Warum die Daten einer Reanalyse keine Daten sind.
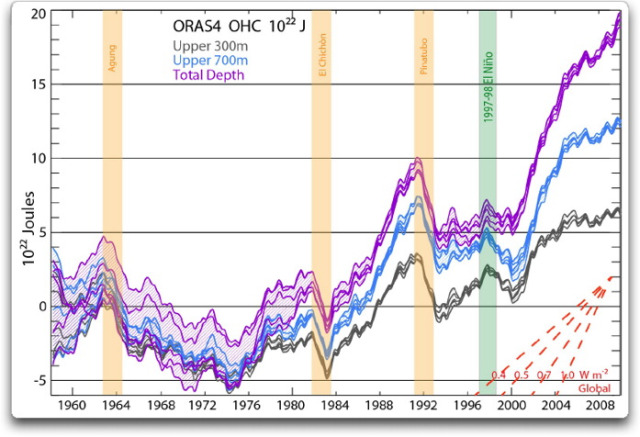
Original-Bildunterschrift: Abbildung 1: OHC integriert von 0 bis 300 m (grau), 700 m (blau) und Gesamttiefe (violett) von ORAS4, repräsentiert von seinen 5 Ensemble-Gliedern. Die Zeitreihen zeigen monatliche Anomalien, geglättet mit einem über 12 Monate gleitenden Mittel mit Berücksichtigung der Basisperiode 1958 bis 1965. Die Schraffierung geht über die Bandbreite der Ensemble-Glieder hinaus, so dass der Spread eine Angabe hinsichtlich der Ungenauigkeit von ORAS4 ist (der nicht alle Quellen von Unsicherheit abdeckt). Die vertikalen farbigen Balken zeigen ein zweijähriges Intervall, die den Vulkanausbrüchen 6 Monate zuvor folgen (wegen des 12-monatigen gleitenden Mittels) sowie dem El Niño-Ereignis von 1997/98, ebenfalls mit 6 Monaten auf beiden Seiten. Unten rechts wird die lineare Steigung eines Satzes globaler Erwärmungsraten in W/m² gezeigt.
Ich habe mir das angeschaut und gesagt „Waaas???“ Ich habe noch nie derartige vulkanische Signale in den Daten des ozeanischen Wärmegehalts gesehen. Was war mir entgangen?
Nun, mir war entgangen, dass Trenberth et al. etwas benutzen, was sie lächerlicherweise „Reanalyse-Daten“ nennen. Aber wie die Überschrift schon zeigt, Reanalyse-„Daten“ sind keinerlei Daten im Wortsinne. Es handelt sich dabei um das Ergebnis eines Computer-Klimamodells, die als Daten verkleidet werden.
Nun ist der grundlegende Gedanke einer „Reanalyse“ kein schlechter Gedanke. Wenn man Daten mit „Lücken“ darin hat, oder wenn Informationen aus bestimmten Zeiten und/oder an bestimmten Orten fehlen, kann man eine Art „Best Guess“-Algorithmus benutzen, um die Lücken zu füllen. Im Bergbau ist diese Prozedur allgemein üblich. Man hat Einzel-Punkttdaten darüber, was im Untergrund los ist. Also verwendet man eine Kriging-Prozedur mit allen verfügbaren Informationen, und man bekommt den Best Guess [= beste Abschätzung?] darüber, was in den datenfreien Lücken passiert. (Man beachte jedoch: wenn man behauptet, dass die Ergebnisse des Kriging-Modells reale Beobachtungen sind; wenn man sagt dass die Ergebnisse des Kriging-Prozesses „Daten“ sind, kann man wegen Fehlinterpretation ins Gefängnis wandern … aber ich schweife ab, das ist die reale Welt und das ist Klima-„Wissenschaft“ in reinster Form).
Die Probleme tauchen auf, sobald man anfängt, immer komplexere Prozeduren durchzuführen, um die Lücken in den Daten zu füllen. Kriging ist reine Mathematik, und man erhält Fehlerbereiche um die Schätzungen. Aber ein globales Klimamodell ist ein horrend komplexes Erzeugnis und gibt überhaupt keine Fehlerschätzung irgendwelcher Art.
