Wassertemperatur der Ozeane – was wissen wir wirklich?
Der nächste Beitrag [auf Deutsch hier] behandelt die Mischschicht, die eine Schicht mit gleichmäßiger Temperatur direkt unter der Hautschicht ist. Die gemischte Schicht sitzt oberhalb der Sprungschicht, wo die Wassertemperatur schnell zu fallen beginnt. Der nächste Beitrag [auf Deutsch hier] behandelte die Unterschiede zwischen verschiedenen Schätzungen der SST, die verwendeten Daten und die Probleme mit den Messungen und den Korrekturen. Der Schwerpunkt lag dabei auf den beiden Hauptdatensätzen, HadSST und NOAAs ERSST [auf Deutsch hier]. Der letzte Beitrag diskutiert SST-Anomalien [auf Deutsch hier] war die Logik, wenn alle Messungen von knapp unter der Meeresoberfläche stammen, warum werden dann Anomalien benötigt? Warum können wir nicht einfach die Messungen verwenden, korrigiert auf eine nützliche Tiefe, wie 20 cm?
Hintergrund aller Beiträge ist es, die Analyse so nah wie möglich an den Messungen auszurichten. Zu viele Korrekturen und Datenmanipulationen verwirren die Interpretation, entfernen uns von den Messungen und homogenisieren die Messungen in einem solchen Ausmaß, dass wir ein falsches Gefühl von Vertrauen in das Ergebnis bekommen. Diese durch die Überarbeitung von Daten entstehende Illusion von Genauigkeit wird von William Brigg hier diskutiert. Sein Beitrag befasst sich mit der Glättung von Daten, aber die Argumente gelten auch für die Homogenisierung von Temperaturen, die Erzeugung von Anomalien vom Mittelwert und die Korrektur von Messungen durch statistische Verfahren. All diese Prozesse lassen „die Daten besser aussehen“ und geben uns ein falsches Gefühl von Vertrauen. Wir wissen nicht, wie viel von den resultierenden Diagrammen und Karten auf die Korrekturen und Datenmanipulationen zurückzuführen ist und wie viel auf die zugrunde liegenden Messungen. Wir sind Schritt für Schritt durch alle möglichen Verarbeitungen gegangen und haben bei jedem Schritt untersucht, wie die Temperaturen wirklich aussahen.
Wichtung nach Gebieten
Die in all diesen Beiträgen verwendeten Daten mit Ausnahme der frühesten Beiträge zu den Landmessungen im Hauptgebiet der USA stammen alle aus Breiten- und Längengrad-Gittern. Die Rasterung der Messungen ist global erforderlich, da die Messungen hauptsächlich auf der Nordhalbkugel konzentriert sind und anderswo nebst den beiden Polarregionen sehr spärlich. Wie wir bereits gezeigt haben, sind die Temperaturen der nördlichen Hemisphäre anomal, der Rest der Welt ist viel weniger variabel in seiner Oberflächentemperatur. Siehe hier eine Diskussion hierüber und einige Grafiken. Siehe diesen Beitrag von Renee Hannon und diesen vom gleichen Autor, für weitere Details zu den hemisphärischen Variationen in den Temperaturtrends.
Während eine Rasterung wahrscheinlich nicht notwendig ist und irreführend sein kann, müssen wir in Gebieten wie den USA, die gut mit guten Wetterstationen abgedeckt sind, die verfügbaren Daten rastern, um einen globalen SST-Durchschnitt zu erstellen. Das soll nicht heißen, dass die Rasterung gute Messungen ersetzt oder die Messungen verbessert, sondern nur, dass sie mit den uns zur Verfügung stehenden Daten notwendig ist.
Jede Gitterzelle repräsentiert einen anderen Bereich des Ozeans. Der Unterschied ist nur eine Funktion des Breitengrades. Jeder Breitengrad ist 111 km vom nächsten entfernt. Der Abstand de Längengrade am Äquator beträgt ebenfalls 111 km, nimmt aber an den Polen auf Null ab. Um also die Fläche jeder Gitterzelle zu berechnen, müssen wir nur den Breitengrad der Zelle und die Größe der Gitterzellen in Breiten- und Längengraden kennen. Die Lösung wird von Dr. Math (National Council of Teachers of Mathematics) bereitgestellt und abgeleitet, hier. Ich werde die Erzählung nicht mit einer Gleichung unterbrechen, aber der am Ende des Beitrags verlinkte R-Code zeigt die Gleichung und wie sie verwendet wurde.
