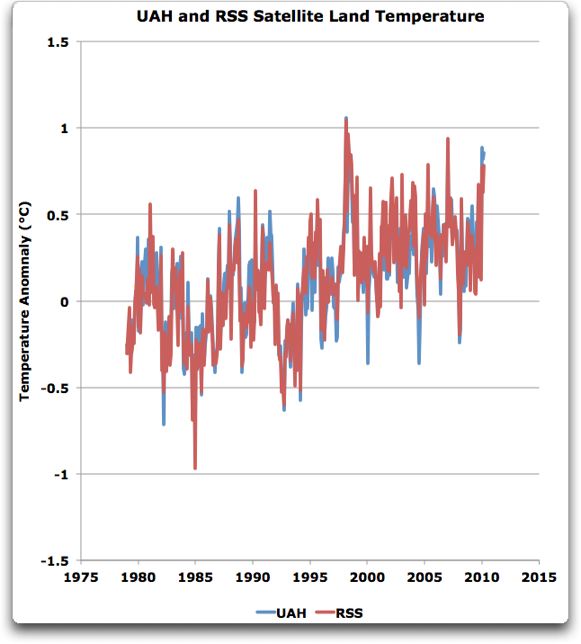
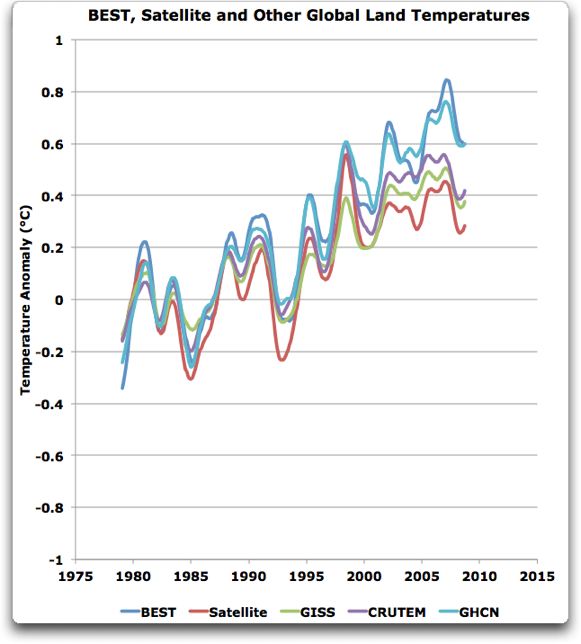
Keine Steuern auf Entwicklung, es tut den Armen weh!
Einer ihrer Testfälle ist die Suche nach einer Beziehung zwischen Größenordnungen globaler Indikatoren. Hier folgt eine Liste der Ergebnisse durch die MIC-Methode:

Abbildung 1: Signifikante Beziehungen, gekennzeichnet durch den maximalen Informationskoeffizienten. Auf herkömmliche Art wird diese Beziehung durch den Pearson-Koeffizienten gemessen.
Der seltsamste Wert in dieser Liste ist der MIC auf Rang drei, die Beziehung zwischen dem Ölverbrauch und dem Einkommen, jeweils pro Person. Mit dem Pearson-Koeffizienten lag diese Beziehung an 207. Stelle, der MIC an 3. Stelle. Das motivierte mich zu einem weiteren Blick auf den Zusammenhang zwischen Energie und Entwicklung.
Um dies zu tun, benutzte ich “Gapminder World”, ein faszinierendes Online-Tool, um Daten zu visualisieren. Abbildung 2 zeigt davon ein Beispiel, und zwar einen Vergleich zwischen mittlerem Energieverbrauch und Einkommen, jeweils pro Kopf. Jedes Land wird in den Diagrammen durch eine „Blase“ symbolisiert.
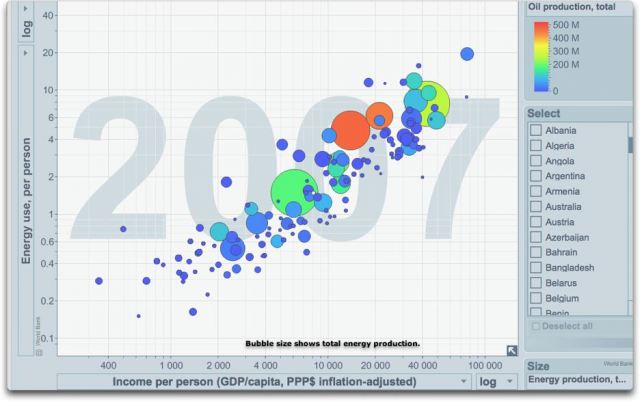
Abbildung 2: Blasendarstellung des Zusammenhangs von Pro-Kopf-Verbrauch von Energie, unterteilt nach Ländern (vertikale Achse) und Einkommen pro Kopf (horizontale Achse). Man beachte, dass beide Achsen logarithmisch sind. Die Größe einer individuellen Blase kennzeichnet die Gesamtenergieerzeugung in diesem Land. Die Farbe der Blasen steht für die Gesamtölproduktion in diesem Land. Der Energieverbrauch wird in Tonnen pro Öläquivalent (TOE) angegeben. Quelle
Wie man erkennen kann, gibt es eine klare und lineare Beziehung zwischen dem Energieverbrauch und dem Einkommen. Dies führt zu einer unerbittlichen Schlussfolgerung: Man kann aus der Armut ohne Zugang zu erschwinglicher Energie nicht heraus kommen. Abbildung 3 unten zeigt die gleichen Daten mit Identifikation der größten Energieproduzenten.