Nun, worauf Steven Mosher mit Stolz hinweist, es sind alles Modelle. Selbst so etwas Einfaches wie
Kraft = Masse mal Beschleunigung
ist ein Modell. In dieser Hinsicht hat Mosher also recht.
Das Problem ist, das es solche und solche Modelle gibt. Einige Modelle wie das Kriging sind gut verstanden und verhalten sich wie erwartet. Wir haben das „Kriging“ genannte Modell analysiert und getestet, bis zu dem Punkt, an dem wir seine Stärken und Schwächen verstanden haben, und wir können es mit vollem Vertrauen verwenden.
Dann gibt es noch eine andere Modellklasse mit sehr unterschiedlichen Charakteristiken. Diese nennt man „iterative“ Modelle. Sie unterscheiden sich von Modellen wie Kriging oder F = M x A, weil sie bei jedem Zeitschritt das vorhergehende Modellergebnis als neue Eingangsgröße für das Modell verwenden. Klimamodelle sind iterative Modelle. Ein Klimamodell beispielsweise beginnt mit dem gegenwärtigen Wetter und sagt voraus, wohin sich das Wetter beim nächsten Zeitschritt entwickeln wird (normalerweise eine halbe Stunde).
Dann wird dieses Ergebnis, die Vorhersage für eine halbe Stunde von jetzt an, als Eingangsgröße für das Klimamodell verwendet, und die nächste halbe Stunde wird berechnet. Man mache das 9000 mal, und man hat ein Jahr Wetter simuliert … waschen, spülen und genügend oft wiederholen, und – voila! Jetzt hat man das Wetter vorhergesagt, von halber Stunde zu halber Stunde, die ganze Zeit bis zum Jahr 2100.
Es gibt zwei sehr, sehr große Probleme bei iterativen Modellen. Der erste ist, dass Fehler dazu tendieren, sich zu akkumulieren. Falls man eine halbe Stunde auch nur ein wenig ungenau berechnet, beginnt die nächste halbe Stunde mit schlechten Daten, so dass die Ergebnisse noch stärker abweichen; und so weiter, bis das Modell vollständig von der Rolle ist. Abbildung 2 zeigt eine Anzahl von Modellläufen des Klimavorhersage-Klimamodells…
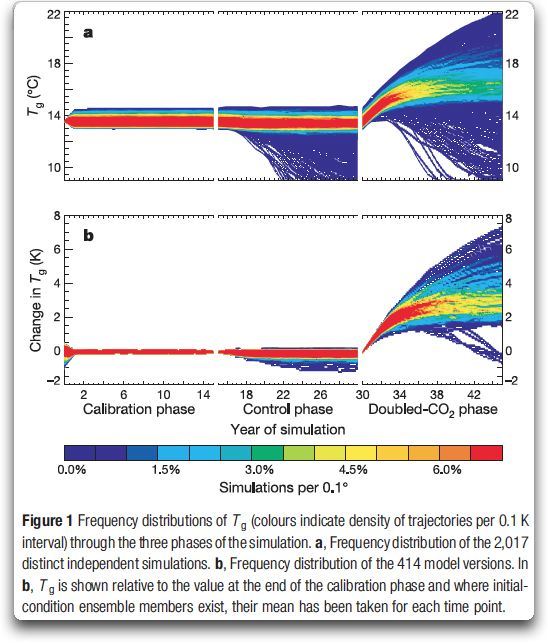
Abbildung 2: Simulationen von www.climateprediction.net. Man beachte, dass eine signifikante Anzahl von Modellläufen weit unter die Eiszeit-Temperaturen zurück gehen… schlechtes Modell, keine Cookies!
Sehen Sie, wie viele der Modellläufe von der Rolle springen und entweder in eine Schneeball-Erde münden oder Temperaturen der Stratosphäre anzeigen? Das ist das Problem der akkumulierten Fehler in Reinform.
