
Jedes Mal, wenn jemand in unserer Gemeinschaft, der Gemeinschaft der Wissenschaftsskeptiker oder Realisten®, über Unsicherheit und deren Auswirkungen auf von Experten begutachtete wissenschaftliche Ergebnisse spricht, wird er sofort beschuldigt, Wissenschaftsleugner zu sein oder zu versuchen, den gesamten Bereich der Wissenschaft zu untergraben.
Ich habe hier immer wieder darüber geschrieben, dass die Ergebnisse der meisten Studien in der Klimawissenschaft die Unsicherheit ihrer Ergebnisse bei weitem unterschätzen. Lassen Sie mich dies so deutlich wie möglich sagen: Jedes Ergebnis, das keine ehrliche Diskussion der mit der Studie verbundenen Unsicherheiten enthält, angefangen bei den Unsicherheiten der Rohdaten bis hin zu den Unsicherheiten, die durch jeden Schritt der Datenverarbeitung hinzugefügt werden, ist die digitale Tinte nicht wert, mit der es veröffentlicht wird.
[Hervorhebung vom Übersetzer]
Eine neue große, von mehreren Forschungsgruppen durchgeführte und in den Proceedings of the National Academy of Sciences veröffentlichte Studie wird die Forschungswelt aufrütteln. Sie stammt ausnahmsweise nicht von John P.A. Ioannidis, der für sein Buch „Why Most Published Research Findings Are False“ bekannt ist.
Der Titel der Studie lautet [übersetzt]: „Die Beobachtung vieler Forscher, die dieselben Daten und Hypothesen verwenden, enthüllt ein verborgenes Universum idiosynkratischer Ungewissheit“ [ oder als .pdf hier].
Das ist gute Wissenschaft. So sollte Wissenschaft gemacht werden. Und so sollte Wissenschaft veröffentlicht werden.
Erstens, wer ist der Verfasser dieser Studie?
Das waren Nate Breznau und viele viele andere. Breznau ist an der Universität Bremen tätig. Bei den Koautoren gibt es eine Liste von 165 Koautoren aus 94 verschiedenen akademischen Einrichtungen. Das bedeutet, dass es sich nicht um die Arbeit einer einzelnen Person oder einer einzelnen verärgerten Forschungsgruppe handelt.
Was haben sie getan?
Die Forschungsfrage lautet wie folgt: „Werden verschiedene Forscher zu ähnlichen Ergebnissen kommen, wenn sie dieselben Daten analysieren?„
Sie taten dies:
„Dreiundsiebzig unabhängige Forschungsteams haben identische länderübergreifende Umfragedaten verwendet, um eine etablierte sozialwissenschaftliche Hypothese zu testen: dass mehr Einwanderung die öffentliche Unterstützung für die Bereitstellung von Sozialmaßnahmen durch die Regierung verringert.“
Was haben sie herausgefunden?
