im Wissenschaftsbetrieb natürlich äußerst ungern gesehen ist…
@M.L. @#1-comment:
Vielen Dank für Ihre Stellungnahme!
M.E.: Man könnte m.W. aber auch die in den Daten enthaltenen Ergebnisse (mal) herausfiltern (wollen) – (‚die Elite‘ tut dies m.W. auch bereits – vgl. http://tinyurl.com/4sktut )
Danke auch für den mir bislang unbekannten Begriff der „‚educateted‘ speculations“
Ich würde mich darüberhinaus freuen, ein paar Querverweise lesen zu dürfen, wo „haben wir schon vor ein paar Jahren schon oft geschrieben“ nachlesbar bzw. für die Allgemeinheit zitierbar verfügbar wäre.
Herzliche Grüße!
Bei der Statistik ist es wie bei der Messung…beide sind von Parameter beeinflussbar.
Eine Statistik wie auch eine Messung kann das gewünschte Ergebnis liefern, wenn die Parameter entsprechend auf das gewünschte Ergebnis abgestimmt/eingestellt sind.
Vielen Dank für diesen Artikel!
Übrigens: noch 1989 konnten wir hier in HH (bei der IEA) nachweisen, dass z.B. faktorenanalytische Algorithmen in „SPSS“ softwareseitig falsch implementiert waren… (grumpf! (Nachweise damals via händischer Programmierung und Einsatz von SAS))
Ebf.: Man nehme eine auf ‚Varianz‘ basierende statistische Prozedur, wie z.B. die Faktoren- oder Cluster-Analyse, und erkenne, dass im programmatorischen Verfahren bei z.B. nahe 100%-igen Treffern dort rein rechnerisch immer ‚abgebrochen‘ wird, weil eben keine ‚Varianz‘ vorhanden sei… (wenn aber stets aus einem Ei ein Vogel entspringt, gibt es eben keine ‚Varianz‘)…
M.W. gab es da noch andere statistische Verfahren (weswegen ja z.B. interessierte Mathematiker und Physiker bei den empirischen Sozialwissenschaftlern im Nebenfach studier(t)en…) – also andere Verfahren, die eben _nicht auf ‚Varianz‘ basieren (und leider sogar bei unsereiner bereits in ‚Statistik 1‘ nur kurz erwähnt und beiseitegeschoben werden…
(man suche doch mal selbst 😉 )
Herzlichen Dank und herzliche Grüße!