Das zweite Problem mit iterativen Modellen besteht darin, dass wir oftmals keine Ahnung haben, wie das Modell zu seiner Antwort gekommen ist. Ein Klimamodell ist so komplex und wird so oft wiederholt, dass die internen Prozesse des Modells oftmals total undurchsichtig sind. Man stelle sich vor, dass man als Ergebnis von drei verschiedenen Modellläufen drei sehr verschiedene Antworten erhält. Wir haben keinerlei Handhabe zu sagen, dass die eine Lösung wahrscheinlicher ist als die andere … außer der einen versuchten und echten Methode, die oft in der Klimawissenschaft verwendet wird, nämlich:
Wenn die Ergebnisse unseren Erwartungen entsprechen, handelt es sich um einen guten, brauchbaren, soliden Goldmodell-Lauf. Und wenn es den Erwartungen nicht entspricht, können wir es offensichtlich mit Sicherheit ignorieren.
Wie viele „schlechte” Reanalyse-Läufe enden also im Abfalleimer, weil der Modellierer das Ergebnis nicht mag? Viele, sehr viele, aber niemand weiß wie viele.
Damit als Einführung schauen wir jetzt auf die Reanalyse-„Daten“ von Trenberth, die natürlich alles andere als Daten sind … Abbildung 3 vergleicht die ORAS4-Reanalyse-Modellergebnisse mit den Levitus-Daten [?]:
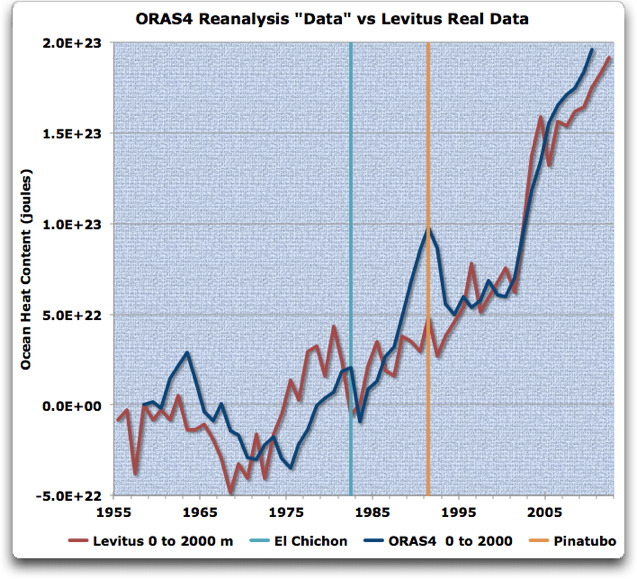
Abbildung 3: ORAS4-Reanalyse-Ergebnisse für die Schicht zwischen 0 und 2000 m (blau) im Vergleich zu den Levitus-Daten für die gleiche Schicht. Die ORAS4-Ergebnisse wurden aus Abbildung 1 digitalisiert. Man beachte, dass die OSAR4-„Daten“ vor etwa dem Jahr 1980 Fehlerbalken vom Boden bis zur Decke haben und daher wenig brauchbar sind (siehe Abbildung 1). Die Daten sind an ihren Startpunkt 1958 angeglichen (1958 = 0)
In Abbildung 3 treten die Schwächen des Reanalyse-Modells klar hervor. Die Computermodelle sagen einen großen Rückgang des OHC durch Vulkane voraus… was offensichtlich nicht geschehen ist. Aber anstatt diese Realität keiner OHC-Änderung nach den Ausbrüchen einzubringen, hat sich das Reanalyse-Modell die Daten einfach zurecht gebogen, so dass es nun den vermeintlichen Rückgang nach den Eruptionen zeigen konnte.
Und das ist das zugrunde liegende Problem, wenn man Reanalyse-Daten wie reale Daten behandelt – sie sind nichts dergleichen. Alles, was das Reanalyse-Modell tut ist, den effektivsten Weg zu finden, die Daten so zu verändern, dass sie den Phantasien, den Vorerwartungen und den Fehlern der Modellierer entsprechen. Hier möchte ich noch einmal den Plot zeigen, den ich schon in meinem vorigen Beitrag gezeigt habe. Dieser zeigt alle Arten der verschiedenen Messungen der Ozeantemperatur, von der Oberfläche bis hinab zu den tiefsten Tiefen, die wir extensiv vermessen haben, zwei Kilometer tief.