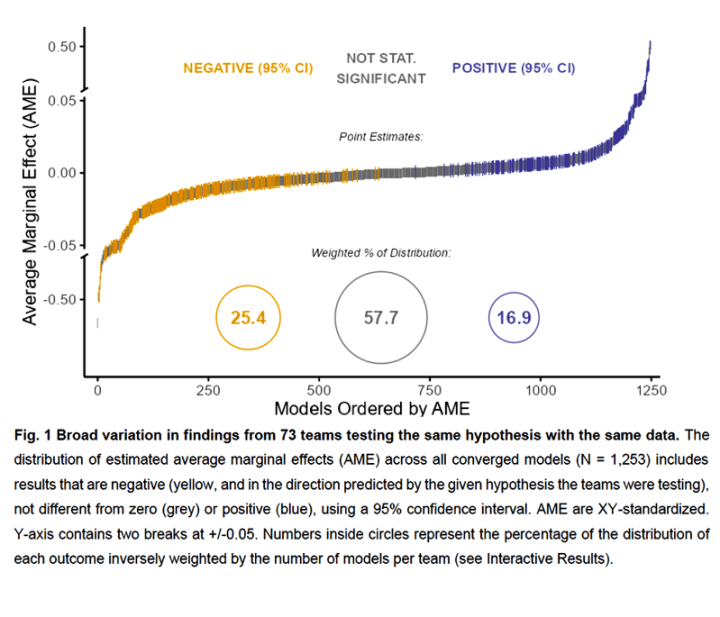
„Anstelle einer Konvergenz variierten die numerischen Ergebnisse der Teams stark und reichten von großen negativen bis zu großen positiven Auswirkungen der Einwanderung auf die öffentliche Unterstützung.“
Eine andere Möglichkeit, dies zu betrachten, besteht darin, die tatsächlichen numerischen Ergebnisse der verschiedenen Gruppen zu betrachten, die dieselbe Frage unter Verwendung identischer Daten stellten:
 Der Diskussionsteil beginnt mit folgendem Satz:
Der Diskussionsteil beginnt mit folgendem Satz:
„Diskussion: Die Ergebnisse unseres kontrollierten Forschungsdesigns in einem groß angelegten Crowdsourcing-Forschungsprojekt, an dem 73 Teams beteiligt waren, zeigen, dass die Analyse derselben Hypothese mit denselben Daten zu erheblichen Unterschieden bei den statistischen Schätzungen und inhaltlichen Schlussfolgerungen führen kann. Tatsächlich kamen keine zwei Teams zu den gleichen numerischen Ergebnissen oder trafen während der Datenanalyse die gleichen wichtigen Entscheidungen.“
Will jemand noch mehr wissen?
Wenn Sie wirklich wissen wollen, warum Forscher, die dieselbe Frage stellen und dieselben Daten verwenden, zu völlig unterschiedlichen und widersprüchlichen Antworten kommen, müssen Sie die Studie lesen.
Was hat dies mit dem Many-Analysts-Ansatz zu tun?
Im Juni letzten Jahres habe ich über einen Ansatz für wissenschaftliche Fragen geschrieben, der sich „The Many-Analysts Approach“ nennt.
Der Many-Analysts-Ansatz wurde wie folgt angepriesen:
„Wir argumentieren, dass die derzeitige Art der wissenschaftlichen Veröffentlichung – die sich mit einer einzigen Analyse begnügt – die „Modell-Myopie“, eine begrenzte Berücksichtigung statistischer Annahmen, verfestigt. Dies führt zu übermäßigem Selbstvertrauen und schlechten Vorhersagen. … Um die Robustheit ihrer Schlussfolgerungen zu beurteilen, sollten die Forscher die Daten mehreren Analysen unterziehen, die idealerweise von einem oder mehreren unabhängigen Teams durchgeführt werden.“
In der neuen Studie, die heute diskutiert wird, heißt es dazu:
„Selbst hoch qualifizierte Wissenschaftler, die motiviert sind, zu genauen Ergebnissen zu kommen, unterscheiden sich enorm in dem, was sie herausfinden, wenn ihnen dieselben Daten und Hypothesen zur Prüfung vorgelegt werden. Die übliche Präsentation und der Konsum wissenschaftlicher Ergebnisse legten nicht die Gesamtheit der Forschungsentscheidungen im Forschungsprozess offen. Unsere Schlussfolgerung ist, dass wir ein verborgenes Universum idiosynkratischer Forschervariabilität erschlossen haben.“
Und das bedeutet für Sie und mich, dass weder der Ansatz mit vielen Analysten noch der Ansatz mit vielen Analyseteams das Real World™-Problem lösen wird, das sich aus den inhärenten Unsicherheiten des modernen wissenschaftlichen Forschungsprozesses ergibt – viele Analysten/Teams werden leicht unterschiedliche Ansätze, unterschiedliche statistische Verfahren und leicht unterschiedliche Versionen der verfügbaren Daten verwenden. Die Teams treffen Hunderte von winzigen Annahmen, die sie meist als „beste Praktiken“ betrachten. Und aufgrund dieser winzigen Unterschiede kommt jedes Team zu einem absolut vertretbaren Ergebnis, das mit Sicherheit einer Peer-Review standhält, aber jedes Team kommt zu unterschiedlichen, ja sogar widersprüchlichen Antworten auf dieselbe Frage, die an dieselben Daten gestellt worden ist.