Es mag seltsam erscheinen, eine so offensichtliche Korrektur an den Daten als letztes vorzunehmen, aber ich wollte ehrlich gesagt sehen, ob es einen großen Unterschied macht. Es stellt sich heraus, dass es einen erheblichen Unterschied in der berechneten Durchschnittstemperatur macht, aber wenig Unterschied in den Trends. Unten in Abbildung 1 ist die ursprüngliche Abbildung aus dem Beitrag über die gemischte Schicht zu sehen, die verschiedene Schätzungen der SST und der globalen Durchschnittstemperatur der gemischten Schicht vergleicht. Normalerweise, vor allem in der Nacht, liegen die gemischte Schicht und die SST sehr nahe beieinander, so dass man sie alle zusammen plotten kann.

Abbildung 1. Der Vergleich der globalen Temperaturschätzungen für die gemischte Schicht und die SST aus dem Beitrag über die gemischte Schicht. Für eine Erklärung des Plots siehe diesen Beitrag.
Die Kurven in Abbildung 1 sind alle auf eine Tiefe zwischen 20 cm und einem Meter korrigiert. Sie sind Gittermittelwerte, d.h. Mittelwerte von gerasterten Werten, aber sie sind nicht für das Gebiet korrigiert, das durch jeden Gitterwert repräsentiert wird. Abbildung 2 zeigt das gleiche Diagramm, ist aber mit flächengewichteten Gitterzellenwerten konstruiert worden. Wir haben auch eine neue Kurve hinzugefügt, die NOAA ERSST-Kurve, nachdem wir die ERSST-Werte gelöscht haben, die den Nullwerten im HadSST-Datensatz entsprechen. Auf diese Weise vergleichen wir ERSST und HadSST über die gleichen globalen Ozeanbereiche. Der normale ERSST-Datensatz (die untere grüne Linie in Abbildung 1 und die untere braune Linie in Abbildung 2) verwendet Interpolation und Extrapolation, um Gitterzellen zu füllen, die unzureichende Daten haben; diese Zellen sind in HadSST null.
Auf den ersten Blick sehen die beiden Diagramme sehr ähnlich aus, aber man beachte, dass sich die vertikale Skala geändert hat. Alles ist um zwei bis vier Grad nach oben verschoben, da die Polarregionen Zellen mit kleineren Flächen haben. Die NOAA ICOADS SST-Linie befindet sich an der gleichen Stelle, da sie bereits flächenkorrigiert wurde. Es ist auch die Linie, die den Messungen am nächsten kommt. Die Prozesse, die zur Erstellung dieser Linie verwendet werden, sind viel einfacher und weniger kompliziert als die von HadSST und ERSST verwendeten. Der Unterschied zwischen HadSST und ERSST ist immer noch da, aber kleiner. Diese beiden Temperaturaufzeichnungen verwenden ähnliche Daten, aber, wie oben beschrieben, ist ihre Rasterung unterschiedlich und sie decken verschiedene Gebiete ab. Sobald das ERSST-Gitter „maskiert“ ist, um mit HadSST übereinzustimmen, steigt es von 18,2 auf 22 Grad an.
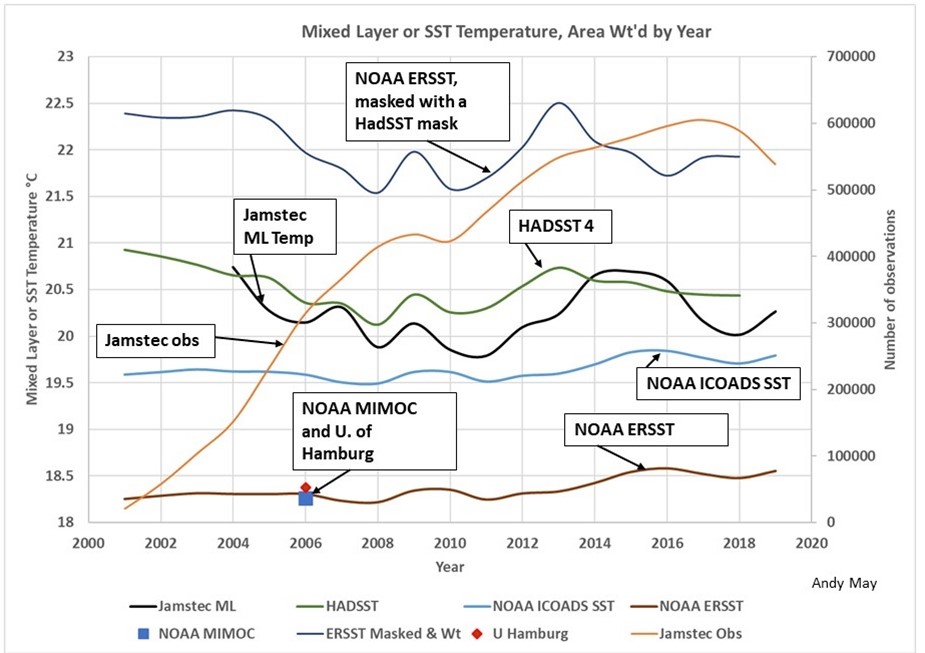
Abbildung 2: Dies ist das gleiche Diagramm wie in Abbildung 1, mit dem Unterschied, dass alle Gitterwerte in den Datensätzen nach den Gitterzellenbereichen gewichtet sind, die sie darstellen. Man beachte, dass sich die vertikale Skala geändert hat.