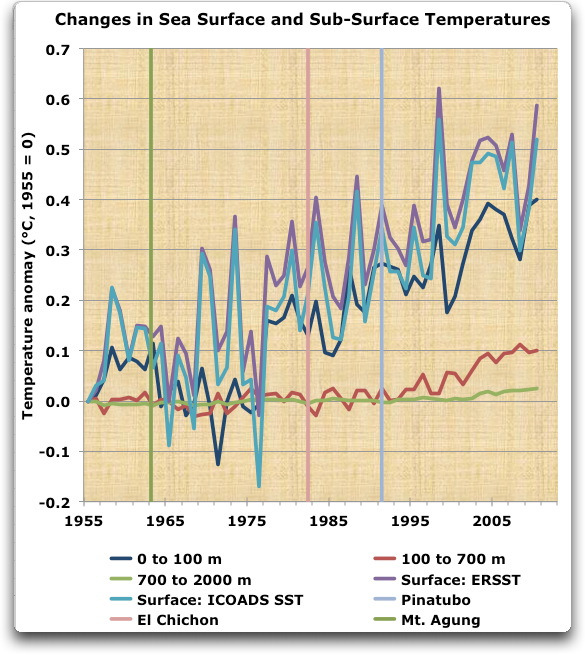
Abbildung 4: Messungen der ozeanischen Temperaturen. Es gibt zwei Messungen an der Oberfläche, nämlich von ERSST und ICOADS, zusammen mit individuellen Schicht-Messungen für drei separate Schichten von Levitus. ACHTUNG! Abbildung 4 ist aktualisiert worden, nachdem Bob Tisdale darauf hingewiesen hatte, dass ich aus Versehen geglättete Daten für die Oberflächentemperaturen verwendet hatte.
Was mich angeht – jeder, der Abbildung 4 betrachtet und dann behauptet, dass man die Auswirkungen der Eruptionen des Pinatubo und des El Chichon sowie des Agung in diesen tatsächlichen Daten erkennen kann, halluziniert. Es gibt keinen sichtbaren Effekt. Ja, es gibt einen Rückgang der SST im Jahr nach Pinatubo … aber die voran gegangenen beiden Rückgänge waren größer, und es gibt keinen Rückgang im Jahr nach El Chichon oder Agung. Außerdem waren die Temperaturen in den beiden Jahren vor Pinatubo stärker gestiegen als sie danach zurückgegangen sind. Nimmt man all das zusammen, sagt es mir, dass es nicht einmal den Hauch einer Chance gibt, dass Pinatubo einen kleinen Rückgang nach sich gezogen hätte.
Aber die armen Klimamodellierer sind gefangen. Die einzige Möglichkeit, dass sie behaupten können CO2 werde zum befürchteten Thermageddon besteht darin, die Klimasensitivität sehr hoch anzusetzen.
Das Problem ist Folgendes: wenn die Modellierer eine sehr hohe Sensitivität ansetzen wie 3°C pro Verdoppelung des CO2-Gehaltes, führt das zu einer starken Überschätzung der Auswirkungen durch Vulkanausbrüche. Man kann dies eindeutig in Abbildung 3 erkennen, die die Reanalyse-Modellergebnisse zeigt, die Trenberth trügerisch „Daten“ nennt. Verwendet man das berühmte Bett des Procustes [?] als das zugehörige Beispiel, hat das Modell einfach die realen Daten modifiziert und angepasst, um den Phantasien der Modellierer hinsichtlich einer hohen Klima-Sensitivität gerecht zu werden. Kurz gesagt, das Reanalyse-Modell hat die realen Daten einfach so lange vermischt, bis sie die starken Rückgänge nach den Ausbrüchen zeigen … und das soll Wissenschaft sein?
Aber bedeutet das jetzt, dass alle Reanalyse-„Daten“ Schwindel sind?
Nun, das wirkliche Problem ist, dass wir auf diese Frage die Antwort nicht kennen. Die Schwierigkeit ist, dass es wahrscheinlich erscheint, dass einige der Reanalyse-Ergebnisse gut sind und andere nutzlos, aber im Allgemeinen haben wir keine Möglichkeit, zwischen den beiden zu unterscheiden. Dieser Fall von Levitus et al. ist eine Ausnahme, weil die Vulkane das Problem haben hervor treten lassen. Aber in vielen Anwendungen von Reanalyse-„Daten“ gibt es keine Möglichkeit zu erkennen, ob sie gültig sind oder nicht.