Das ist genau das Problem, das wir in CliSci jeden Tag sehen. Wir sehen dieses Problem in der Covid-Statistik, der Ernährungswissenschaft, der Epidemiologie aller Art und vielen anderen Bereichen. Dies ist ein anderes Problem als die unterschiedlichen Voreingenommenheiten bei politisch und ideologisch sensiblen Themen, der Druck in der Wissenschaft, Ergebnisse zu finden, die mit dem aktuellen Konsens im eigenen Fachgebiet übereinstimmen, und die schleichende Krankheit der Kumpel-Begutachtung (Pal-Review).
In der Klimawissenschaft herrscht der Irrglaube vor, dass mehr Verarbeitung – Mittelwertbildung, Anomalien, Kriging, Glättung usw. – die Unsicherheit verringert. Das Gegenteil ist der Fall: mehr Verarbeitung erhöht die Unsicherheiten. Die Klimawissenschaft erkennt nicht einmal die einfachste Art der Unsicherheit an – die ursprüngliche Messunsicherheit – sondern wünscht sie sich weg.*
[*Einschub des Übersetzers: In seiner über 40-jährigen Praxis im Bereich Wetteranalyse und -vorhersage konnte der Übersetzer die Erfahrung machen, dass numerische Modelle im Kurzfristbereich zwar eine enorme Verbesserung der Vorhersagegüte erzielt werden konnte, während mittel- und langfristig (4 bis 10 Tage) im Voraus die Unsicherheiten direkt proportional zur Anzahl der Modellrechnungen stiegen.
Um die Güte numerischer Modellrechnungen zu testen, wird der Anfangszustand in ein und demselben Modell künstlich geringfügig verändert. Denn auch die Numerik kann nur auf der Grundlage aktueller Meldungen funktionieren. Nun gibt es aber bekanntlich riesige Meldelücken, die zwar mit High Tech überbrückt werden können (z. B. Fernerkundung mittels Satelliten), aber Extrapolationen müssen trotzdem gemacht werden. Die winzigen Änderungen des Ausgangszustandes sind mit bloßem Auge gar nicht erkennbar.
Lässt man nun aber die Modelle mit diesen geringfügigsten Änderungen immer wieder laufen, zeigt sich Folgendes:
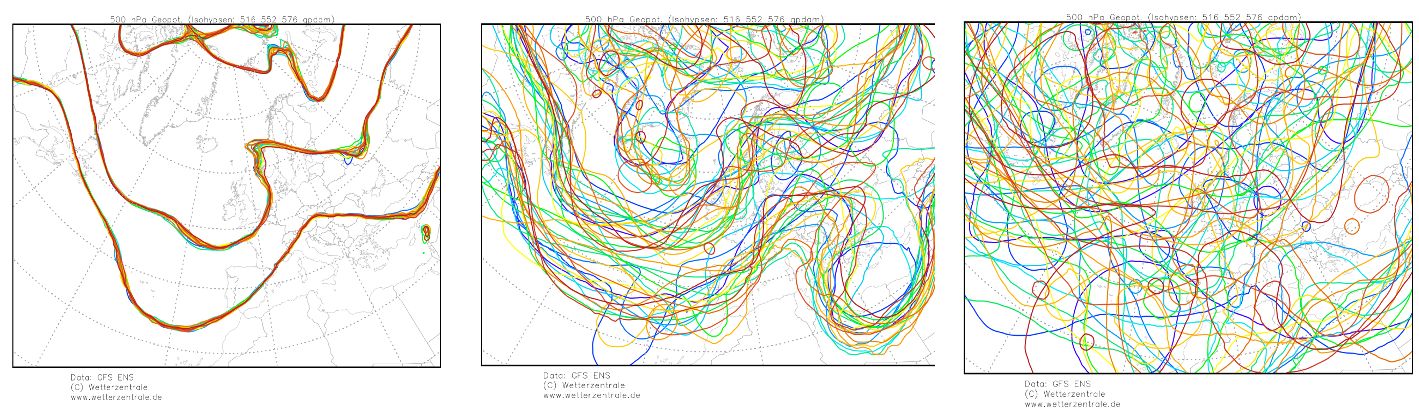
Abbildung 2: Numerische Simulation der Änderung im 500-hPa-Niveau. Links: nach 24 Stunden (1 Tag; Quelle), Mitte: nach 168 Stunden (1 Woche; Quelle), Rechts: nach 384 Stunden (15 Tage; Quelle)
Fazit: Nach einer Woche ist immerhin noch tendenziell ein Strömungsmuster erkennbar, nach 15 Tagen aber nicht mehr. Alle Lösungen beruhen auf der gleichen Ausgangslage und sind gleich wahrscheinlich!