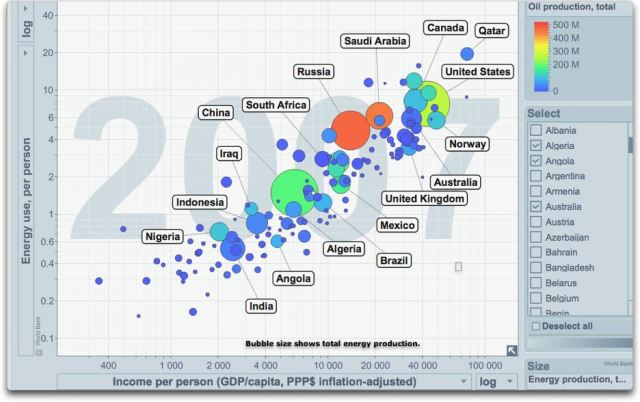
Abbildung 3: Wie Abbildung 2, nur diesmal mit der Kennzeichnung der größten Energieproduzenten Quelle.
Die Größe der Blasen zeigt, dass China und die USA hinsichtlich der Gesamtenergieerzeugung etwa gleichauf liegen. Russland liegt an dritter, die Saudis an vierter und – überraschend für mich – Indien an fünfter Stelle. Die Farben zeigen, dass für die Russen und die Saudis die meiste Energie aus Öl erzeugt wird (rot), während in China und den USA auch die Kohle eine Hauptquelle dafür ist. Indien gewinnt seine Energie hauptsächlich aus Kohle.
Abbildung 4 (unten) zeigt die gleiche Vergleichskarte zwischen Energie und Einkommen, aber in unterschiedlicher Weise. Die Größe der Blasen in Abbildung 4 zeigt die Energieerzeugung pro Kopf und nicht die gesamte Energieerzeugung. Alle Blasen liegen an der gleichen Stelle, und nur deren Größe hat sich verändert.
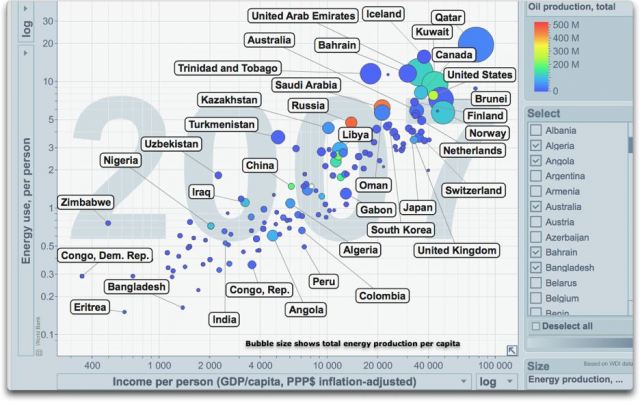
Abbildung 4: Wie die oberen beiden, nur das die Größe der Blasen hier für die Energieerzeugung pro Kopf steht. Quelle
Aus den Abbildungen 3 und 4 kann man einige neue Schlussfolgerungen ziehen. Eine lautet, dass man nicht viel Energie erzeugen muss, weder pro Kopf noch insgesamt, um eine moderne, industriell entwickelte Wirtschaft zu haben (die Menge der kleinen Blasen oben rechts). Die Niederlande und Japan sind hierfür Beispiele. Die zweite lautet, wenn man eine hohe Energieerzeugung pro Kopf hat, kommt man leichter zu einem hohen Pro-Kopf-Einkommen (Überlegenheit der großen Blasen oben rechts).
Die Website Gapminder erlaubt uns auch, einen Blick auf die Geschichte der verschiedenen Länder zu werfen. Hier folgt die Entwicklung in einigen Ländern mit der Zeit. Das Niveau, auf dem die Namen der Länder stehen, zeigt jeweils den Beginn der Aufzeichnung.