Und wie Trenberth et al. bewiesen haben, können wir uns definitiv nicht von Wissenschaftlern abhängig machen, die die Reanalyse-„Daten“ verwenden, um auch nur den Hauch einer Andeutung einer Untersuchung zu machen, ob sie gültig sind oder nicht …
(Übrigens, lassen Sie mich einen Grund nennen, warum Klimamodelle sich mit Reanalysen schwertun – die Natur weist allgemein Ecken und Kanten auf, während die Klimamodelle allgemein Glättungsverfahren durchführen. Ich habe einen großen Teil meines Lebens auf dem Ozean verbracht. Ich kann versichern, dass man selbst mitten auf dem Ozean oft eine ausgeprägte Linie zwischen zwei verschiedenen Wasserarten erkennt, wobei die eine signifikant wärmer ist als die andere. Wolken haben ausgeprägte Kanten, und sie bilden sich und vergehen wieder ohne viel „dazwischen“. Der Computer ist nicht sehr gut in der Verarbeitung dieses Ecken-und-Kanten-Zeugs. Wenn man es dem Computer überlässt, die Lücke zwischen zwei Beobachtungen zu füllen, sagen wir 10°C und 15°C, kann der Computer das perfekt – wird es aber generell graduell und glatt machen, also 10, 11, 12, 13, 14, 15.
Aber wenn die Natur diese Lücke füllt, ist es viel wahrscheinlicher, dass es so aussieht: 10, 10, 10, 14, 15, 15 … die Natur macht zumeist nichts „graduell“. Aber ich schweife ab…)
Heißt das, dass wir niemals Reanalysen benutzen sollten? Nein, keinesfalls. Kriging ist ein exzellentes Beispiel eines Typs von Reanalyse, der wirklich wertvoll ist.
Was diese Ergebnisse wirklich bedeuten: Wir sollten aufhören, die Ergebnisse von Reanalyse-Modellen „Daten“ zu nennen, und wir sollten DIE REANALYSE-MODELLERGEBNISSE EXTENSIV TESTEN, bevor wir sie verwenden. [Blockschrift im Original]
Diese Ergebnisse bedeuten auch, dass man extrem vorsichtig sein sollte, wenn Reanalyse-„Daten“ als Eingabegrößen für ein Klimamodell verwendet werden. Wenn man das tut, benutzt man die Ergebnisse eines Klimamodells als Eingabegrößen für ein anderes Klimamodell … was allgemein eine Very Bad Idea™ aus einer ganzen Reihe von Gründen ist.
Außerdem sollte man in allen Fällen, in denen man Reanalyse-Ergebnisse verwendet, genau die gleiche Analyse unter Verwendung der realen Daten durchführen. Das habe ich in Abbildung 3 oben getan. Hätten Trenberth et al. diese Graphik zusammen mit ihren Ergebnissen gezeigt … nun … falls sie das getan hätten, wäre ihre Studie wahrscheinlich überhaupt nicht veröffentlicht worden.
Was vielleicht der Grund gewesen sein könnte oder auch nicht, diese vergleichende Analyse nicht zu präsentieren, und warum sie versucht haben zu behaupten, dass die Ergebnisse von Computer-Modellen „Daten“ sind…
Willis Eschenbach
Anmerkung: Die Studie von Trenberth et al. identifiziert als tiefste Schicht als von der Oberfläche bis in die „totale Tiefe“ reichend. Allerdings zeigt die Reanalyse keinerlei Änderungen unter 2000 m, so dass dies ihre „totale Tiefe“ ist.
DATEN:
The data is from NOAA , except the ERSST and HadISST data, which are from KNMI.
The NOAA ocean depth data is here.
The R code to extract and calculate the volumes for the various Levitus layers is here.
Link: http://wattsupwiththat.com/2013/05/10/why-reanalysis-data-isnt-2/
Übersetzt von Chris Frey EIKE