Nun ja, unsere werten Alarmisten, Politiker und MSM wollen uns ja einreden, dass sie derartige Simulationen für viele Jahrzehnte im Voraus berechnen können – mit einer Zuverlässigkeit, die angeblich schon jetzt drastische Maßnahmen mit in jeder Hinsicht verheerenden Folgen erfordert!
Ende Einschub]
Ein anderer Ansatz, der sich sicher anbietet ist, die Ergebnisse der divergierenden Befunde nun einer Mittelwertbildung zu unterziehen oder den Mittelwert – eine Art Konsens – der Vielzahl von Befunden zu finden. Die Abbildung der Ergebnisse zeigt diesen Ansatz als den Kreis mit 57,7% der gewichteten Verteilung. Diese Idee ist nicht valider als die Mittelwertbildung von chaotischen Modellergebnissen, wie sie in der Klimawissenschaft praktiziert wird – mit anderen Worten: wertlos.
Pielke Jr. schlägt in einer kürzlich gehaltenen Präsentation und einer anschließenden Frage- und Antwortrunde mit der National Association of Scholars vor, dass es wahrscheinlich der beste Ansatz ist, die besten echten Experten in einem Raum zusammenzubringen und diese Kontroversen zu klären. Pielke Jr. ist ein anerkannter Fan des vom IPCC verwendeten Ansatzes – allerdings nur, solange dessen Ergebnisse nicht von Politikern beeinflusst werden. Trotzdem neige ich dazu zuzustimmen, dass es zu besseren Ergebnissen führen könnte, wenn man die besten und ehrlichsten (nicht kämpfenden) Wissenschaftler eines Fachgebiets zusammen mit Spezialisten für Statistik und die Bewertung von Programmmathematik in einem virtuellen Raum versammelt, mit dem Auftrag, die größten Unterschiede in den Ergebnissen zu überprüfen und zu beseitigen.
Man frage nicht mich
Ich bin kein aktiver Forscher. Ich habe keine spontane Lösung für die „Drei Ks“ – die Tatsache, dass die Welt 1) kompliziert, 2) komplex und 3) chaotisch ist. Diese drei Faktoren addieren sich und schaffen die Unsicherheit, die jedem Problem innewohnt. Diese neue Studie fügt eine weitere Ebene hinzu – die Ungewissheit, die durch die vielen kleinen Entscheidungen verursacht wird, die die Forscher bei der Analyse einer Forschungsfrage treffen.
Es hat den Anschein, dass die Hoffnung, die Ansätze mit vielen Analysten und vielen Analyseteams würden zur Lösung einiger der kniffligen wissenschaftlichen Fragen unserer Zeit beitragen, enttäuscht wurde. Es hat auch den Anschein, dass wir eher misstrauisch als beruhigt sein sollten, wenn Forschungsteams, die behaupten, unabhängig zu sein, zu Antworten kommen, die den Anschein einer zu engen Übereinstimmung haben.
[Hervorhebung vom Übersetzer]
Kommentar des Autors:
Wenn Sie sich dafür interessieren, warum sich Wissenschaftler selbst bei einfachen Fragen nicht einig sind, dann müssen Sie diese Studie unbedingt lesen, und zwar jetzt. Pre-print .pdf hier.