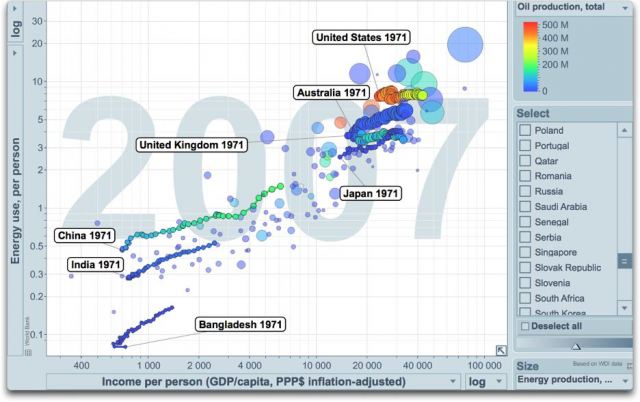
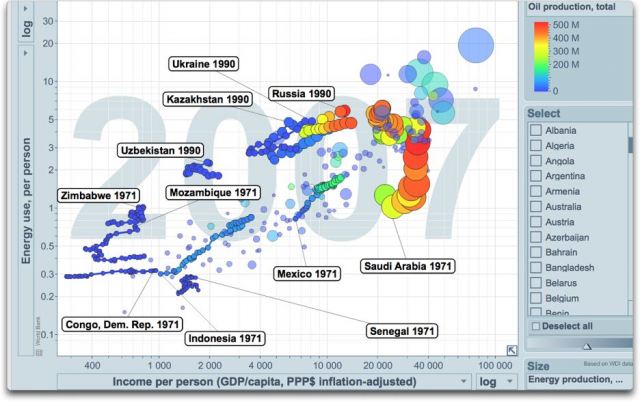
Abbildungen 5 und 6: Wie in Abbildung 3, jedoch jetzt mit der Entwicklung einiger Länder von 1971 bis 2007. Die Größe der Blasen steht für die Pro-Kopf-Energieerzeugung in diesem Land. Die Farbe der Blasen steht für die Gesamtölproduktion in diesem Land. „Spurlinien“ zeigen die Werte Jahr für Jahr. Beide Skalen sind logarithmisch. Abb. 5 Quelle1, Abb. 6: Quelle2*.
[*Im Original steht in der letzten zeile der Bildunterschrift Fig. 4 bzw. Fig. 5. Dies halte ich für ein Versehen des Autors, da sich ja beides auf die Abbildungen 5 und 6 bezieht. A. d. Übers.]
Einige Bemerkungen zu den historischen Abbildungen. Zunächst wird die Richtung, die Sie für Ihr Land sehen möchten, eine Bewegung nach unten und nach rechts sein. Dies würde für weniger Energieverbrauch und mehr Einkommen stehen. Ganz allgemein bewegt sich jedoch fast kein Land in dieser Richtung.
Die schlechte Richtung wäre nach oben und nach links. Dies stünde für einen größeren Energieverbrauch, um weniger Geld zu verdienen. Hässlich! Die Saudis haben sich während der letzten Jahre in diese Richtung bewegt.
Einige Länder liegen im ungünstigsten Quadranten links unten. Hier wird weniger Energie verbraucht und auch weniger Geld verdient. Zimbabwe und die „demokratische“ Republik Kongo stehen dort. Schlechtes Zeichen! Es bedeutet Rück-Entwicklung und schließt in der Regel ein, dass sowohl die Menschen dort als auch die Umwelt leiden.
Bleibt der vierte Quadrant rechts oben. Hier wird mehr Energie verbraucht und mehr Geld verdient. Gemeinhin nennt man das „Entwicklung“ alias aus der Armut herauskommen. Man verdient genug Geld, um sich den Schutz der Umwelt leisten zu können.
Die Spielregel lautet, sich so weit wie möglich nach rechts (zunehmendes Geld) und sich so wenig wie möglich nach oben (zunehmender Energieverbrauch) zu bewegen. Bangladesh beispielsweise steht nicht so gut da wie Indien, da es sich steiler nach oben bewegt. In den siebziger und achtziger Jahren China war genauso gut wie Indien, aber während des letzten Jahrzehnts der Aufzeichnung ging es steiler nach oben. Man beachte, dass Indien seine Energie hauptsächlich aus Kohle erzeugt.
Russland bewegte sich Anfang der neunziger Jahre nach unten und nach links, hat sich aber seitdem erholt und das Einkommen fast verdoppelt, ohne wesentliche Zunahme des Energie[verbrauchs]. Es ist kurios, dass das Einkommen jetzt auf dem Niveau von 1990 liegt, aber der Energieverbrauch geringer ist. Das Gleiche gilt für Usbekistan und viele andere frühere Mitglieder der Sowjetunion. Zu ihren Gunsten [muss gesagt werden], dass sie sich aus dem Zusammenbruch der Sowjetunion heraus gekämpft haben und zu einer effizienteren Form zurück gekehrt sind. Tatsächlich haben sich die Usbeken während der vergangenen Dekade nach unten und nach rechts bewegt, und das ist der Heilige Gral der Entwicklung, mehr zu produzieren mit weniger Energieverbrauch.