Die mehrjährigen Gittermittelwerte von NOAA MIMOC und der Universität Hamburg liegen in beiden Diagrammen über dem NOAA ERSST-Datensatz, sind aber nach Anwendung des Algorithmus zur Flächengewichtung um etwa 4,5°C wärmer. NOAA MIMOC und die Universität Hamburg erstellen ihre Gitter unter Verwendung von mehr als 12 Jahre alten Daten, so dass sie viel mehr ihres Gitters bevölkern als die Einjahres-Datensätze. Sie wichten auch die Argo- und Bojendaten stark, genau wie NOAA ERSST.
Wie wir mit den ungewichteten Daten im letzten Beitrag [auf Deutsch hier] gesehen haben, tendieren die gemessenen Temperaturen von HadSST nach unten. Wenn das ERSST-Gitter mit den HadSST-Nullwerten maskiert wird, tendiert es ebenfalls nach unten. Dies ist in Abbildung 3 zu sehen.
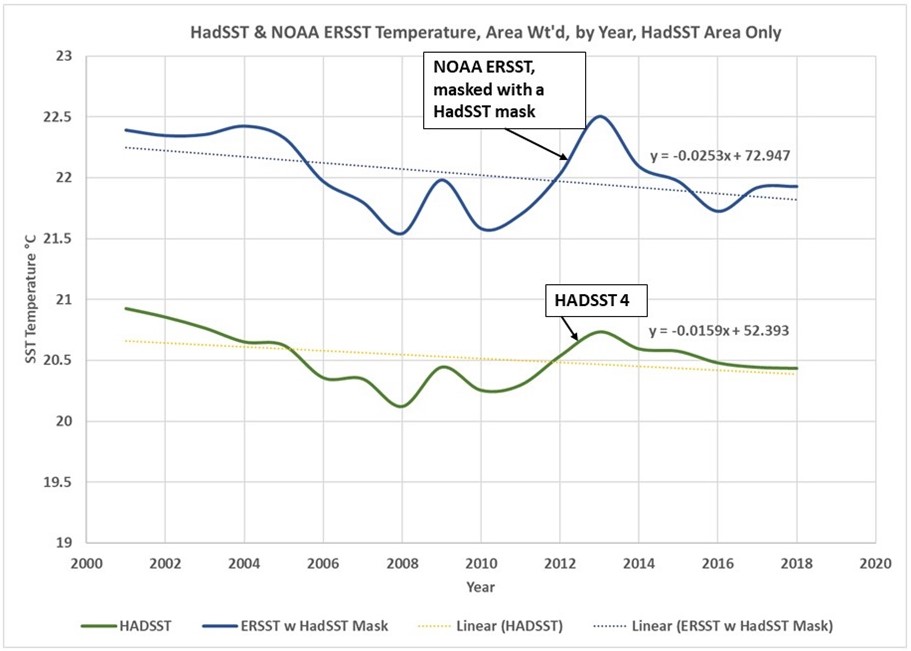
Abbildung 3. Abnehmende SSTs über dem von HadSST abgedeckten Gebiet sind sowohl in den HadSST- als auch in den ERSST-Datensätzen erkennbar.
Der HadSST-Datensatz hat nur Gitterwerte aus Zellen, aus denen genügend Messungen vorhanden sind, um einen solchen Wert zu berechnen, sie extrapolieren keine Daten in angrenzende Gitterzellen wie ERSST. Somit repräsentieren die HadSST-Daten den Teil des Ozeans mit den besten Daten, und dieser Bereich nimmt eindeutig an Temperatur ab, wenn nur die Messungen verwendet werden. Die ERSST-Daten deuten auf einen Rückgang von 2,5 Grad/Jahrhundert hin. Der HadSST-Rückgang beträgt 1,6 Grad/Jahrhundert.
Die ERSST-Linie ohne Maske (Abbildung 2) zeigt einen steigenden Trend von 1,6 Grad/Jahrhundert. Die interpolierten und extrapolierten Bereiche zeigen also eine Erwärmung, die in den Zellen mit den besten Daten nicht zu sehen ist. Wie wir im letzten Beitrag gesehen haben und in diesem Beitrag als Abbildung 4 erneut zeigen, weisen die HadSST- und ERSST-Anomalien nichts von der Komplexität auf, für die wir sechs Beiträge gebraucht haben. Sie zeigen einen gemeinsamen Trend der Erwärmung, von etwa 1,7 Grad/Jahrhundert.