Wenn es Ihr Verständnis für die Schwierigkeiten, gute und ehrliche Wissenschaft zu betreiben, nicht ändert, brauchen Sie wahrscheinlich eine Gehirntransplantation. … Oder zumindest einen neuen Kurs über kritisches Denken für Fortgeschrittene.
Wie immer sollten Sie sich nicht auf mein Wort verlassen. Lesen Sie den Artikel, und gehen Sie vielleicht zurück und lesen Sie meinen früheren Artikel über Many Analysts.
Gute Wissenschaft ist nicht einfach. Und da wir immer schwierigere Fragen stellen, wird es auch nicht einfacher werden.
Die einfachste Sache der Welt ist es, neue Hypothesen aufzustellen, die vernünftig erscheinen, oder unrealistische Vorhersagen für die Zukunft zu machen, die weit über unsere eigene Lebenszeit hinausgehen. Die Zeitschrift Popular Science hat mit solchen Dingen einen Geschäftsplan gemacht. Die heutige „theoretische Physik“ scheint ein Spiel daraus zu machen – wer kann die verrückteste und dennoch glaubwürdige Idee darüber entwickeln, „wie die Dinge wirklich sind“.
Link: https://wattsupwiththat.com/2022/10/17/a-hidden-universe-of-uncertainty/
Übersetzt von Christian Freuer für das EIKE














{kind=link}
{kind=link}
{kind=link}
{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"So ist es wohl bei komplexen Themen, bei denen keine einfache Lösungen in Sicht sind und wo Einzelergebnisse vieler Wissenschaftler zu einem Gesamtbild zusammengefügt werden. Und die dann auch noch mit politischen Intentionen für Politiker und Journalisten „passend“ verdichtet werden. Schon bei ehrlichem Bemühen keine lösbare Aufgabe, wie der Artikel aufzeigt. Und grüne Medien wie die Alpenprawda verkaufen das dann ihrer Leserschaft als das umfassendste, neueste und beste Ergebnis der gesamten Klima-Wissenschaft. Wer wagt da noch zu zweifeln? Wie fragwürdig und unsicher die Ergebnisse in aller Regel sind, das bleibt verborgen. Auch die riesige Anzahl der beteiligten Klimawissenschaftler täuscht darüber hinweg. Eigentlich nichts anderes als eine raffinierte, aufwendige und teure Verdummung, die die Öffentlichkeit in aller Regel nicht durchschauen kann. Verdummung wie beim 97%-Konsens, nur raffinierter.
Obiger Artikel gefällt!
Offenbar können wir das „Ding an sich“ nicht einheitlich identifizieren und/oder erklären. Ein sehr schön beschriebenes wissenschaftliches Dilemma zu unsere schönen opaken Welt.
Die Diagnose eines Arztes (bei lebensbedrohlicher Situation) könnte stimmen, die abweichende Zweitmeinung demnach aber auch, oder irren beide. Bringt der Losentscheid Patientenglück. Der Arzt wird im Zweifel strafrechtlich (sich absichernd) und/oder ökonomischen denken. Aus obigen Artikel lernen wir, dass es ggf. auch nach der 10. Arztbefragung nicht besser werden muss. Und der Mittelwert der Diagnosen sagt auch nichts aus. Ein wunderschönes Dilemma, welches zeigt das unsere Leben vom Zufall dominiert wird.