Die armen Saudis andererseits bewegen sich inzwischen fast senkrecht nach oben (sie brauchen mehr Energie, um das gleiche Einkommen zu erzielen) und haben sogar etwas an Boden verloren. Und Senegal hat sich nirgendwohin bewegt.
In Japan, China, Mexiko und Australien hat sich die Pro-Kopf-Energieerzeugung während der Periode erhöht (Blasengröße), während sie in den USA und Russland in etwa gleich geblieben ist. Die Gesamtölproduktion in den USA ist zurück gegangen (Blasenfarbe), während sie in China zugenommen hat. Die russische Ölerzeugung ist erst zurück gegangen, hat sich aber wieder erholt.
In USA und UK tat sich etwas Merkwürdiges. Der Pro-Kopf-Energieverbrauch in beiden Ländern lag jeweils 2007 etwa gleich hoch wie 1979. Aber das Einkommen hat sich erhöht. In beiden Ländern hat sich das Pro-Kopf-Einkommen fast verdoppelt, praktisch ohne jede Erhöhung des Pro-Kopf-Energieverbrauchs. Ich weiß nicht, was sie richtig machen, aber wir sollten es herausfinden und kopieren…
Schlussfolgerungen und –bemerkungen:
1. Entwicklung ist Energie, und Energie ist Entwicklung. Obwohl einem Effizienz und Konservierung helfen können, muss man im Allgemeinen den Energieverbrauch steigern, um das persönliche Einkommen so zu erhöhen, dass man aus der Armut herauskommt. Verteuert man die Energie, ist das erheblich rückschrittlich, da sich die armen Länder und die armen Leute das einfach nicht leisten können. Kohlenstoffsteuern, „Zertifikatehandel“ oder andere Energiesteuern sind ein Verbrechen gegen die weniger begünstigten Bewohner unseres Planeten.
2. Große Länder mit höheren Transportkosten werden pro Dollar Einkommen mehr Energie verbrauchen als kleine Länder.
3. Innerhalb der „Wolke” von Ländern in Abbildung 3 ist es möglich, die Energieeffizienz zu steigern und mehr Geld mit der gleichen Menge verbrauchter Energie zu verdienen.
4. Länder mit hoher Energieerzeugung tendieren dazu, mehr davon zu verschwenden als andere Länder mit geringer Energieerzeugung.
5. Die bevorzugte Stelle für jedes gegebene Einkommensniveau befindet sich am unteren Rand der „Wolke“ der Länder mit diesem Einkommen. Hier bekommen Sie das meiste Geld für Ihre Arbeit. Viele europäische Länder liegen an dieser Stelle. Die USA und Kanada liegen etwa in der Mitte der Wolke. Allerdings sind sie wie erwähnt viel größer als die europäischen Länder.
6. China, Indien und Bangladesh wiesen 1971 in etwa das gleiche Pro-Kopf-Einkommen auf, circa 700 Dollar pro Jahr. Die Unterschiede ihrer jetzigen Position sind groß, hat doch Bangladesh ein solches Einkommen von 1400 Dollar, Indien von 2600 Dollar und China von 6000 Dollar pro Jahr.
7. Leider reichen die Datensätze nur bis 2007… es wäre interessant zu sehen, in welche Richtung sich sowohl der Energieverbrauch als auch das Einkommen im Zuge der globalen Finanzkrise bewegen.
8. Zum Schluss: wenn jemand das Wort „Technologie“ in den Mund nimmt, denken viele Umweltaktivisten sofort an „Bulldozer“. Sie sollten lieber an „Energieeffizienz“ denken! Schließlich leistet Technologie mehr mit weniger. Es ist die Technologie, die es uns gestattet, weniger Benzin pro Meile zu verbrauchen. Durch eine gewisse Kombination von Konservierung und technologischer Fortschritte waren die USA und UK in der Lage, ihr Einkommen bei gleichem Energieverbrauch zu verdoppeln. Von diesem technologischen Fortschritt profitieren sowohl jeder Einzelne als auch die Umwelt.
P.S.: Die Links zu den Quellen unter jeder Abbildung verweisen auf die korrespondierenden Abbildungen auf der Website Gapminder. Dort kann man mit den Variablen spielen oder die Geschichte der Länder verfolgen, die ich hier nicht erwähnt habe.
Weitere Beiträge des Autors: Willis Eschenbach
Link zum Artikel, auf den sich Eschenbach ganz oben bezieht: “Detecting Novel Associations in Large Data Sets“
Link: http://wattsupwiththat.com/2011/12/19/dont-tax-development-it-hurts-the-poor/
Übersetzt von Chris Frey für EIKE