Abbildung 4. Die HadSST- und ERSST-Anomalien.
Schlussfolgerungen
Die beste Art und Weise, Daten zu analysieren, ist die Verwendung des absoluten Minimums an statistischer Manipulation, das erforderlich ist, um sie in einer brauchbaren Form zu präsentieren. Jede Korrektur, jede Berechnung, alle Glättungsoperationen, jeder Rasterungsschritt muss vollständig begründet werden. Es ist eine unglückliche Tatsache des heutigen wissenschaftlichen und technischen Lebens, dass unsere Kollegen ständig mit „das muss korrigiert werden“, „das muss korrigiert werden“ und so weiter kommen. Es wird wenig darüber nachgedacht, wie die Korrekturen unsere Wahrnehmung der resultierenden Diagramme und Karten beeinflussen. Mit genügend Korrekturen kann man einen Misthaufen in ein Schloss verwandeln, aber ist es wirklich ein Schloss?
Ich hatte einmal einen Chef, der sehr klug war. Er wurde schließlich CEO und Vorstandsvorsitzender der Firma, für die wir arbeiteten. Ich war damals viel jünger und gehörte zu den Wissenschaftlern auf der „Peanut Gallery“, die ständig fragten: „Was ist damit?“ „Was ist damit, haben Sie diese Dinge korrigiert?“ Mein Chef sagte dann: „Wir sollten uns nicht selbst übertreffen. Was sagen die Daten, so wie sie sind?“ Nachdem er CEO wurde, verkaufte er die Firma für das Fünffache des durchschnittlichen Basispreises meiner angesammelten Aktienoptionen. Ich war immer noch ein Wissenschaftler, wenn auch ein wohlhabender. Er hatte Recht, genau wie Dr. William Briggs. Studieren Sie die Rohdaten, behalten Sie sie in Ihrer Nähe, übertreffen Sie sich nicht selbst als Wissenschaftler.
——————————
Zu diesem Beitrag hat der Klima-Realist Marcel Crok von clintel.org eine Frage an den Autor gerichtet. Die Antwort desselben wird hier noch mit übersetzt. – Anm. d. Übers.:
Link: https://andymaypetrophysicist.com/2020/12/23/ocean-sst-temperatures-what-do-we-really-know/
Übersetzt von Chris Frey EIKE
Frage von Marcel Crok: Was schließen Sie aus Ihrer Abbildung 3? Wollen Sie damit sagen, dass die besten verfügbaren Daten darauf hindeuten, dass die Ozean-Temperatur abnimmt?
Antwort von Andy May:
Die allerbesten Daten sind in dieser Abbildung dargestellt. Aber sie repräsentiert nur einen Teil des Weltozeans, und das dargestellte Gebiet ändert sich ständig. Dieser sich ständig verändernde Bereich zeigt sinkende gemessene Temperaturen. Die Schiffe, Schwimmer und Bojen, die die Temperatur messen, sind ständig in Bewegung und verändern sich in jeder Zelle. Die Zellen mit Messungen ändern sich ständig. Die „Referenz“-Periode, zwischen 1961-2000, hat sehr schlechte Daten.
Die einzige Möglichkeit, mit diesen miserablen Daten eine positive Anomalie zu erhalten, besteht darin, monatliche Anomalien aus den Zellen mit vielen Messpunkten in diesem Monat zu erstellen und sie dann als einen Datensatz zu präsentieren. Aber es ist eine Aufzeichnung eines sich ständig ändernden Bereichs, was nützt das?
Weniger als die Hälfte des Ozeans hat gute Daten und diese Hälfte ändert sich ständig, da sich die Instrumente und Schiffe bewegen. Ich habe nur einen Jahresdurchschnitt gebildet, um saisonale Anomalien zu vermeiden. So ist die jährliche Durchschnittstemperatur der Zellen mit den besten Daten (wo auch immer sie sind) in den letzten 20 Jahren gesunken. Dies wurde in den letzten Stunden von Nick Stokes, einem australischen Klimatologen bei den WUWT-Kommentaren bestätigt.
Das Erzeugen von Anomalien, insbesondere die Art und Weise, wie HadSST und ERSST es getan haben, entfernt die gesamte zugrundeliegende Komplexität in den Daten und präsentiert eine irreführende Grafik, die auf sehr, sehr schlechten und nicht repräsentativen Daten basiert.
Meine persönliche Schlussfolgerung nach all dieser Arbeit? Wir haben keine Ahnung, was die durchschnittliche Temperatur des Weltozeans ist, noch wissen wir, ob er sich erwärmt oder abkühlt.
[Hervorhebung vom Übersetzer]