Was fällt uns dazu zur Klimarettungsforschung ein? 1. Tausende von Wissenschaftler, die alle Karriere machen wollen oder eine Mission haben, sind am Thema, die das Klima nicht als komplexe zufallsbestimmte, opake, nicht-triviale Maschine verstehen wollen. 2. Keine identischen, teils strittige, teils interpolierte (erzeugte), da nicht vorhandene, Ausgangsmesswerte werden verwendet. 3. Eingabe der Messwerte in verschiedenste, konkurrierende, die Realität stark vereinfachende, Modelle. 4. Bewertung der Rechnungsergebnissen durch eine Vielzahl von Wissenschaftlern, die auch Eigeninteressen haben (müssen). Zusammenfassender Deutungs-Bericht (tausende von Berichtsseiten, z.B. IPCC), nicht verarbeitbar für den Adressaten (Politics, Bevölkerung), nicht als vorläufige Erkenntnisse präsentiert. 5. Verarbeitung/Vereinfachung durch Weglassung und Uminterpretation der Berichtsergebnisse in Verbindung mit Handlungsvorschlägen durch Lobbyisten und Propagandisten für Politik, Parteien, Industrie und Bevölkerung. Was kann dabei, gemäß obigen Artikels, rauskommen ? Murks, sehr teurer Murks, für die Politics gut ausschlachtbarer, nunmehr Ideologie-Murks. (Wollte man es böse ausdrücken: Derzeitige Klimarettungsforschung ist infantile alimentierte Selbstbefriedigung, deren Ergüsse von Lobbyisten, Politics und der „Wissenschaft“ selbst zur Abschöpfung der Bevölkerung trefflich nutzbar ist und genutzt. Dieses System zum Ablasshandel aufgestiegen, mit schädlichsten Nebenwirkungen.)
Dennoch lebe die Wissenschaft an sich hoch, denn es gibt ja auch überzeugende nützliche Erkenntnisse.
Die Logik sagt doch, so lange die „Verfechter“ einer Klimaerwärmung durch CO2 nicht in der Lage sind, Zweifel an ihrer Verfechtertheorie klar zu widerlegen, so lange spricht eben die Logik dafür, daß an diesem Zweifel etwas dran sein muß. Weil Zweifelhaltung ist in der wissenschaftlichen Diskussion so lange ein Muß, bis alle vor allem eigenen Zweifel vollkommen ausgeräumt sind.
Meine persönliche Erfahrung ist, je länger und intensiver ich mich mit der Materie „Klimaerwärmung durch CO2“ befasse, desto größer werden die Zweifel, nicht kleiner! Beim sog. Treibhauseffekt ist für mich das Basismißtrauen schon dadurch begründet, daß es keine exakte wissenschaftliche Definition gibt, was dieser Effekt eigentlich macht. Diese Frage konnte mir bisher auch noch niemand klar beantworten.
Ich bin außerdem noch der „altmodischen Ansicht“, daß ein einziger Widerspruch zu einer Theorie genügt, die ganze Theorie umzuwerfen.
Wenn Sie das Buch lesen „Die Treibhaushypothese alles Schall und Rauch?“ (hier) wird Sie das in Ihren Zweifeln bestärken.
Admin,
vielen Dank für den Hinweis. Ich hab mir das Büchlein gegen Einwurf kleiner Münzen vor einigen Monaten sogar besorgt.
Es bestätigt meine Standpunkte. In meinem „Repertoire“ befinden sich darüber hinaus noch eine Menge weiterer Argumente, die allesamt gegen die CO2-Erwärmungstheorie sprechen. Und auch die Diskussionen hier bringen immer wieder ergänzende Aspekte, die neu ins Repertoire aufgenommen werden.
Die Schlußfolgerung aus dem Artikel sei demzufolge, dass Wissenschaft abgeschafft werden soll und wir lieber wieder zurück auf die Bäume klettern.
Wenn das Ihre Schlussfolgerung ist, dann haben Sie nichts, aber auch gar nichts verstanden.
Wobei, das mit den Bäumen wäre doch für Sie erkenntnisreich. Da kann man – im Winter – ganz gut die Welt von oben sehen. Im Sommer sieht man jedoch den Wald vor Bäumen nicht. Sie haben die Wahl.
@Thomas Heinemann am 25. Oktober 2022 um 15:51
Ein besseres Eigentor, Herr Heinemann, ist wohl nicht möglich!!! …. Aber wie ich Sie hier regelmäßig erlebe, gibt es dennoch noch persönliche Steigerungmöglichkeiten …. 😉